



II. Partie 2 - Les raisonnements de la méthode Merise : conception du Système d'Information Organisationnel (SIO)▲
II-A. Préambule▲
La première partie a présenté les principes généraux et les fondements théoriques de la méthode Merise, ainsi que les types de systèmes d'information pour lesquels elle est plus particulièrement adaptée.
Cette deuxième partie traite des raisonnements mis en œuvre par le concepteur pour l'élaboration des modèles nécessaires à la compréhension et à la conception du système d'information organisationnel (SIO).
Elle précise comment élaborer et exprimer les différents modèles de données et de traitements de niveau conceptuel et organisationnel qui spécifient ce SIO. Cette partie se compose des chapitres suivants :
- chapitre 5 : découpage en domaines et analyse des flux ;
- chapitre 6 : modélisation conceptuelle des traitements ;
- chapitre 7 : modélisation conceptuelle des données ;
- chapitre 8 : modélisation organisationnelle des traitements ;
- chapitre 9 : cycle de vie des objets et objets métier ;
- chapitre 10 : modélisation organisationnelle des données ;
- chapitre 11 : confrontation données/traitements.
Notons que dans cette partie, la présentation des différents modèles associés au SIO concerne essentiellement la dimension du cycle d'abstraction de la méthode (les raisonnements). Cette présentation est faite sans référence aux autres dimensions de la méthode : les cycles de vie et de décision.
Une telle démarche est théorique et n'a de justification que pédagogique.
Dans la pratique, comme nous le verrons dans la quatrième partie de l'ouvrage, le parcours du cycle d'abstraction devra toujours se situer par rapport à une étape du cycle de vie, en particulier les études préalable, détaillée ou technique.
II-B. Chapitre 5 Découpage en domaines et analyse des flux▲
II-B-1. Découpage en domaines▲
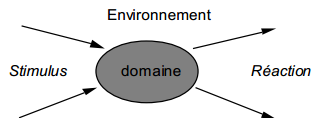
L'analyse systémique nous a fourni une modélisation de l'entreprise échangeant et transformant des flux (cf. chapitre 2Chapitre 2 Les principes fondamentaux de Merise). L'approche par les niveaux de complexité nous a montré que l'entreprise-système, dès le niveau 7, résultait d'une fédération de processeurs actifs élémentaires coordonnés : le système opérant. Le système d'information est la représentation de l'activité de ce système opérant.
Cette vision unitaire d'un système d'information général, même si elle traduit justement la complexité et les interdépendances internes d'un tel système, est difficilement exploitable ; il faudrait aborder l'informatisation du système d'information d'une entreprise d'un seul tenant…
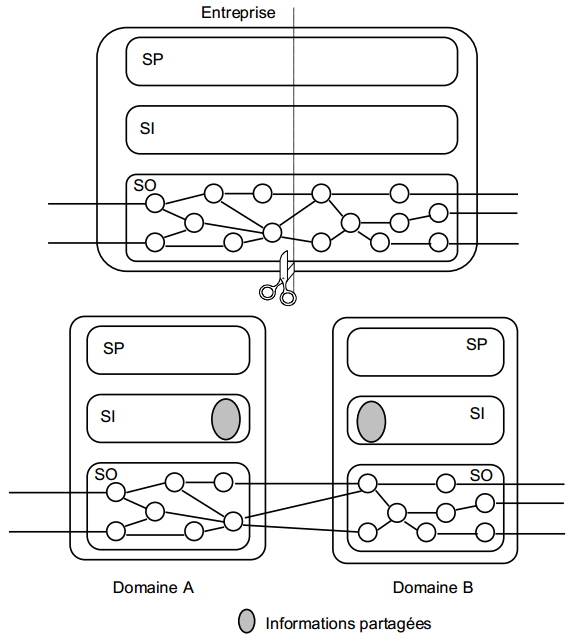
Pour tenter de réduire la complexité de modélisation d'une entreprise, et surtout pour obtenir des tailles de projet maîtrisables, on cherche à découper l'entreprise en domaines d'activité (voir figure 5.1). Ce découpage s'effectue généralement sur la base des grandes fonctions ou activités de cet organisme : vendre, stocker, acheter, gérer du personnel, etc.
Chaque domaine est considéré comme « quasi autonome » avec son propre système opérant, son propre système de pilotage et son propre système d'information. Le système d'information général de l'entreprise n'est alors défini que comme la réunion des systèmes d'information de chaque domaine.
Ce découpage s'opère généralement au regard des activités du système opérant et/ou des finalités du système de pilotage. Cependant, les systèmes d'information résultant du découpage en domaines ne sont pas disjoints. Comme ils entretiennent entre eux des flux et qu'ils partagent des perceptions sur l'environnement, certaines représentations figurent dans plusieurs systèmes d'information. Il faudra alors être vigilant à la cohérence interdomaine.
Ce délicat problème de découpage en domaines, apparaissant comme prérequis à l'informatisation d'un système d'information, est normalement abordé, dans la démarche de la méthode, lors du schéma directeur. Toutefois, en pratique, un tel schéma est souvent absent, ou ne comporte pas de découpage en domaines.
En conséquence, le concepteur doit, dans la première phase de l'étude préalable, procéder à la délimitation du domaine dont il va élaborer le système d'information informatisé. Pour ce faire, il peut utiliser la technique d'analyse des flux.
II-B-2. Analyse des flux▲
L'approche systémique évoquée précédemment nous suggère d'analyser le système opérant de l'entreprise comme un ensemble coordonné d'« unités actives » échangeant des flux entre elles, avec le système de pilotage et l'environnement. L'analyse des flux permet d'appréhender simplement le fonctionnement global de l'entreprise, en se focalisant éventuellement sur un ensemble d'activités concernées par l'étude, sans chercher à identifier l'origine et la stabilité de ce découpage en unités actives ; la prise en compte des niveaux d'abstraction (conceptuel, organisationnel, logique, physique) s'effectuera dans les autres modèles.
II-B-2-a. Acteurs et flux▲
L'analyse des flux s'exprime avec deux concepts : l'acteur et le flux.
II-B-2-b. L'acteur▲
L'acteur représente une unité active intervenant dans le fonctionnement du système opérant. Stimulé par des flux, il les transforme, les renvoie ; un acteur « fait quelque chose », il est actif.
Dans la pratique, un acteur peut modéliser :
- un partenaire extérieur à l'entreprise (client, fournisseur…) ;
- un domaine d'activité de l'entreprise précédemment identifié (la comptabilité, la gestion du personnel…) ;
- un ensemble d'activités ou processus (liquidation, contrôle…) ;
- un élément structurel de l'entreprise (service, unité géographique, unité fonctionnelle…) ;
- le système de pilotage, ou pilote, dans ses interactions avec le système opérant ou le système d'information.
II-B-2-c. Le flux▲
Le flux représente un échange entre deux acteurs. Les flux peuvent être classés en cinq catégories :
- Matière (qui est transformée ou consommée).
- Finance.
- Personnel.
- Actif (matériel ou savoir-faire nécessaire pour exercer l'activité).
- Information.
Un flux est émis par un acteur à destination d'un autre acteur.
Dans l'utilisation de l'analyse des flux par la méthode Merise, on s'intéressera principalement aux flux d'informations. Les autres types de flux qui présenteraient un intérêt majeur devront donc être explicités en flux d'informations (information-représentation).
Dans l'utilisation de l'analyse des flux par la méthode Merise, conformément à l'analyse séparée données/traitements, nous ne représentons pas les flux entre un acteur et la mémoire ; un fichier n'est pas modélisé comme un acteur, bien qu'il subisse des échanges d'informations. Si l'on souhaite faire apparaître de tels échanges, nous suggérons de faire appel à un troisième type de concept qui s'apparenterait au « dépôt de données » des formalismes Diagrammes de flux de données de l'analyse structurée [Gane & Sarson 79].
II-B-2-d. Diagramme des flux▲
C'est une représentation graphique (une « cartographie ») des acteurs et des flux échangés.
En l'absence de norme d'usage de symbolisation, les acteurs peuvent parfois être représentés par différents symboles selon leur nature : partenaire extérieur, domaine, processus, unité organisationnelle…
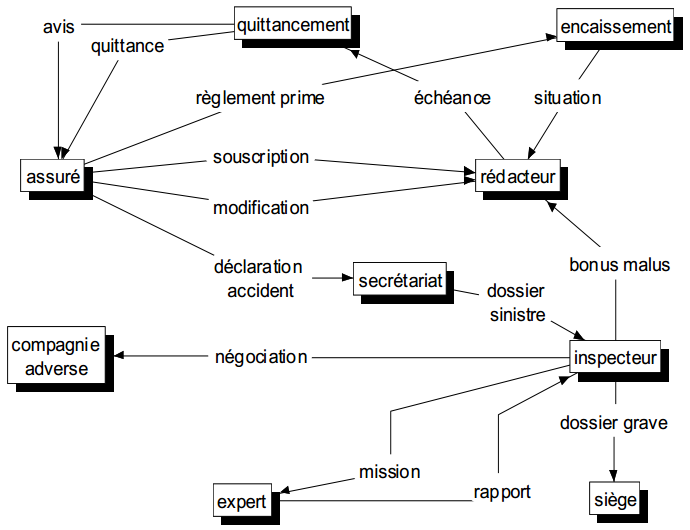
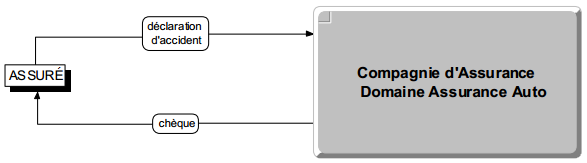
Le flux est représenté par un lien orienté (fléché) ; le nom du flux étant porté par ce lien. Un diagramme des flux, s'inspirant d'un thème sur l'assurance automobile et que nous retrouverons tout au long des différentes modélisations, est présenté figure 5.2.
L'aspect visuel et la simplicité du symbolisme font du diagramme des flux un support efficace pour le dialogue avec l'utilisateur, en particulier lors des premiers entretiens.
Pour préserver la lisibilité de tels diagrammes et éviter de trop nombreux croisements, on peut « dupliquer » les symboles de certains acteurs.
Le diagramme des flux peut parfois, dans la phase de l'analyse de l'existant (cf. partie IV), se substituer au modèle organisationnel des traitements actuel dans le cas où les aspects organisationnels sont simples ou limités.
II-B-2-e. Matrice des flux▲
C'est une représentation matricielle des acteurs et des flux échangés.
Les acteurs forment les lignes et colonnes du tableau. Situé en ligne, l'acteur a un rôle d'émetteur de flux ; situé en colonne, il a un rôle de destinataire de flux.
Les flux sont indiqués dans les « cases » du tableau de la figure 5.3, à l'intersection de la ligne de l'acteur-émetteur et de la colonne de l'acteur-destinataire.
La matrice des flux est plutôt destinée à l'usage du concepteur pour recenser les flux d'une manière systématique, en s'interrogeant à chaque case.
|
de \ vers |
assuré |
cie adverse |
quittancement |
encaissement |
rédacteur |
secrétariat |
inspecteur |
expert |
siège |
|---|---|---|---|---|---|---|---|---|---|
|
assuré |
règlement prime |
souscription modification |
déclaration |
||||||
|
cie adverse |
|||||||||
|
quittancement |
quittance devis |
||||||||
|
encaissement |
situation |
||||||||
|
rédacteur |
échéance |
||||||||
|
secrétariat |
dossier |
||||||||
|
inspecteur |
négociation |
mission |
dossier grave |
||||||
|
expert |
rapport |
||||||||
|
siège |
II-B-3. Utilisation de l'analyse des flux pour le découpage en domaines▲
II-B-3-a. Diagramme brut des flux ▲
Ce diagramme est élaboré lors des premières interviews ; le concepteur découvre le champ de l'étude et va utiliser l'analyse des flux pour débroussailler le domaine. La notion d'acteur s'applique à toute unité active ; le diagramme des flux ressemble à celui de la figure 5.2.
La visualisation des acteurs et des flux permet alors au concepteur de regrouper les différentes unités actives qui constitueront le domaine d'activité étudié. On met ainsi en évidence deux frontières qui permettent de répartir les acteurs :
- l'entreprise ;
- le domaine étudié.
On peut également percevoir certains acteurs comme l'expression d'autres domaines par ailleurs définis, ou regrouper des acteurs extérieurs au domaine étudié qui peuvent être considérés comme des domaines potentiels.
On peut faire figurer ces frontières et regroupements sur un diagramme des flux (voir figure 5.4) ; on s'efforcera alors de mettre en évidence le domaine étudié.
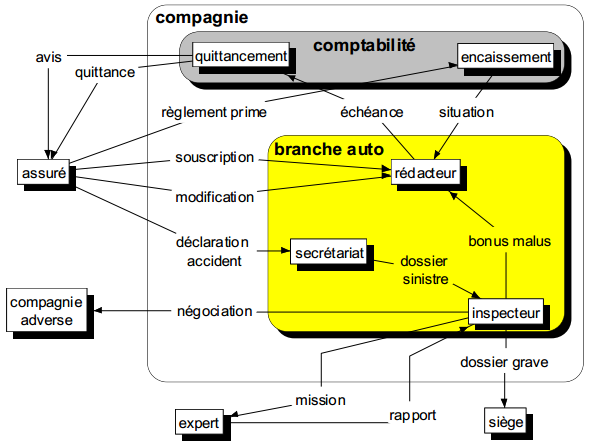
II-B-3-b. Acteurs internes, acteurs externes, domaines▲
L'établissement de la frontière du domaine induit une distinction entre les acteurs internes et les acteurs externes au domaine étudié.
Les acteurs internes traduisent fréquemment une répartition des activités, au sein du domaine, selon des choix d'organisation. Ultérieurement, nous verrons que l'abstraction nécessaire à la modélisation conceptuelle des traitements nous conduira à ne plus prendre en compte ces acteurs internes. Ils réapparaîtront éventuellement lors de la modélisation organisationnelle des traitements sous la forme de postes. En résumé, les acteurs internes n'ont qu'une existence éphémère et limitée à l'analyse des flux.
Les acteurs externes conservent une importance capitale dans l'étude et la modélisation du système d'information. Le domaine (vu comme système ouvert) ne « vivra » qu'avec ses échanges avec les acteurs externes. Les flux qu'ils émettent vont être des stimuli déclenchant l'activité du domaine ; les flux qu'ils reçoivent sont les réponses des activités du domaine. Ces flux entre les acteurs externes et le domaine sont un des éléments stables que nous recherchons pour la conception d'un système d'information.
Certains de ces acteurs externes représentent souvent d'autres domaines de l'entreprise, l'étude engagée étant rarement la première pour l'informatisation des systèmes d'information. Si ces domaines sont explicitement déterminés, il est préférable de les identifier et de les représenter en tant que tels sur le diagramme des flux. En effet, les flux interdomaines mis ainsi en évidence contribuent très tôt au maintien de la cohérence interdomaine et à la détermination des futures interfaces.
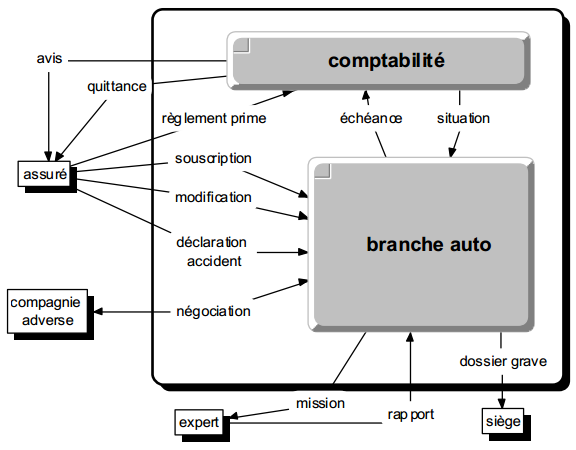
II-B-4. Diagramme conceptuel des flux ▲
À la différence du diagramme brut des flux présenté précédemment, le diagramme conceptuel des flux (voir figure 5.5) tient compte des conséquences de la détermination du domaine. N'apparaîtront sur un tel diagramme que :
- le domaine étudié ;
- les acteurs externes ;
- les autres domaines.
Un tel diagramme peut ainsi avoir une existence plus permanente que le diagramme brut des flux, s'enrichir régulièrement et représenter l'articulation générale des systèmes d'information. En conséquence, au fur et à mesure de l'étude des systèmes d'information de l'entreprise, les acteurs externes ne représenteront plus que des acteurs extérieurs à l'entreprise.
Notons que ce diagramme conceptuel des flux est également désigné comme diagramme des flux contextuel du domaine et qu'il correspond aussi globalement au modèle conceptuel de communication proposé dans certaines versions de la. méthode Merise.
II-C. Chapitre 6 Modélisation conceptuelle des traitements▲
II-C-1. Considérations méthodologiques▲
II-C-1-a. Notions de traitement dans Merise▲
Il importe d'abord de lever une ambiguïté sur la compréhension du terme traitement. Qu'il provienne des premières approches de l'informatique ou de l'informatique scientifique et technique, le terme traitement a été souvent limité à la seule transformation de données (voir figure 6.1).
Décrire le traitement revient alors à décrire l'algorithme (organigramme, arbre programmatique…).

Dans Merise, le terme traitement est plus général ; il s'assimile au fonctionnement du système d'information perçu à travers ses couplages avec le système opérant et le système de pilotage. Décrire les traitements, c'est décrire les processus mis en œuvre dans le domaine (vu comme un système) en interaction avec son environnement (voir figure 6.2).
II-C-2. Problématique de la modélisation conceptuelle des traitements▲
La modélisation conceptuelle des traitements a pour objectif de représenter formellement les activités exercées par le domaine, activités dont la connaissance est la base du système d'information. Elle est tournée vers la prise en compte des échanges du domaine avec son environnement (autres domaines, extérieur de l'entreprise, système de pilotage). C'est avant tout l'identification de ces échanges et des activités induites qui va contraindre et structurer le fonctionnement du domaine.
La modélisation de ces activités s'effectue en faisant abstraction de l'organisation, c'est-à-dire des moyens et ressources nécessaires à l'exécution de ces activités. Un modèle conceptuel de traitements (MCT) exprime ce que fait le domaine, et non par qui, quand, où et comment ces activités sont réalisées.
Dans ses principes généraux, la méthode Merise lie les niveaux de préoccupation aux degrés de stabilité. Au niveau conceptuel des traitements, cette stabilité se traduit par les flux échangés et les activités associées ; la définition des interactions du domaine avec son environnement prime sur la manière dont s'exerceront ces activités.
L'élaboration d'un MCT permet ainsi de préciser les frontières du domaine en décrivant les activités qui lui sont associées et les échanges avec son environnement. Son utilisation dans la démarche viendra d'ailleurs le confirmer.
II-C-3. Formalisme de modélisation des traitements▲
La modélisation des traitements dans la méthode Merise s'exprime dans un formalisme spécifique [Heckenroth, Tardieu, Espinasse 80] [Tardieu, Rochfeld, Coletti 83], élaboré pour permettre de représenter le fonctionnement d'activités aux différents niveaux de préoccupations (conceptuel, organisationnel, logique, physique). Il conserve ainsi une unicité de structure qui évite la multiplication des formalismes. L'adaptation aux différents niveaux se fait par la dénomination des concepts types. Ce formalisme propose une représentation graphique destinée à faciliter le dialogue entre concepteur et utilisateur.
Il repose sur des bases théoriques solides permettant une vérification formelle des modèles, dans la mesure où il s'inspire du formalisme des réseaux de Pétri [Brams 83] [Techniques et sciences informatiques 85]. Il permet une simulation de l'activité du système d'information : fonctionnement pas-à-pas, mise en évidence de conflits et parallélismes.
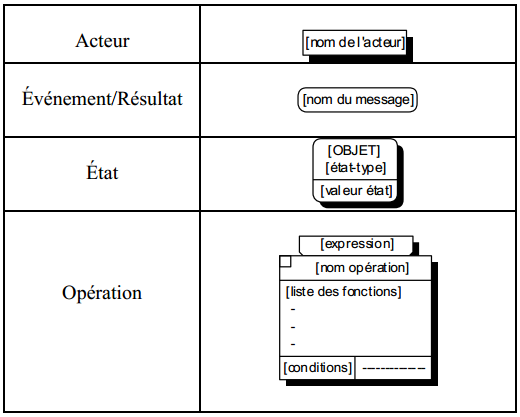
Pour décrire le niveau conceptuel, le formalisme des traitements comporte les concepts suivants :
- L'acteur.
- L'événement/résultat-message.
- L'état.
- L'opération.
II-C-3-a. L'acteur ▲
Comme nous l'avons déjà vu plus haut, le modèle conceptuel de traitements (MCT) formalise d'abord les activités du domaine consécutives aux échanges avec l'environnement. Les acteurs pris en compte dans un MCT sont donc uniquement les acteurs externes au domaine (à l'exception du système de pilotage). Les acteurs internes au domaine mis en évidence dans l'analyse des flux traduisent un découpage organisationnel dont on doit faire abstraction au niveau conceptuel.
L'acteur est formalisé graphiquement de la façon suivante :

II-C-3-b. L'événement/résultat-message ▲
Les flux reçus (stimuli) et émis (réactions) par le domaine sont respectivement modélisés en événements et résultats (voir figure 6.3). Un événement est la formalisation d'un stimulus par lequel le domaine, puis son système d'information, prend connaissance de comportements de son environnement (interne ou externe à l'entreprise). Un événement est donc émis par un acteur à destination du domaine. Un résultat est la formalisation d'une réaction du domaine et de son système d'information. Un résultat est donc émis par une activité du domaine à destination d'un acteur.
On distingue plusieurs catégories d'événements/résultats :
- Externes, modélisant des flux avec un acteur.
- Décisionnels, représentant les échanges avec le système de pilotage.
- Temporels, représentant des échéances.
Ces deux dernières catégories seront plus particulièrement utilisées dans la modélisation organisationnelle des traitements (Chapitre 8Chapitre 8 Modélisation organisationnelle des traitements).
Seuls les événements et résultats externes traduisent des échanges avec l'environnement du domaine et constituent de « vrais » événements et résultats.
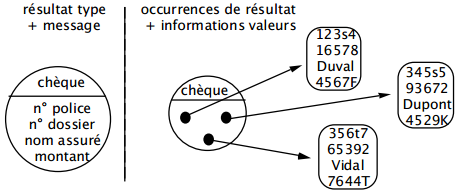
Ces événements et résultats, pour être acceptés par le système, sont regroupés, modélisés en types. Par exemple, la déclaration de M. Dupont du 13/01 et la déclaration de M. Martin du 15/02 peuvent être considérées comme deux occurrences de l'événement type déclaration d'accident. De même, trois chèques émis par la compagnie d'assurance à destination d'assurés constituent trois occurrences d'un même résultat type (figure 6.4).
Dans un MCT, on ne représente que des types d'événements et de résultats.
À un événement ou résultat est éventuellement associé un ensemble d'informations appelé message. Un message est un ensemble structuré d'informations décrivant un événement/résultat type (figure 6.4). Une occurrence d'événement/résultat doit être distinguable des autres par le contenu de son message associé, ainsi que par l'instant et l'endroit où il se produit.
Il faut parfois faire la distinction entre le message et son support. Par exemple, un dossier qui s'enrichit au fur et à mesure des activités représente différents messages successifs sur un même support.
II-C-3-c. L'état▲
Cette notion a été introduite dans la modélisation des traitements avec la deuxième génération. L'état modélise une situation du système d'information.
Dans la description du fonctionnement des activités d'un domaine, le concepteur peut constater que l'exécution de certaines activités d'une part dépend d'une situation préalable du système d'information (un dossier doit être ouvert avant d'instruire le sinistre), d'autre part peut produire des changements d'état (après le règlement du sinistre, le dossier est clos).
L'état peut s'exprimer par :
- une valeur prise par une information (statut dossier = en cours) ;
- le fait qu'une activité a été réalisée (calcul des pénalités effectué) ;
- une règle de traitement (délai de règlement dépassé de 15 j.).
Ces situations ou états du système d'information qui conditionnent le fonctionnement des activités doivent être mémorisés. On peut envisager trois solutions :
- Le fonctionnement du système d'information est sous la surveillance d'un « moniteur », véritable système d'information sur le fonctionnement du système d'information qui prend acte des activités réalisées et des états obtenus, et autorise ou interdit certaines activités conditionnées par des états.
- La mémorisation des états est prise en charge dans les traitements.
- La mémorisation des états est traduite dans les données par des informations spécifiques (par exemple, statut du dossier).
Compte tenu des possibilités actuelles d'implémentation technique, la mémorisation des états relève généralement de la troisième solution. En conséquence, la notion d'état s'applique essentiellement à des objets et associations entre objets modélisés dans les données. La prise en compte des états dans la modélisation des traitements établit ainsi un lien avec la modélisation des données.
Pour la description d'un état d'un objet de données, on précisera :
- le nom de l'objet ;
- le nom de l'information décrivant le type d'état ;
- la valeur de l'état ;
- éventuellement la règle permettant de déterminer l'état.
L'état est formalisé graphiquement de la façon suivante :

Dans la modélisation conceptuelle des traitements, les états ont un rôle vis-à-vis des activités assez proche de celui des événements et résultats. Comme un événement, un état est une condition préalable à l'exécution d'une opération ; comme un résultat, un état est la conséquence conditionnelle d'une opération. Cela explique pourquoi, dans le passé, les états ont été modélisés comme des événements, qualifiés d'internes.
II-C-3-d. L'opération ▲
L'opération est la description du comportement du domaine et de son système d'information par rapport aux événements types. Elle est déclenchée par la survenance d'un (ou plusieurs) événement(s) et/ou d'un (ou plusieurs) état(s) synchronisé(s). L'opération comprend l'ensemble des activités que le domaine peut effectuer à partir des informations fournies par l'événement et de celles déjà connues dans la mémoire du système d'information.
La segmentation en plusieurs opérations ne se justifie que par l'attente d'informations complémentaires en provenance d'événements nécessaires à la poursuite des activités.
II-C-3-e. Synchronisation▲
La synchronisation représente une condition de présence d'événements et/ou d'états préalables au démarrage de l'opération.
Elle se traduit par une expression logique s'appliquant sur la présence (ou l'absence) des occurrences des événements et/ou des états. L'expression logique de la synchronisation utilise les opérateurs classiques ET, OU, NON, ou toute combinaison admise par la logique.
Si la condition est vérifiée, l'opération peut démarrer et les occurrences déclencheuses (ainsi que les messages associés) sont considérées comme consommées par l'opération. Si la condition n'est pas vérifiée, la synchronisation et les occurrences d'événements présents restent en attente jusqu'à ce qu'elle soit vérifiée.
II-C-3-f. Description d'une opération▲
L'opération est décrite par un ensemble d'activités ou fonctions élémentaires à assurer et peut comporter :
- des décisions ;
- des règles de gestion ;
- des actions sur les données mémorisées ;
- des traitements sur les données ;
- des actions quelconques.
Certains auteurs désignent le contenu d'une opération par tâches. Nous réserverons l'appellation tâche au niveau organisationnel, même si les fonctions décrites deviennent éventuellement des tâches dans le modèle organisationnel des traitements (MOT). Au niveau normal de modélisation des opérations d'un MCT, il n'est pas nécessaire de représenter explicitement les actions sur les données mémorisées et les règles de traitement ou de gestion. Cependant, dans un MCT analytique (voir « Modularité des modèles conceptuels de traitement »), les actions sur les données seront explicitement formalisées par la notion de sous-schéma, ainsi que les règles de traitement. Ces concepts sont présentés dans le chapitre « Modélisation organisationnelle des traitementsChapitre 8 Modélisation organisationnelle des traitements ».
L'ordre dans lequel les fonctions sont présentées au sein de l'opération n'est pas significatif ; ces fonctions expriment l'ensemble des activités réalisables à partir de la survenance de l'événement. Le passage au MOT permettra ultérieurement d'organiser ces activités en termes de tâches.
II-C-3-g. Conditions d'émission▲
L'opération produit des résultats et/ou des états. L'émission de ces résultats et/ou états est soumise à des conditions traduites par des expressions logiques.
Bien que représentée graphiquement dans la partie inférieure de l'opération, une condition peut être vérifiée à partir de toute fonction de l'opération. La présence d'une condition (un test) dans le déroulement d'activités consécutives à un ou plusieurs événements ne justifie pas, au niveau conceptuel, la segmentation en différentes opérations.
Plusieurs résultats de nature et destination différentes, ainsi que plusieurs états d'objets ou d'états types différents, peuvent être émis par une même condition.
II-C-3-h. Le processus▲
Le processus est un ensemble structuré d'événements, opérations et résultats consécutifs qui concourent à un même but. Il représente généralement un sous-ensemble d'activités de l'entreprise dont les événements initiaux et les résultats finaux délimitent un état stable du domaine.
Par exemple, dans le domaine assurance auto, on pourrait distinguer trois processus :
- La prospection.
- La gestion des contrats.
- La gestion des sinistres.
L'analyse en termes de processus est une vision macroscopique des activités du domaine que l'on pourra modéliser spécifiquement, comme nous le verrons plus loin (voir « Modularité des modèles conceptuels de traitement »).
II-C-3-i. Notions complémentaires pour la formalisation conceptuelle des traitements▲
Les concepts de base présentés suffisent généralement pour construire un modèle conceptuel de traitements. Toutefois, certaines situations à modéliser rendent nécessaires des éléments complémentaires tels que :
- La durée de l'opération, temps passé entre le déclenchement de l'opération et la production de résultat. Cette durée peut être variable suivant les conditions d'émission des résultats. Rarement utilisée.
- La duplication d'un résultat, nombre d'occurrences identiques d'un résultat émis par une opération. Par défaut, cette valeur est 1.
- La participation d'un événement à une synchronisation, nombre d'occurrences différentes de l'événement nécessaires au déclenchement de la synchronisation. Par défaut cette valeur est 1, une valeur typique est tous.
II-C-3-j. Un exemple▲
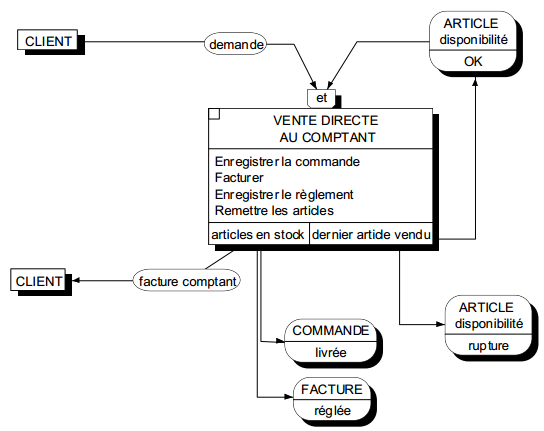
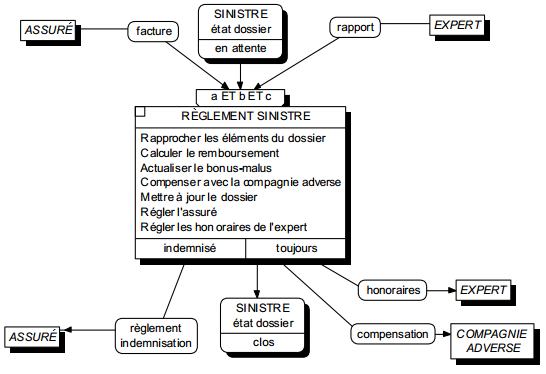
La figure 6.6 montre un exemple de modélisation conceptuelle de traitements représentant le processus de gestion d'une déclaration amiable d'accident.
On remarquera la double modélisation dans le cas d'un accident considéré comme trop grave : la transmission du dossier grave au siège modélisé comme un message (flux), l'indication dans le système d'information que le dossier a été transmis, modélisé comme un état.
II-C-4. Règles de vérification▲
Comme tout modèle, un MCT doit représenter fidèlement le système étudié, actuel ou futur :
- dans sa description (choix des acteurs, des opérations, des événements-résultats) ;
- dans son fonctionnement (fonctionnement répétitif sans blocage, dans les différents cas de figure possibles, bonne circulation des occurrences d'événements et de résultats).
La description, tout à fait essentielle, sera validée par les gestionnaires et les futurs utilisateurs du domaine, au cours de présentations prévues à cet effet. Le fonctionnement correct du MCT peut être apprécié par une simulation manuelle.
Description et fonctionnement sont plus faciles à vérifier, lorsque le MCT respecte quelques règles simples de syntaxe.
II-C-4-a. Règles de syntaxe▲
- Un acteur émet au moins un événement, ou reçoit au moins un résultat.
- Un événement externe provient d'au moins un acteur.
- Un résultat provient d'au moins une opération.
- Tout résultat a au moins une destination : acteur ou opération.
- Une opération est déclenchée soit directement par un événement ou un état, soit par une synchronisation unique.
- Une synchronisation lie au moins deux événements ou états par une expression logique.
- Une expression logique associée à une synchronisation ou à l'émission d'un résultat ne peut être toujours fausse ; il doit y avoir au moins une situation où cette expression logique est vraie, sinon l'opération ne sera jamais déclenchée, ou le résultat jamais émis.
Les règles a, b et e imposent la fermeture du modèle sur les acteurs :
- Le MCT ne vit que par ses échanges avec l'environnement.
- Les événements externes ne naissent pas spontanément.
- Les résultats produits sont utilisés.
II-C-4-b. Règles de fonctionnement▲
Nous retiendrons ici trois règles simples :
Un fonctionnement cyclique doit pouvoir être contrôlé.
Il y a cycle dans un MCT lorsqu'un événement ou un état contribue à une synchronisation-opération qui produit, directement ou à travers plusieurs opérations, ce même événement ou état.
Pour modéliser un fonctionnement répétitif, un MCT peut comporter des cycles. Il faut alors s'assurer que chaque cycle est contrôlé, en précisant clairement les conditions de son démarrage et de son arrêt.
Tout résultat ou état du MCT doit pouvoir être produit (résultat atteignable).
Un résultat ou un état est dit atteignable si l'on peut trouver une séquence d'activation de synchronisations et de conditions d'émission qui permettent de produire ce résultat ou cet état.
Pour un résultat ou un état déterminé, son atteignabilité dépend de plusieurs conditions :
- Existe-t-il dans le schéma représentant le modèle un chemin entre les événements et/ou états initiateurs du processus et ce résultat ?
- Les conditions de déclenchement des synchronisations et les conditions d'émission des résultats et/ou états présents sur ce chemin sont-elles compatibles ?
Les situations de conflit doivent être analysées.
Il y a situation de conflit sur un événement/résultat s'il contribue à plusieurs synchronisations ou s'il est destiné à plusieurs acteurs.
Le conflit peut être résolu si les conditions de participation aux synchronisations sont exclusives, en ajustant la duplication du résultat, ou par une décision explicite du pilote.
Le fonctionnement devient alors déterministe.
Si un conflit n'est pas résolu, le fonctionnement du MCT n'est pas prévisible ; il est dit non déterministe.
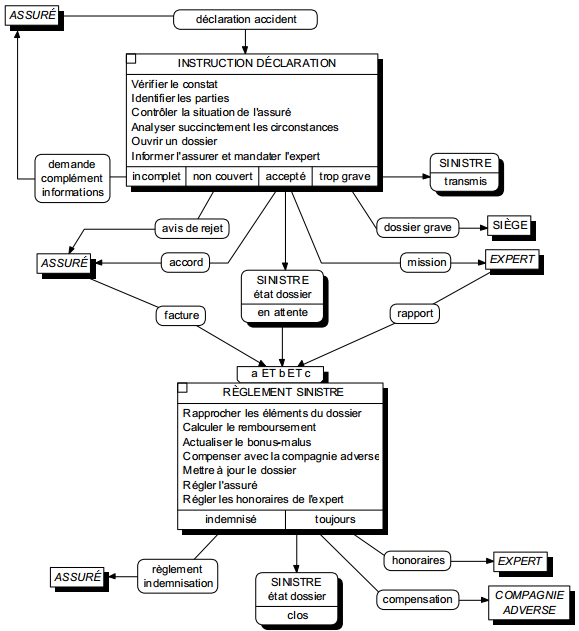
La figure 6.7 illustre cette résolution de conflits.
II-C-5. Construction d'un modèle conceptuel des traitements▲
Rappelons que le concepteur procédera deux fois à l'élaboration d'un MCT : lors de l'étude préalable, puis lors de l'étude détaillée. Les résultats produits seront certes différents dans leur approche et dans leur ampleur ; cependant, l'on retrouvera des principes généraux de construction que nous résumons ci-dessous :
Recenser les acteurs et les flux échangés. L'analyse des flux (voir chapitre 5Chapitre 5 Découpage en domaines et analyse des flux) et sa représentation par le diagramme des flux, en particulier sous sa forme de diagramme des flux conceptuels, permet de mettre en évidence le domaine, les acteurs et les flux échangés. Un effort d'abstraction sera fait pour identifier ces échanges par des événements/résultats.
Identifier les principaux processus, au sein du domaine, liés aux flux précédents.
Découper chaque processus en opérations, c'est-à-dire en une succession d'événements et de résultats. Ce découpage suscite quelques conseils :
- On regroupera dans une même opération toutes les activités qui peuvent être effectuées, dès la survenance de l'événement, sans tenir compte des éventuelles attentes qui ne seraient dues qu'à l'organisation interne. En conséquence, deux opérations consécutives, s'enchaînant directement ou uniquement par un état, ne présentent aucune attente et devraient de ce fait être fusionnées.
- Au niveau conceptuel, l'on ne cherche pas à expliciter l'enchaînement des fonctions élémentaires de l'opération ni les moyens nécessaires à leur exécution (qui sont supposés illimités et immédiatement disponibles). Leur présentation se fait fréquemment sous la forme d'une liste. Il suffit de décrire ce que fait l'opération.
- Dans la description d'un processus, seule l'attente d'événement complémentaire devrait justifier le découpage en plusieurs opérations. Quand une opération s'achève, le domaine perd le contrôle de la poursuite du processus.
- À chaque survenance d'événement, rien n'oblige à ce que toutes les fonctions de l'opération soient à effectuer. Une condition peut se trouver vérifiée dès les premières fonctions d'une opération et conduire à la fin de l'opération.
- L'ensemble des conditions de sortie d'une opération n'est pas obligatoirement dichotomique ; leur expression peut être considérée comme vraie ou fausse à n'importe quelle étape du déroulement de l'opération et plusieurs peuvent avoir la valeur « vraie » à l'issue d'une opération.
- Plusieurs résultats peuvent être émis par la même condition de sortie.
- Il n'est pas obligatoire de représenter comme consécutives (ou liées) des opérations dont l'état résultant de l'une est l'état préalable de l'autre.
II-C-6. Modélisation orientée processus ou orientée état▲
L'introduction de la notion d'état dans la modélisation conceptuelle des traitements que nous avons vu se substituer au rôle d'événement interne entraîne une importante évolution dans la technique, l'approche et la représentation des MCT.
Dans une approche orientée processus, l'analyse et la construction du MCT sont conduites par l'enchaînement chronologique des activités, à partir d'un ou plusieurs événements initiaux. On déroule ainsi le processus, en respectant toutefois les règles de modélisation des opérations (on regroupe dans une opération toutes les activités réalisables à partir des informations fournies par le ou les événements sans avoir besoin d'autres informations nécessitant des événements complémentaires).
La description des processus est alors un enchaînement d'opérations, cet enchaînement étant assuré par les états ; la similitude graphique (voulue) entre événement interne et état permet de conserver l'aspect général et la présentation des MCT de la première génération. Dans cette modélisation, une même opération peut être représentée dans plusieurs schémas de processus. Le MCT présenté en figure 6.6 est une illustration de cette approche orientée processus.
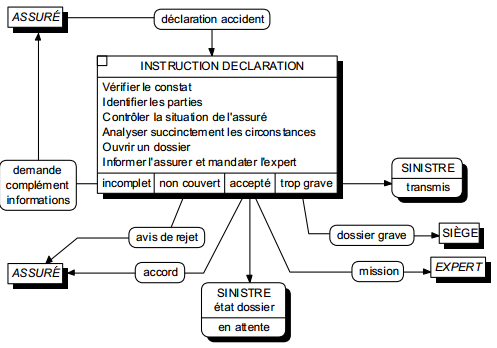
Dans une approche orientée état, chaque opération est analysée indépendamment des autres opérations ; ses conditions de déclenchement étant seulement soumises à la présence d'événements (au moins un) et d'états. Pour les états, le concepteur ne cherche pas à modéliser, voire à connaître, les opérations qui ont antérieurement produit ces états. L'opération ainsi modélisée regroupe un ensemble d'activités dont l'exécution ne demande pas d'échange avec l'environnement du domaine ; on formalise essentiellement ses entrées et ses sorties.
 |
 |
La représentation graphique des MCT est alors une simple juxtaposition d'opérations, sans indication d'enchaînement entre opérations. Dans cette modélisation, une opération n'est représentée qu'une seule fois. La figure 6.8 illustre cette approche orientée état.
Ces deux approches sont complémentaires, voire duales. À partir d'un MCT orienté processus, on peut obtenir un MCT orienté état en dupliquant puis en segmentant tous les états qui matérialisent des enchaînements d'opérations. À partir d'un MCT orienté état, on peut reconstituer l'ensemble des processus possibles en reliant les opérations qui partagent le même état (état résultat, opération précédente - état préalable, opération suivante). Les figures 6.6 et 6.8 l'illustrent partiellement (le nombre limité d'opérations, d'états et de processus ne permet pas de mettre en évidence les différences de présentation).
L'approche processus peut paraître plus « naturelle » aux utilisateurs ; on la retrouve d'ailleurs dans le B.P.R. (Business Process Reengineering). L'approche par état permet d'isoler les opérations, facilitant ainsi l'analyse ultérieure de son contenu ; les informaticiens y retrouveront une certaine « approche objet ».
II-C-7. Modularité des modèles conceptuels de traitements▲
Au niveau normal, le MCT détaille les processus en opérations comme nous l'avons vu précédemment. Sur des projets importants ou complexes, il peut se révéler pratique, au niveau conceptuel, d'élaborer un modèle de degré de détail plus global (voir Niveau d'abstraction et degrés de détailNiveaux d'abstraction, couverture du domaine étudié et degré de détail à la fin du chapitre 3).
Au niveau global, la modélisation des traitements s'effectue alors sous forme d'un processus qui se représente par le même symbole que l'opération. Seuls figurent dans le MCT les événements déclencheurs du processus, et les résultats finaux ; des événements intermédiaires qui fractionnent le processus en le laissant dans un état inachevé ne sont pas pris en compte. Ce modèle, de niveau conceptuel, peut être appelé modèle général des processus.
On peut également élaborer des modèles conceptuels de traitements plus détaillés dans lesquels on décompose les opérations en opérations plus élémentaires et homogènes, essentiellement autour de structures de données simples. Dans ce degré de détail de modélisation, on exprime complètement et formellement les actions sur les données, les règles de traitements et les états. Ce type de modélisation est appelé Modèle Conceptuel des Traitements Analytique dans Merise/2 [Panet, Letouche 94].
Cette stratification des modèles conceptuels des traitements s'inspire des principes de composition/décomposition (refinement) largement utilisés dans des méthodes anglo-saxonnes [SSADM [Longworth, Nicholls 86], SADT 77…]. Nous les utiliserons dans Merise pour faire varier le degré de détail, tout en restant au même niveau de préoccupation.
Pour illustrer cette stratification, la figure 6.9 présente un exemple de modèle général des processus.
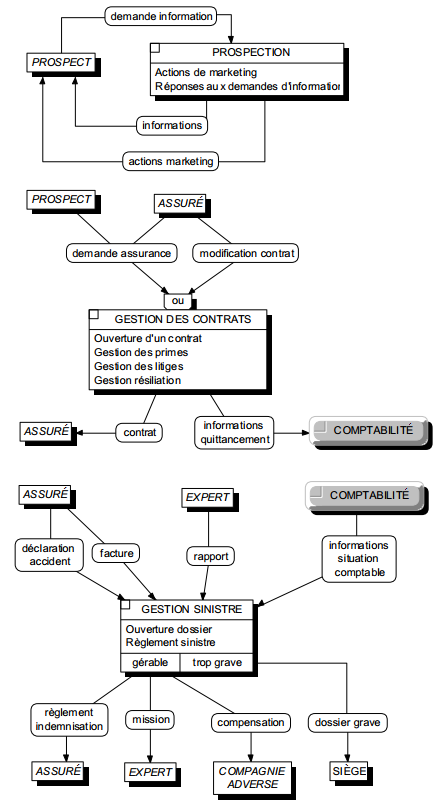
II-C-8. Expression d'un modèle conceptuel des traitements▲
Bien que les présentations puissent être adaptées au contexte d'utilisation, évoquons les principaux éléments composant la présentation d'un modèle conceptuel des traitements :
Liste descriptive des acteurs.
Graphiques :
- diagramme des flux ;
- schéma d'enchaînement des événements, états, opérations, résultats (appelé schéma du MCT), présenté généralement par processus ;
- schéma d'enchaînement des processus.
Pour chaque opération, description (succincte ou détaillée suivant le niveau d'étude) :
- des événements contributifs et du contenu du message associé ;
- des états préalables à l'opération :
- des conditions liées à la synchronisation ;
- du contenu de l'opération en termes de fonctions ;
- des données utilisées ;
- des règles de traitement appliquées ;
- des résultats produits et du contenu du message associé ;
- des états résultants ;
- des conditions de production de ces résultats.
II-D. Chapitre 7 Modélisation conceptuelle des données▲
II-D-1. Problématique du modèle conceptuel de données (MCD)▲
Le modèle conceptuel de données (MCD) est la représentation de l'ensemble des données du domaine, sans tenir compte des aspects techniques et économiques de mémorisation et d'accès, sans se référer aux conditions d'utilisation par tel ou tel traitement.
Dans un système d'information en fonctionnement, données et traitements apparaissent intimement liés (surtout du point de vue de l'utilisateur). L'ensemble des informations utilisées, échangées constitue l'univers du discours du domaine. Dans cet univers du discours, on fait référence à des objets concrets ou abstraits (l'assuré, le contrat) et à des associations entre ces objets (le contrat comporte des garanties). L'objectif du modèle conceptuel de données est d'identifier, de décrire par des informations et de modéliser ces objets et associations.
Dans la démarche de construction d'un modèle conceptuel de données, on distingue deux attitudes, correspondant en fait à la connaissance de l'univers du discours acquise par le concepteur :
- Une démarche déductive qui s'appuie sur l'existence préalable d'une liste d'informations à structurer ; le discours est décortiqué en informations élémentaires.
- Une démarche inductive qui cherche à mettre rapidement en évidence les différents concepts évoqués dans le discours, puis à les décrire par des informations.
Ces deux approches ne sont nullement antagonistes et coexistent alternativement dans la pratique. Précisons toutefois que la démarche déductive est plus lourde à mettre en œuvre, et donc difficilement opérationnelle en étude préalable. Par ailleurs, notre expérience nous incite à préférer la démarche inductive qui s'avère plus créative et efficace. En résumé :
- Si le concepteur opte pour une démarche déductive, il doit d'abord constituer une liste d'informations.
- Si le concepteur choisit la démarche inductive, il peut directement, à l'aide du formalisme, construire le modèle conceptuel de données.
Dans les deux cas, la base essentielle reste le discours (parlé ou écrit) de l'utilisateur ou du gestionnaire, exprimé en langue naturelle.
- Les mots utilisés comprennent les termes usuels de la langue, mais aussi des termes spécialisés du domaine.
- Les phrases fournissent, après une analyse pseudogrammaticale, les principaux objets et les associations entre ces objets.
Bien entendu, on est ici très proche des techniques d'extraction des connaissances [Vogel 88] utilisées avant de construire un système expert.
II-D-2. Constitution d'une liste d'informations▲
Cette liste d'informations est le résultat d'un recueil d'informations circulant dans le domaine. Elle se présente sans aucune structure de regroupement a priori, tout au plus un classement alphabétique.
Pour constituer cette liste, le concepteur peut procéder de deux façons :
- Ratisser, au gré des entretiens, les informations présentes sur quelques documents.
- Exprimer les messages associés aux événements et résultats, et spécifiés dans le modèle conceptuel de traitements ou le modèle organisationnel de traitements (figure 7.1). Notons que, dans ce cas, confronté à des événements/résultats traduisant un flux physique ou monétaire, le concepteur doit le traduire en termes d'informations (d'où un choix de représentation).
Pour chaque information que le concepteur recueille dans son environnement, avant de l'ajouter à la liste déjà établie, il doit répondre aux questions suivantes :
-
La nouvelle information n'a-t-elle pas déjà été répertoriée ? Il est, par exemple, fort probable que l'information n° police apparaisse dans de nombreux messages et documents. Dans ce cas, on considère la « nouvelle » information comme déjà connue.
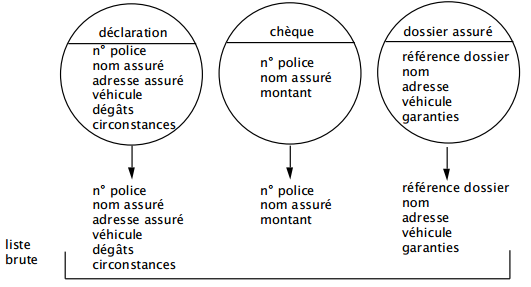
Figure 7.1 : Exprimer les messages associés aux événements/résultats. -
La nouvelle information a été déjà répertoriée, mais sous une appellation différente. Le concepteur est en présence d'un synonyme. Par exemple, référence contrat et n° police. Après s'être assuré de cette synonymie, le concepteur peut soit prendre en compte les deux informations en notant cette synonymie, soit ne retenir qu'une appellation.
- Une appellation identique existe déjà pour la nouvelle information, mais associée à une signification différente. Le concepteur est en présence d'un homonyme. Par exemple, date de livraison (demandée) et date de livraison (effective). Il doit impérativement lever l'ambiguïté en modifiant les appellations des informations.
À la fin de ce travail, le concepteur dispose d'une liste d'informations sans redondance, sans synonyme et sans homonyme. Il prend soin, par ailleurs, d'associer à chaque information une description sous la forme d'un texte libre et éventuellement de mots clés, afin de constituer un catalogue (ou dictionnaire) d'informations.
II-D-3. Formalisme de description des données au niveau conceptuel▲
Le formalisme utilisé dans Merise est désigné par entité-relation. En dehors du contexte de la méthode, il a été reconnu internationalement par l'ISO [ISO TC97 SC5 WG3 1982], et fait l'objet de nombreux développements. Sa diffusion lui a valu plusieurs appellations : formalisme individuel [Tardieu, Heckenroth, Nanci 75][Tardieu, Nanci, Pascot 79], formalisme entity relationship [Chen 76], formalisme entité-relation qui recouvrent, parfois avec quelques nuances, les mêmes idées.
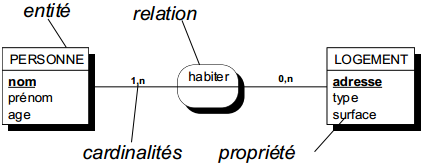
Ce formalisme comporte quatre concepts types de base. Deux concepts sont structuraux, l'entité type et la relation type ; le troisième concept est descriptif, c'est la propriété type ; le quatrième qualifie la liaison entre entité type et relation type, c'est la cardinalité. Ce formalisme possède une représentation graphique présentée à la figure 7.2.
II-D-3-a. La propriété type▲
Une propriété type est la modélisation d'une information élémentaire présente dans le discours. Elle peut prendre des valeurs ; par exemple :
Nom de client : Dupont, Durand, Martin
Date de naissance : 23/07/52, 02/03/63, 25/10/75
Montant du chèque : 250 000 F, 1 392,75 F, 31 745 F
Pourquoi distinguer information et propriété ? La propriété est une manière de modéliser une information, mais toutes les informations ne seront pas systématiquement traduites par une propriété. La propriété subit, pour sa modélisation, un certain nombre de règles que l'information matière première n'a pas à respecter.
La propriété est l'élément descriptif de l'entité type ou de la relation type. Pour prendre sa signification, une propriété est obligatoirement rattachée à une entité type ou à une relation type. Une propriété est unique dans un modèle conceptuel et ne peut être rattachée qu'à un seul concept (entité type ou relation type).
II-D-3-a-i. Propriété composée▲
Dans certains cas, la signification d'une propriété peut être obtenue par la composition d'autres informations, par exemple :
Numéro INSEE : sexe + année + mois + départ + commune + chrono
Référence courrier : initiales auteur + année + n° ordre
Adresse : rue, code postal, ville
On peut opter pour deux modélisations différentes :
- Considérer cette propriété « construite » comme une propriété normale qui suit les mêmes règles que toute propriété et a sa signification intrinsèque, en précisant toutefois la règle de construction. En revanche, il est exclu de considérer une fraction de valeur d'une telle propriété comme ayant une signification propre, par ailleurs non exprimée.
Exemple : les deux premiers caractères du code article représentant la famille. - Utiliser une propriété composée en modélisant éventuellement sa composition sous forme de propriétés. Cette modélisation permet, en particulier en étude préalable, de nommer un ensemble d'informations sans systématiquement en exprimer le détail. Dans ce cas, chaque fraction de valeur d'une propriété composée peut être exprimée par la valeur de chaque propriété composante.

II-D-3-a-ii. Propriété générique▲
Certaines informations, par exemple les adresses, décrivant des entités (ou des relations) différentes sont, à juste titre, modélisées comme des propriétés distinctes. Toutefois, ces propriétés possèdent en commun une signification générique et des caractères descriptifs (composition, format, contraintes de valeurs…). On qualifie cette information de référence de propriété générique. Une telle propriété n'est affectée à aucune entité ou relation, donc n'est pas représentée sur les schémas ; elle ne sert qu'à supporter les caractères généraux communs à l'ensemble des propriétés qui s'y réfèrent. La notion de propriété générique est essentiellement utile dans la modélisation organisationnelle des données (Chap. 9Chapitre 9 Cycle de vie des objets et objets métiers) et lors du passage au modèle logique de données relationnel (Chap. 13Chapitre 13 Modélisation Logique des Données).
II-D-3-b. L'entité type▲
L'entité type permet de modéliser un ensemble d'objets de même nature, concrets ou abstraits, perçus d'intérêt dans le discours. L'entité type exprime un type, une classe, un ensemble dont les éléments sont appelés occurrences d'entité type. La représentation graphique de l'entité est illustrée sur la figure 7.2.
Quelques règles régissent la modélisation en termes d'entité type.
II-D-3-b-i. Règle de pertinence▲
La définition de l'entité type est un choix du concepteur en fonction de l'intérêt qu'elle présente. À partir d'objets concrets ou abstraits du monde réel, le concepteur peut, à son gré, composer diverses modélisations en termes d'entité.
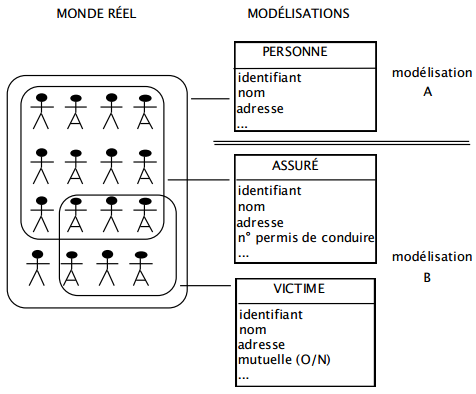
Par exemple, dans le cas du domaine de l'assurance auto, différentes modélisations de l'environnement perçu sont possibles (voir figure 7.4).
Il est probable que l'assureur préférera la modélisation B, qui peut mieux convenir à sa manière de percevoir son environnement en fonction de son activité. L'assureur perçoit alors douze assurés et six victimes. Sauf modélisation spécifique complémentaire, cet assureur ne saura pas que certains assurés sont également victimes ; pour lui, ce sont des occurrences d'entités différentes.
II-D-3-b-ii. Règle d'identification▲
L'on doit pouvoir faire référence distinctement à chaque occurrence de l'entité. Pour cela l'entité type doit être dotée d'un identifiant. Cet identifiant est une propriété telle que, à une valeur de l'identifiant, corresponde une seule occurrence de l'entité type.
Cette correspondance biunivoque entre l'occurrence de l'entité type et la valeur de son identifiant doit être vérifiée au présent, mais également confirmée dans le futur. Le choix d'un identifiant est un problème délicat. On peut opter pour :
- une propriété « naturelle », par exemple le nom d'un pays pour l'entité pays ;
- une propriété « artificielle », inventée par le concepteur pour identifier l'entité qu'il vient de concevoir (tous les numéros, références, codes, etc., en sont l'illustration) ;
- une propriété composée en s'assurant que la règle de composition ne générera pas de doublons ; on parle alors d'identifiant composé ; par exemple nom + prénom + date et lieu de naissance ;
- un identifiant relatif, par exemple n° allocataire + n° ordre (voir Identifiant relatif).
Le concepteur doit également être prudent dans la reprise d'identifiants issus de la liste d'informations, car cela peut ainsi reconduire involontairement la perception initiale de l'entité type.
Enfin, un identifiant d'une entité type doit être :
- univalué : à une occurrence correspond une seule valeur pour un identifiant donné ;
- discriminant : à une valeur correspond une seule occurrence de l'entité ;
- stable : pour une occurrence donnée d'entité, une fois affectée une valeur à son identifiant, cette valeur doit être conservée jusqu'à la destruction de l'occurrence ;
- minimal : s'agissant d'un identifiant composé, la suppression d'un de ces composants lui ferait perdre son caractère discriminant.
Notons que certaines entités peuvent avoir plusieurs propriétés possédant les qualités d'identifiant ; ils sont qualifiés d'identifiants alternatifs.
II-D-3-b-iii. Règle de distinguabilité▲
Les occurrences d'une entité type doivent être distinguables. Face à deux objets du monde réel, et par rapport à la modélisation qu'il en fait, le concepteur doit pouvoir dire : c'est la même occurrence, ce n'est pas la même occurrence ! Cette distinguabilité induit la compréhension de l'entité type et se traduit par le choix de l'identifiant.
Prenons l'exemple de livres issus d'une même bibliothèque.
Un lecteur percevra trois occurrences distinctes (les deux César étant le même pour lui), tandis que le bibliothécaire percevra quatre occurrences distinctes (Figure 7.5).

Nous attirons l'attention du concepteur sur l'extrême importance que revêt ce choix de distinguabilité, intimement lié à l'identifiant, et qui bien souvent sera la source de quiproquos ultérieurs, voire de la remise en cause du système d'information.
II-D-3-b-iv. Règle de vérification▲
L'entité type est décrite par une liste de propriétés. Chaque propriété rattachée à l'entité type doit impérativement suivre la règle suivante, dite de vérification (ou de non-répétitivité) :
À toute occurrence de l'entité type, il ne peut y avoir, dans la mémoire du système d'information, au plus qu'une valeur de la propriété.
Si la réponse à cette règle est négative, la propriété concernée ne peut appartenir à l'entité type.
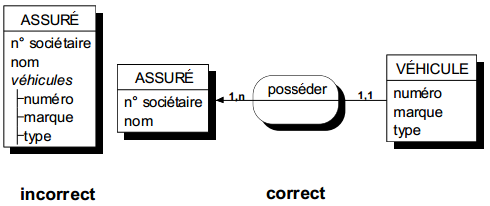
Si un assuré peut avoir plusieurs véhicules assurés, alors les propriétés numéro, marque et type ne peuvent appartenir à l'entité ASSURÉ. Le concepteur devra faire appel à une autre modélisation (nouvelle entité et nouvelle relation). Cette règle a d'abord pour objectif de faire modéliser explicitement les éventuels objets à l'origine de la multiplicité de valeurs des propriétés (Figure 7.5.a).
Cette règle d'unicité de valeur peut toutefois être non respectée dans les cas suivants :
- Si la multiplicité des valeurs d'une propriété est exclusivement due à la conservation des valeurs successives prises par cette propriété au cours du temps, on considérera que cette propriété, pour sa valeur présente, respecte la règle de vérification. Le problème sera abordé et résolu par la modélisation des historiques (voir Modélisation des historiques).
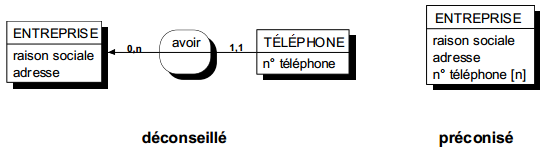
- Si la multiplicité des valeurs exprime une liste de valeurs sans pour autant traduire la présence d'objets d'intérêt à modéliser, on modélisera une propriété multivaluée.
Exemple : une entreprise ayant une liste de n° de téléphone ; l'entité téléphone n'a, en général, que peu d'intérêt (Figure 7.6.b).
II-D-3-b-v. Règle d'homogénéité▲
Il est souhaitable que les propriétés rattachées à une entité type aient un sens pour toutes les occurrences de celle-ci. Cette règle invite le concepteur à s'assurer que, dans sa compréhension de l'entité type, il n'englobe pas plusieurs populations dont certaines ont des caractères spécifiques exprimés dans la liste des propriétés. Le concepteur peut :
- soit confirmer sa modélisation initiale et tolérer que, pour certaines occurrences, des propriétés ne soient pas pertinentes ;
- soit remodéliser sa perception en plusieurs entités types.
Cette question sera ultérieurement étudiée sous les thèmes : sous-types d'entités puis liste variable de propriétés.
II-D-3-c. La relation type▲
La relation type modélise un ensemble d'associations de même nature entre deux ou plusieurs occurrences d'entités (de types différents ou du même type), perçus d'intérêt dans l'univers du discours. La représentation graphique de la relation est illustrée sur la figure 7.2.
Quelques règles régissent la modélisation en termes de relation type :
II-D-3-c-i. Le choix de la relation type▲
Il dépend de l'intérêt porté par le concepteur aux associations perçues. La relation type n'existe qu'à travers les entités types qui la composent.
On appelle dimension le nombre d'entités types composant la relation type. On appelle collection la liste de ces entités. L'ordre de citation des entités types dans la collection est sans importance.
Soulignons, à l'occasion, les difficultés pratiques liées à l'appellation des relations. Fréquemment, on désigne les relations types par des verbes ; cet usage s'explique et peut se justifier par la similitude existant entre le formalisme entité relation et la grammaire moderne (groupe nominal, groupe verbal).
Il est souhaitable d'utiliser un verbe à l'infinitif. Un verbe exprime parfois une action qui peut alors être assimilée à un traitement ; nous conseillons d'utiliser un verbe plus statique plutôt qu'un verbe d'action qui a plus sa place dans les MCT et MOT. La forme active ou passive d'un verbe permet d'orienter la lecture de la relation. On peut éventuellement utiliser un substantif issu du verbe.
De nombreuses relations expriment la notion d'appartenance (appartenir, concerner…). On peut les qualifier en évoquant l'une des entités.
On peut également construire une abréviation à partir des noms des entités. Par contre, nous déconseillons de recourir à la numérotation des relations (R1, R2…).
II-D-3-d. Identification d'une relation type▲
Une relation type n'a pas d'identifiant propre. L'occurrence d'une relation type est déterminée par les occurrences des entités types de sa collection. À une combinaison d'occurrences d'entités types composant la collection d'une relation type, il ne peut y avoir au plus qu'une occurrence de cette relation type.
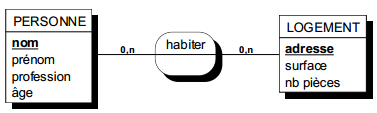
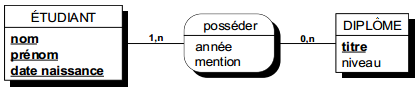
L'identification d'une relation est réalisée par la conjonction des identifiants des entités de sa collection. Dans la figure 7.6, la relation « habiter » est identifiée par la concaténation d'une valeur de nom de personne et d'une valeur d'adresse de logement.
Une occurrence de relation type ne peut exister que reliée à une occurrence de chacune des entités types de sa collection (pas de patte optionnelle possible dans la relation).
Attention, il ne faut pas réciproquement en déduire qu'un concept identifié par la conjonction d'identifiants d'entités doit systématiquement être modélisé comme une relation. L'intérêt du concepteur pour ce concept peut le conduire à le modéliser comme une entité (règle de pertinence) avec une identification relative multiple (voir Identification relative et entité faible).
II-D-3-d-i. Propriétés d'une relation type▲
La relation type peut être dotée de propriétés (cf. figure 7.6). Il s'agit d'informations qui ne peuvent prendre de sens qu'avec la présence de l'ensemble des entités constituant cette relation type.
II-D-3-d-ii. Règles de vérification et de normalisation▲
La règle de vérification s'applique aux propriétés rattachées à une relation type : à une occurrence d'une relation type, il ne peut y avoir, dans la mémoire du système d'information, qu'une seule valeur pour chacune des propriétés rattachées à cette relation type.
De nombreuses relations types sont modélisées sans propriétés, on les appelle familièrement relations vides.
Il faut également s'assurer que la propriété est correctement affectée à la relation. La propriété a été vérifiée par rapport à l'occurrence de la relation type, c'est-à-dire par rapport à la totalité des entités formant sa collection. Cette propriété ne doit pas également être vérifiée par rapport à un sous-ensemble des entités de la collection. Cette règle s'appelle la normalisation. Si l'on peut vérifier une propriété par rapport à un sous-ensemble de la collection, deux cas se présentent :
- Le sous-ensemble est réduit à une seule entité type, la propriété en cause est à rattacher à cette entité type.
- Le sous-ensemble est composé de plusieurs entités types, il faut éventuellement créer une nouvelle relation type de cette dimension et y rattacher la propriété en cause.
 |
|
Collection de la relation posséder : {personne, diplôme}. |
II-D-3-e. Variété des relations types▲
À la différence de la plupart des formalismes de représentation de données proches de l'informatique ainsi que des formalismes « Entity-Relationship » et dérivés, le formalisme entité-relation de Merise propose une grande variété d'expressions des relations. Nous allons en présenter quelques-unes.
II-D-3-e-i. La dimension d'une relation est non limitée▲
Il est possible d'exprimer des relations plus que binaires (n-aires), comme sur la figure 7.7. En pratique, nous n'avons jamais rencontré de relation type de dimension supérieure à 7 (pas plus de sept entités types dans la collection d'une relation type).
Cela tient, selon nous, à deux facteurs :
- Le cerveau humain ne peut visualiser, manipuler ou mémoriser simultanément que six ou sept éléments distincts (mémoire à court terme).
- La langue naturelle correspond à cette même complexité ; ainsi, une phrase en français, sans proposition relative, ordonne autour d'un verbe, au plus, sept éléments : sujet, complément d'objet direct, complément d'objet second, compléments circonstanciels de temps, de lieu, de manière et d'accompagnement.
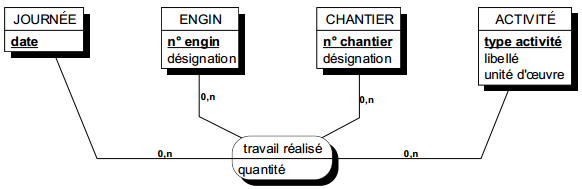 |
|
Une occurrence de cette relation pourrait être : le 22 février 1995, le bulldozer n° 4589B a réalisé sur le chantier n° 1258 du pont de l'Alpe, un travail de déneigement de 300 m3 |
Remarquons cependant que, dans la pratique, une grande proportion des relations types modélisées est binaire.
II-D-3-e-ii. Plusieurs relations types peuvent partager la même collection▲
Situation tout à fait normale où, entre deux ou plusieurs entités types, des associations de significations différentes peuvent exister. La figure 7.8 en est une illustration.
II-D-3-e-iii. Une même entité type peut apparaître plusieurs fois dans la collection d'une relation type▲
Une association peut exister entre les occurrences d'une même entité (voire sur la même occurrence). Dans ce cas, il convient de préciser (sur la patte de relation) le rôle joué par chacune des occurrences d'entité dans le cadre de la relation ; en effet, le plus souvent une relation type n'est pas symétrique (voir figure 7.9).
Ces relations sont souvent appelées réflexives, surtout lorsque les deux pattes bouclent sur une seule entité.
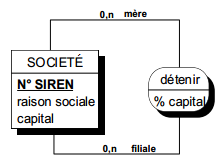 |
|
Les termes mère et filiale précisent le rôle joué par chacune des occurrences de l'entité société dans la relation participer. |
 |
|
Les termes bailleur et locataire précisent le rôle joué par chacune des occurrences d'entités personne dans la relation louer. |
II-D-3-f. Les cardinalités d'une entité type dans une relation type▲
Le terme cardinalité, dans le formalisme entité-relation, traduit la participation des occurrences d'une entité type aux occurrences d'une relation type.
Cette participation s'analyse par rapport à une occurrence quelconque de l'entité type, et s'exprime par deux valeurs : la cardinalité minimum et la cardinalité maximum. Ces cardinalités seront représentées dans un modèle conceptuel de données comme sur la figure 7.10.
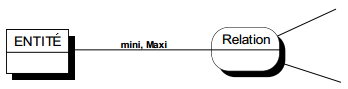
Ce couple de valeurs se note sur la patte de la relation type concernée par l'entité type dont on qualifie ainsi la participation à la relation type. Bien que des valeurs quelconques puissent être affectées à ces cardinalités, certaines valeurs typiques caractérisent les situations les plus courantes.
- Cardinalité mini = 0 : certaines occurrences de l'entité type ne participent pas à la relation ; participation optionnelle.
- Cardinalité mini = 1 : toute occurrence de l'entité type participe au moins une fois aux occurrences de la relation ; participation obligatoire.
- Cardinalité maxi = 1 : quand une occurrence de l'entité type participe à la relation, elle n'y participe au plus qu'une fois ; unicité de participation.
- Cardinalité maxi = n : quand une occurrence de l'entité type participe à la relation, elle peut y participer plusieurs fois ; multiplicité de participation.
On remarquera qu'au niveau conceptuel, on ne cherche pas systématiquement à chiffrer cette multiplicité.
Ainsi, les cardinalités fréquemment utilisées sont :
|
Participation |
Optionnelle |
Obligatoire |
|---|---|---|
|
Unique |
0,1 |
1,1 |
|
Multiple |
0,n |
1,n |
Les cardinalités mini et maxi ont une importance différente. On peut ainsi, si besoin est, laisser la cardinalité mini indéterminée ; elle peut alors être notée par le symbole « ? ».
En pratique, on constatera qu'il est plus facile de déterminer les cardinalités des relations binaires que celles des relations ternaires (ou plus). En effet, dans une relation binaire, en fixant une occurrence d'entité, les occurrences de la relation sont assimilables aux occurrences de l'entité restée « libre ». Par contre, dans le cas de relation ternaire (ou plus), en fixant une occurrence d'entité, les occurrences de la relation représentent des n-uples d'occurrences des entités restées libres, ce qui est plus difficile à imaginer.
II-D-3-f-i. Exemple de cardinalité sur une relation binaire▲
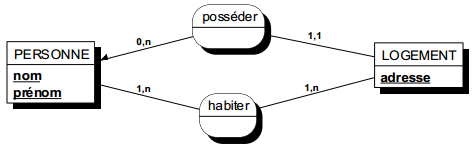
Une occurrence d'assuré peut être concernée par un ou plusieurs contrats (cardinalité 1,n), tandis qu'une occurrence de contrat ne concerne qu'un et un seul assuré (cardinalité 1,1).
Toute relation binaire avec cardinalité (1,1) ne peut être porteuse de propriétés. En effet une telle propriété (voir figure 7.11) migre alors obligatoirement dans l'entité portant cette cardinalité (1,1).
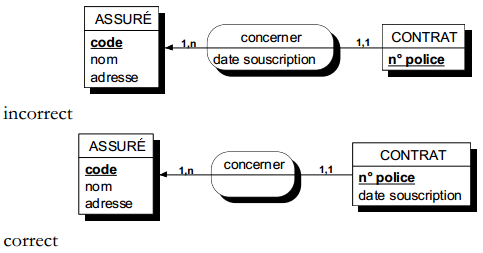
Dans la figure 7.11, tout contrat n'a qu'une et une seule date de souscription.
II-D-3-f-ii. Exemple de cardinalité sur une relation ternaire▲
La relation ternaire de la figure 7.12 exprime, par exemple, que l'entreprise Dupin a réalisé un montant annuel de 8 500 F de menuiserie à la copropriété Beau-Manoir. De plus les cardinalités précisées s'interprètent ainsi :
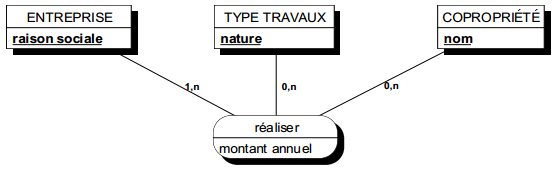
ENTREPRISE (1,n)
Toute entreprise a au moins un montant réalisé (le système d'information ne connaît que les entreprises qui ont réalisé des travaux sur les copropriétés). Une entreprise peut avoir plusieurs montants réalisés (sur plusieurs copropriétés et/ou plusieurs types de travaux).
COPROPRIÉTÉ (0,n)
Une copropriété peut n'avoir fait l'objet d'aucun travail.
Certaines copropriétés peuvent faire l'objet de plusieurs travaux, de même type ou de types différents et/ou réalisés par des entreprises différentes ou la même entreprise.
TYPE TRAVAUX (0,n)
Un type de travaux peut ne faire l'objet d'aucune réalisation.
Il peut y avoir plusieurs montants réalisés pour un type de travaux, cela par plusieurs entreprises ou une seule et/ou concernant plusieurs copropriétés ou une seule.
C'est à l'occasion de la détermination des cardinalités sur des relations de dimension supérieure à 2 que l'on détectera les éventuelles dépendances fonctionnelles (voir plus loin « Contraintes intrarelationContraintes intrarelation »).
Ainsi, dans l'exemple de la figure 7.12, la cardinalité maxi d'entreprise est n, c'est- à-dire qu'une entreprise peut réaliser plusieurs montants de travaux dans plusieurs copropriétés. Supposons que toute entreprise ne soit spécialisée que dans un seul type de travaux. La cardinalité maxi reste toujours égale à n, mais on a mis en évidence une dépendance fonctionnelle complétant la sémantique du modèle. Cette dépendance fonctionnelle permettra de décomposer éventuellement la relation (voir plus loin «Décomposition d'une relation type»).
II-D-3-g. Types et sous-types d'entités : spécialisation/généralisation▲
Ces notions de types et de sous-types ont été intégrées au formalisme entité - relation Merise, lors du congrès « Autour et à l'entour de Merise », suite aux travaux de normalisation du groupe 135, « Conception des systèmes d'information » de l'AFCET [AFCET 91] [Tabourier 91]. Nous nous inspirerons fortement des travaux de ce groupe pour présenter ces extensions.
II-D-3-h. Spécialisation simple▲
La spécialisation permet de modéliser dans une population (l'ensemble des occurrences) d'une entité, des sous-populations (sous-ensembles d'occurrences) présentant des spécificités. Ces spécificités peuvent porter sur :
- des propriétés ;
- des relations ;
- des appellations.
Ces sous-populations sont explicitement modélisées par des entités dites entités sous-types par rapport à l'entité surtype.
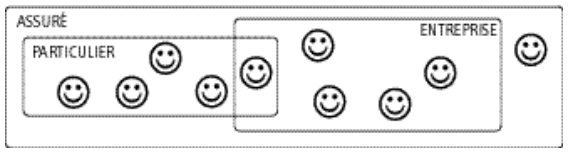
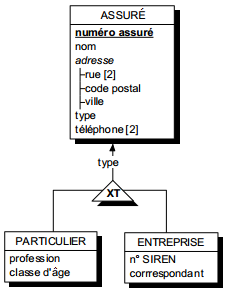
Soit le cas d'un cabinet d'assurance gérant des assurés. Parmi ces assurés, le concepteur souhaite distinguer deux sous-populations : les particuliers et les entreprises. En tant qu'assurés, particuliers et entreprises ont des caractéristiques communes. Ils ont en outre des caractéristiques spécifiques, par exemple, la date de naissance et la profession pour les particuliers, le SIRET et la forme juridique pour les entreprises.
La spécialisation consiste tout d'abord à modéliser une entité Assuré, qualifiée de surtype et comportant les propriétés communes aux assurés. Ensuite de considérer les deux entités Particulier et Entreprise comme deux spécialisations de cette entité Assuré. Particulier et Entreprise sont alors appelés entités sous-types de l'entité surtype Assuré.
Les occurrences des entités sous-types sont obligatoirement et également des occurrences de l'entité surtype. Les entités sous-type n'accueillent que les propriétés spécifiques. On dira ainsi que les entités sous-types héritent des propriétés de leur entité surtype. Ce mécanisme d'héritage s'applique aussi à l'identifiant du surtype. Dans le cas de la spécialisation, les entités sous-types ne possèdent pas d'identifiant propre.
Graphiquement, les entités sous-types et surtypes se représentent comme des entités classiques. La spécialisation (ou héritage) se représente sous la forme d'un triangle qui portera éventuellement une contrainte, relié aux entités concernées ; l'entité surtype est indiquée par un lien fléché. Pour notre exemple, on a la modélisation de la figure 7.13.
La spécialisation d'une entité surtype en entités sous-types peut s'effectuer selon un critère de spécialisation : explicitable par :
- des valeurs d'une propriété du surtype ;
- une règle de gestion.
Certaines relations types peuvent également n'avoir de signification que par rapport à une entité sous-type.
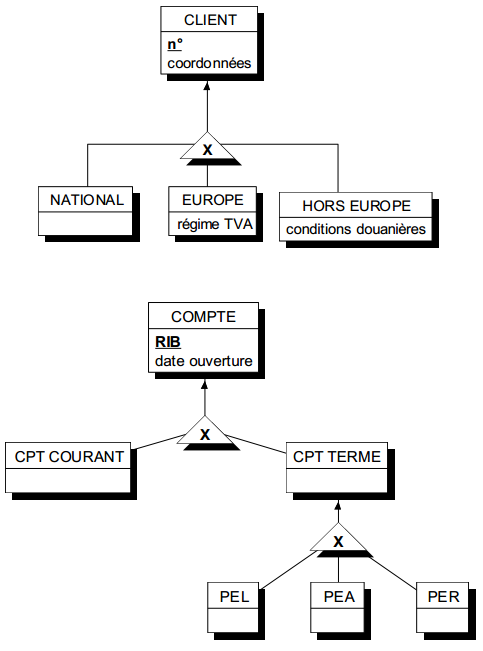
Une spécialisation peut comporter un nombre quelconque de sous-types. Une entité sous-type d'une spécialisation peut être également surtype d'une autre spécialisation ; on obtient ainsi une arborescence de spécialisations (figure 7.15).
Dans la spécialisation, l'entité surtype, porteuse de l'identifiant, préexiste par rapport aux entités sous-types qui ne sont que des déclinaisons de l'entité surtype.
Le processus de perception va du général au particulier.
II-D-3-i. Spécialisations multiples▲
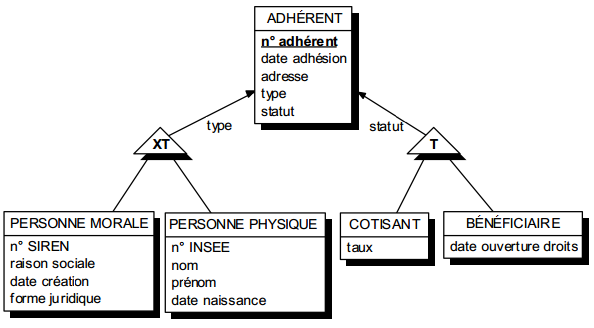
Le découpage d'une population en sous-populations peut s'effectuer selon plusieurs critères, chaque critère produisant une spécialisation en différents sous-types. La multiplicité des critères peut parfois conduire à une combinatoire difficile à maîtriser.
II-D-3-j. Contraintes sur spécialisations ▲
Les contraintes sur spécialisation expriment les participations des occurrences de l'entité surtype aux entités sous-types. On retrouvera les contraintes ensemblistes classiques.
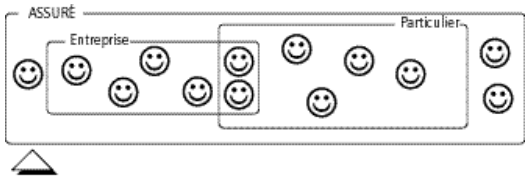
Pas de contrainte : un assuré peut être une entreprise, un particulier, un particulier et une entreprise, ni un particulier ni une entreprise.
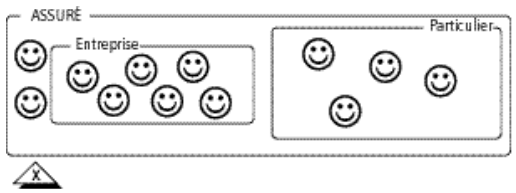
Exclusivité : un assuré peut être une entreprise, un particulier, ni un particulier ni une entreprise, mais ne peut pas être entreprise et particulier.
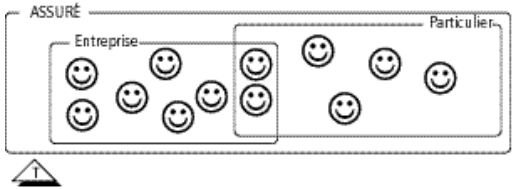
Totalité : tout assuré est un particulier, une entreprise, ou les deux.
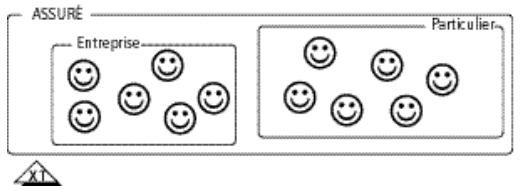
Partition : tout assuré est soit un particulier, soit une entreprise.
Ces notions de contraintes sur spécialisation sont identiques à celles qui seront développées plus loin pour les relations dans la section « Contraintes sur la participation d'une entité à plusieurs relationsContraintes sur la participation d'une entité à plusieurs relations ».
II-D-3-k. Spécialisations à surtypes multiples▲
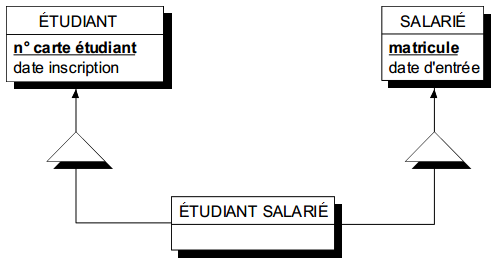
Considérons la population des étudiants et la population des salariés. On peut vouloir s'intéresser aux étudiants qui sont aussi salariés et vice-versa. Ce qui revient à considérer l'intersection des populations d'étudiants et de salariés.
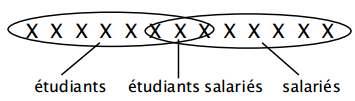
Cela conduit à faire émerger dans la modélisation une entité étudiant salarié, sous-type d'une part de l'entité étudiant, et d'autre part de l'entité salarié. On observe alors une double spécialisation à surtypes multiples de cette nouvelle entité étudiant salarié, modélisée sur la figure 7.17.
Dans ce cas, l'entité étudiant salarié hérite des propriétés d'étudiant et de salarié.
L'identifiant de l'entité étudiant salarié est soit l'identifiant de l'entité étudiant (n° inscription), soit l'identifiant de l'entité salarié (n° matricule). On est en présence d'identifiants alternatifs.
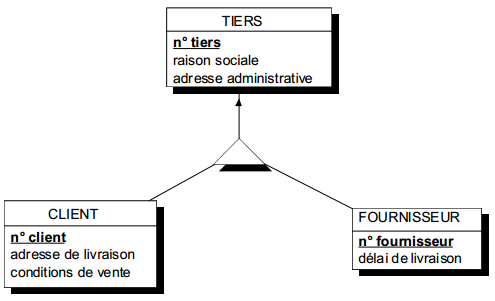
II-D-3-l. Généralisation▲
Dans la généralisation, inversement à la spécialisation, ce sont les entités sous-types qui préexistent. En conséquence, les identifications de ces entités sous-types sont indépendantes de l'identification de l'entité surtype. Les entités sous-types ont leurs propres identifiants, comme le montre la modélisation de la figure 7.18. L'identifiant hérité du surtype est alors un identifiant alternatif dans chacun des sous-types. Le processus d'héritage, la représentation graphique ainsi que les contraintes sont identiques à la spécialisation.
La généralisation apparaît comme une « mise en facteurs communs » de propriétés. Le processus de perception va du particulier au général.
En spécialisation comme en généralisation, on obtient dans les deux cas une structure de surtype / sous-types avec héritage. La différence porte d'abord sur le processus de perception et se traduit au niveau de l'identification.
II-D-3-m. Restrictions et sous-types de relations▲
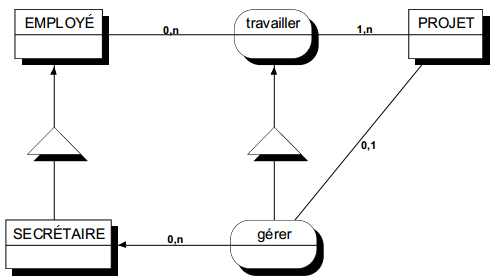
Les types et sous-types de relations concernent la restriction de relations à des sous-types d'entités. Pour illustrer cette restriction, considérons le modèle suivant : une entité surtype employé, une entité secrétaire, sous-type d'employé. Soit une troisième entité projet auquel peuvent être affectés des employés, au travers de la relation travailler. Bien qu'un projet comporte plusieurs employés, supposons qu'il y ait au plus une secrétaire qui puisse travailler sur un projet donné.
Ainsi, pour les employés secrétaires, il y a modification des cardinalités de la relation travailler. On prendra en compte une telle situation en introduisant une nouvelle relation, restriction de la relation travailler, appelée gérer, et dont les occurrences sont celles de travailler pour lesquelles l'employé est une secrétaire. Il est alors possible sur cette restriction de la relation de préciser de nouvelles cardinalités. On représentera cette restriction de relation comme une spécialisation de relation comme l'indique la modélisation de la figure 7.19.
Notons que la relation gérer hérite des éventuelles propriétés de la relation travailler et peut comporter des propriétés propres qui n'auraient pas de sens pour toutes les occurrences de la relation originale travailler. La restriction de relation peut être considérée comme une relation sous-type de la relation originale.
II-D-3-n. Contraintes intrarelation▲
En mathématiques, la notion de dépendance fonctionnelle entre deux ensembles A et B exprime qu'à un élément a de A correspond au plus un élément b de B ; on note :
|
A ———> B |
L'ensemble de départ peut être simple, ou composé par le produit de deux ou plusieurs ensembles ; à un couple (a,b) correspond un seul c :
|
A x B ———> C |
On appelle l'ensemble (ou les ensembles) de départ l'émetteur et l'ensemble d'arrivée la cible de la dépendance fonctionnelle.
Dans le formalisme conceptuel de données de Merise, cette notion de dépendance fonctionnelle s'applique, entre autres, au sein d'une relation type entre deux ou plusieurs entités types de sa collection. Nous allons étudier plusieurs cas pouvant se présenter.
II-D-3-n-i. Représentation graphique générale des contraintes intrarelation▲
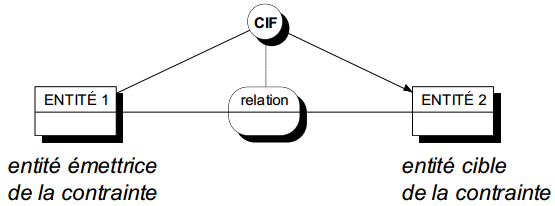
Les dépendances fonctionnelles (ou contraintes d'intégrité fonctionnelles ou CIF) sur une relation ne peuvent pas toujours être spécifiées par les cardinalités définies sur ses pattes. Il est nécessaire d'introduire un graphisme spécifique. La représentation graphique générale (voir figures 7.20 et 7.21) pour ces dépendances fonctionnelles est la suivante :
- un cercle dans lequel est indiqué CIF (éventuellement indicé) ;
- un lien en pointillé indique la relation sur laquelle s'applique la contrainte ;
- un lien plein non fléché indique la (ou les) entité(s) émettrice(s) de la dépendance ;
- un lien plein fléché indique l'entité cible de la dépendance.
II-D-3-o. Dépendance fonctionnelle sur une relation binaire▲
Une dépendance fonctionnelle sur ce type de relation exprime qu'à partir d'une occurrence d'une entité type correspond (au plus) une seule occurrence de l'autre entité type de la collection. On constate, dans ce cas, qu'il y a correspondance entre :
- la cardinalité maximum = 1 ;
- et l'existence d'une dépendance fonctionnelle.
Ces relations types seront couramment appelées binaires fonctionnelles.
II-D-3-o-i. Exemple de relation binaire fonctionnelle▲
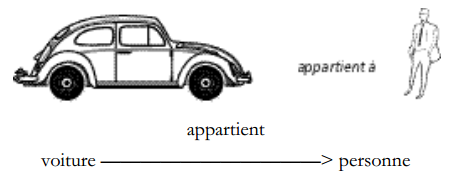
Une voiture n'appartient qu'à une personne au plus.
Ces relations binaires fonctionnelles sont très utiles, car elles permettent de faire référence à une occurrence d'une entité par l'intermédiaire d'une autre entité et d'une relation (exemple : le propriétaire du véhicule 1234 PX 13).
Pour les dépendances fonctionnelles sur relation binaire, nous préférerons, au graphisme général, « intégrer » la dépendance fonctionnelle à la relation en fléchant la patte la reliant à l'entité cible (voir figure 7.22).

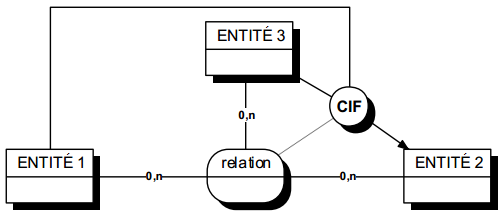
II-D-3-p. Dépendances fonctionnelles sur une relation n-aire▲
On peut avoir plusieurs catégories de dépendances fonctionnelles (ou contraintes d'intégrité fonctionnelles) :
- des dépendances fonctionnelles simples (1 émetteur) ;
- des dépendances fonctionnelles composées (n-uple d'émetteurs), mais n'englobant pas la totalité de la collection de la relation ;
- des dépendances fonctionnelles composées (n-uple d'émetteurs) englobant la totalité de la collection.
Les deux premiers cas représentent souvent une situation provisoire dans le processus de conception et seront traités par l'opération dite de décomposition (voir plus loin, « Décomposition de relation type »). Le dernier cas sera noté graphiquement et exprimé lors de la description de la relation type.
Lors de la détermination des cardinalités, la mise en évidence de ces dépendances fonctionnelles doit être une opération systématique pour les relations de dimension supérieure à 2.
Plusieurs dépendances fonctionnelles peuvent être définies au sein d'une relation. Dans ce cas, qui reste en pratique exceptionnel, il convient d'effectuer un certain nombre de contrôles, fondés sur la logique, et qui peuvent conduire à l'élimination de certaines dépendances fonctionnelles [Tardieu, Nanci, Pascot 79]
II-D-3-p-i. Exemple de dépendance fonctionnelle simple▲
Reprenons l'exemple déjà utilisé concernant des types de travaux réalisés par des entreprises sur des copropriétés. Supposons que chaque entreprise n'effectue qu'un seul type de travaux, soit :
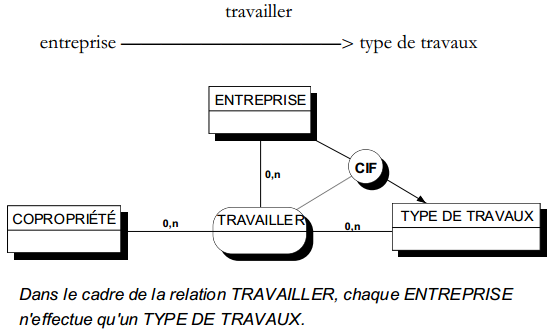
Cette dépendance fonctionnelle, ou CIF, ne peut être représentée au travers des cardinalités de la relation. Il est nécessaire d'utiliser le graphisme spécifique déjà proposé ; de plus, il est recommandé d'accompagner ce graphisme d'un texte explicatif, comme l'illustre la modélisation de la figure 7.23.
Rappelons qu'une telle dépendance fonctionnelle est provisoire et sera traitée dans la décomposition.
II-D-3-p-ii. Exemple de dépendance fonctionnelle composée englobant la totalité de la collection▲
Pour tout module d'emploi du temps (exemple, le mardi de 9 heures à 10 heures), un professeur ne fait cours que dans une seule salle, soit :
|
faire cours |
La modélisation graphique associée est celle de la figure 7.24.
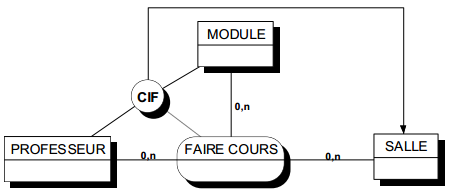
Lorsque ce type de contrainte est la seule portée par la relation, nous suggérons de l'intégrer à la relation en fléchant la patte la connectant à l'entité cible, comme sur la figure 7.25.
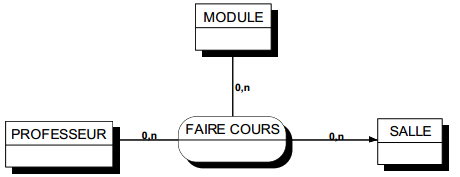
II-D-3-q. Contraintes interrelations▲
Les cardinalités et dépendances fonctionnelles précédentes s'appliquaient, sous forme de contraintes, dans le cadre d'une même relation type. D'autres situations présentent des conditions à exprimer entre deux ou plusieurs relations types.
II-D-3-r. Contraintes sur la participation d'une entité à plusieurs relations▲
Ces conditions concernent fréquemment la coexistence d'occurrences de relations types au départ d'une entité type commune. Nous allons étudier différentes situations pouvant se présenter, comme l'illustre la figure 7.26.
Ce type de contrainte est symbolisé (voir figure 7.27) par :
- un cercle dans lequel est indiqué le type de contrainte (éventuellement indicé) ;
- un lien en pointillé qui indique l'entité impliquée dans la contrainte ;
- un lien plein qui indique les relations concernées par la contrainte.
Il est conseillé d'accompagner le modèle graphique d'un bref texte explicatif.
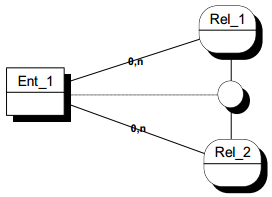
II-D-3-r-i. Exclusivité de participation d'une entité à plusieurs relations▲
Deux (ou plusieurs) relations types, au départ d'une entité type commune, peuvent avoir des existences, en termes d'occurrences, mutuellement exclusives. On l'exprime par une contrainte X.
Exemple : un article peut être acheté chez des fournisseurs, approvisionné par des unités de production extérieures, ou élaboré (ou assemblé) directement dans le domaine ; il ne peut cependant être à la fois acheté et approvisionné. On a ici une contrainte d'exclusivité de la participation de l'entité article aux relations acheter et approvisionner. La modélisation associée est celle de la figure 7.28.
 |
|
Par rapport à l'entité article, les relations acheter et approvisionner sont mutuellement exclusives. |
Il est possible d'affiner cette exclusivité. En effet, soit une entité A participant à deux relations R1 et R2, trois cas d'exclusivité sont possibles (voir figure 7.29).
- Cas 1 : il ne peut y avoir double participation d'une occurrence de A à R1 et R2 (cas précédent).
- Cas 2 : étant donné une participation de A à R1, il ne peut y avoir participation de A à R2 ; par contre, si A participe à R2, il n'y a pas d'exclusivité de participation à R1.
- Cas 3 : étant donné une participation de A à R2, il ne peut y avoir participation de A à R1 ; par contre, si A participe à R1, il n'y a pas d'exclusivité de participation à R2.
On peut préciser graphiquement ces trois cas (voir figure 7.29).
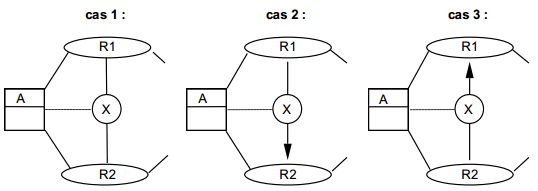
II-D-3-r-ii. Simultanéité de participations d'une entité à plusieurs relations▲
Toute occurrence de l'entité type participe de façon simultanée à deux (ou plusieurs) relations types. On l'exprime par une contrainte S.
Par exemple, une commande portant sur des articles est obligatoirement passée par un client et réciproquement (voir figure 7.30).
 |
|
Par rapport à l'entité commande, les relations passer et porter sont simultanées. |
La cardinalité mini = 0 de COMMANDE dans PASSER signifie que certaines commandes ne sont pas passées par des clients (commandes internes). La cardinalité mini = 0 de COMMANDE dans PORTER signifie que des commandes peuvent porter sur autre chose que des articles (des prestations par exemple).
II-D-3-r-iii. Totalité de participations d'une entité à plusieurs relations▲
Soit une entité type participant à deux (ou plusieurs) relations types, toute occurrence de l'entité participe au moins à une des relations. On l'exprime par une contrainte T.
Par exemple, tout véhicule est au minimum relié soit à un contrat par la relation couvrir, soit à un sinistre par la relation impliquer, soit les deux (voir figure 7.31).
II-D-3-r-iv. Exclusivité et totalité de participations d'une entité à plusieurs relations (Partition)▲
Le cas de la partition est en fait un cumul des contraintes d'exclusivité X et de totalité T. On l'exprime par une contrainte XT.
Soit une entité type commande participant à deux relations types passer et provenir ; toute occurrence de l'entité commande participe soit à la relation passer, soit à la relation provenir (voir figure 7.32).
II-D-3-r-v. Inclusion de participations d'une entité à plusieurs relations▲
Soit une entité type participant à deux (ou plusieurs) relations types R1 et R2, toute occurrence de l'entité participant à la relation R1 participe à la relation R2. On l'exprime par une contrainte I, dont l'émetteur est la relation R1 et la cible la relation R2 (flèche vers R2).
Par exemple, une personne qui effectue un prêt doit avoir souscrit un abonnement (voir figure 7.33).
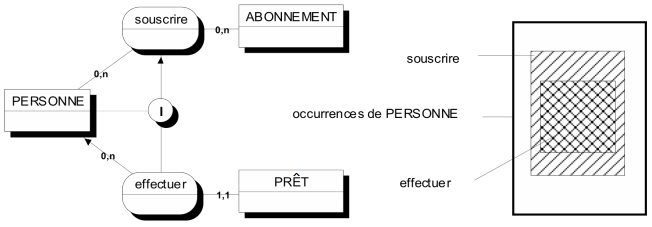 |
|
Par rapport à l'entité personne, la relation effectuer est incluse dans la relation souscrire. |
II-D-3-s. Contraintes sur la participation de plusieurs entités à plusieurs relations▲
Ces contraintes permettent d'exprimer des conditions d'existence d'occurrences de relations types selon la présence ou l'absence de participations à d'autres relations types ayant des entités communes dans leur collection. Il s'agit d'une généralisation des contraintes présentées précédemment ; l'ensemble de référence n'est plus limité à une entité type, mais à des n-uples d'entités. Nous allons étudier différentes situations pouvant se présenter, comme l'illustre la figure 7.34.
II-D-3-s-i. Contraintes d'inclusion de relations sur d'autres relations▲
Il y a contrainte d'inclusion, relativement à des entités citées, d'une relation R1 dans une relation R2, si la participation des occurrences des entités citées aux occurrences de la relation R1 implique la participation des occurrences de ces entités aux occurrences de la relation R2. On l'exprime par une contrainte I dont l'émetteur est la relation R1 et la cible la relation R2.
Par exemple, tout professeur qui enseigne une matière à ses classes est qualifié pour cette matière. On a ici une contrainte d'inclusion de la relation enseigner sur la relation qualifier, que l'on modélisera comme sur la figure 7.35.
 |
|
Par rapport aux entités MATIERE et PROFESSEUR, la relation ENSEIGNER est incluse dans la relation QUALIFIER. |
II-D-3-s-ii. Contraintes d'exclusivité de relations sur d'autres relations▲
Il y a contrainte d'exclusivité, relativement à des entités citées, d'une relation R1 et d'une relation R2, si la participation des occurrences des entités citées aux occurrences de la relation R1 exclut la participation des occurrences de ces entités aux occurrences de la relation R2. On l'exprime par une contrainte X.
Par exemple, une personne ne peut pas être locataire et propriétaire d'un même logement (voir figure 7.36).
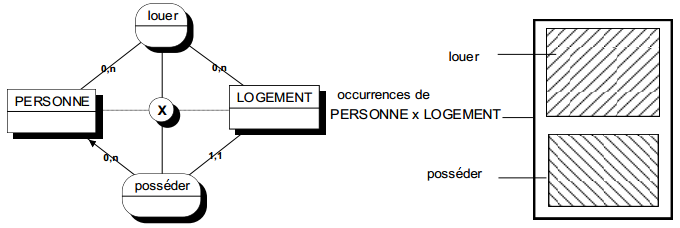 |
|
Par rapport aux entités LOGEMENT et PERSONNE, les relations louer et posséder sont mutuellement exclusives. |
On pourrait également avoir des contraintes sur la participation de plusieurs entités à plusieurs relations de type OU exclusif (contrainte XT), OU inclusif (contrainte T)…
La figure 7.37 présente un exemple plus élaboré de contraintes (cas de la société X).
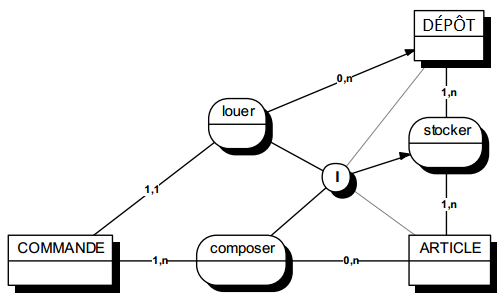 |
|
Par rapport aux entités article et dépôt, quand un article entre dans la composition d'une commande, et que cette commande concerne un dépôt, alors cet article est obligatoirement stocké dans ce dépôt. |
II-D-3-t. Contrainte sur les occurrences de relations ayant des entités communes▲
II-D-3-t-i. Identité d'occurrences d'entités impliquées via des relations distinctes (égalité)▲
Soit une entité I1 reliée indirectement à une entité I2 par des relations binaires fonctionnelles formant des cheminements distincts. Pour toute occurrence de I1, l'occurrence de I2 obtenue par l'un des cheminements est identique à celle obtenue par l'autre cheminement. On l'exprime par une contrainte E.
Par exemple, pour toute occurrence de commande, l'occurrence de client donneur d'ordre de la commande (relation passer) est toujours identique à l'occurrence de client propriétaire (relation posséder) du dépôt auquel doit être livrée (relation livrer à) la commande.
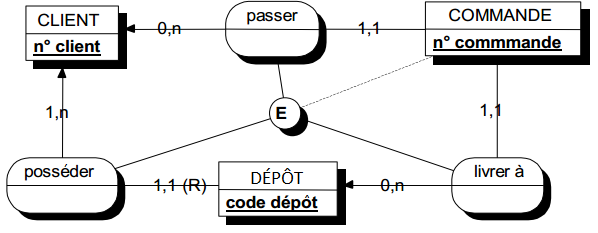
II-D-3-u. Récapitulatif des contraintes interrelations▲
Voir tableau de la figure 7.39.
Les exemples peuvent être généralisés à plusieurs entités ; la phrase explicative devient : Si (toute) occurrence d'un n-uple des entités I1, I2… participe…
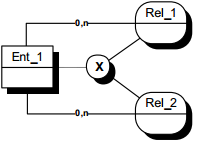 |
EXCLUSIVITÉ |
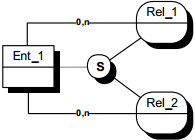 |
SIMULTANÉITÉ |
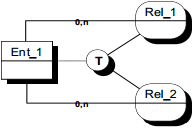 |
TOTALITÉ |
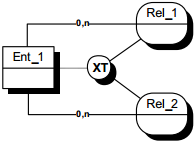 |
EXCLUSIVITÉ et TOTALITÉ |
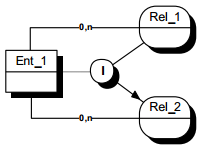 |
INCLUSION |
II-D-3-v. Contraintes de stabilité▲
Les contraintes présentées jusqu'ici sont de type statique. Il s'avère nécessaire d'introduire de nouvelles contraintes permettant d'exprimer la stabilité du modèle de données. Ces contraintes concernent principalement :
- la « stabilité » des valeurs des propriétés dans le temps ;
- le rattachement et le détachement d'occurrences d'entités via des occurrences de relations dans le temps.
Ces contraintes s'appliquent en fonctionnement normal, pour l'utilisateur courant du système ou pour un développeur standard d'application client/serveur. On peut toujours envisager qu'un administrateur dûment habilité puisse, sous certaines conditions à préciser, s'affranchir de ces contraintes pour rectifier un dysfonctionnement.
II-D-3-w. Contraintes de stabilité liées aux propriétés▲
II-D-3-w-i. Propriété stable (S)▲
Une propriété est dite stable si, étant donné une occurrence de l'entité ou de la relation décrite par cette propriété, la première valeur attribuée à cette propriété ne peut être ultérieurement modifiée.
On conviendra qu'une valeur d'initialisation à NULL n'est pas une valeur significative. En conséquence, cette valeur pourra être ultérieurement modifiée en valeur significative définitive.
Tout identifiant, même composé, doit, par définition, être stable.
II-D-3-x. Contraintes de stabilité liées aux relations▲
II-D-3-x-i. Patte de relation définitive (D)▲
Une patte de relation est définitive si une occurrence de la relation ne peut être supprimée que par et seulement par la suppression simultanée de l'occurrence correspondante de l'entité impliquée dans la patte de relation.
La notation graphique est un (D) porté par la patte concernée (voir figure 7.40).
Rappelons que, par définition, on ne peut pas parler de modification de la collection d'une occurrence d'une relation ; il s'agit en fait d'une suppression d'une occurrence de la relation suivie de la création d'une nouvelle occurrence de la relation ; la collection d'une relation joue en fait le rôle d'identification de la relation et, comme l'identifiant d'une entité, n'est pas modifiable.
Avec une patte définitive, on ne peut pas supprimer les occurrences de la relation autrement que par la suppression de l'occurrence de l'entité de la patte définitive. En conséquence, on ne peut supprimer une occurrence des autres entités de la collection de la relation (pattes non définitives) tant qu'il reste des occurrences de la relation où intervient l'occurrence à supprimer.

Dans une commande fournisseur donnée, on ne peut supprimer une ligne qu'en supprimant simultanément la commande. On ne peut évidemment pas changer d'article (modification de collection, donc supprimer une ligne pour en créer une autre). En conséquence, on ne peut supprimer une occurrence d'article (donc supprimer les occurrences de la relation liées) tant qu'il existe des lignes où intervient cet article ; ou alors, supprimer simultanément toutes les commandes qui utilisent cet article… ! On peut par contre ajouter quand on veut des lignes de commande à une commande existante.

Un contrat ne concerne définitivement qu'un et un seul assuré ; un contrat ne peut donc, dans le temps, changer d'assuré concerné.
II-D-3-x-ii. Patte de relation verrouillée (V)▲
Une patte de relation est verrouillée si, étant donné une occurrence de l'entité reliée par cette patte, toutes les occurrences de la relation dans lesquelles cette occurrence de l'entité intervient, sont créées en même temps que l'occurrence de l'entité. Ultérieurement, on ne peut ni ajouter ni supprimer une occurrence de la relation impliquant cette occurrence d'entité. Cette contrainte lie ainsi la création des occurrences d'une relation à la création des occurrences d'une entité de sa collection.
La notation graphique est un (V) porté par la patte concernée (voit figure 7.41).
Une patte verrouillée est par définition définitive.

Cette contrainte est encore plus « stabilisante » que la contrainte de patte définitive.
On a rendu totalement dépendant statiquement et dynamiquement l'entité et la relation.
II-D-3-y. Identifiant relatif▲
Toute entité type doit être dotée d'un identifiant et nous avons évoqué la difficulté d'inventer de telles propriétés. Certaines entités types ont par ailleurs une existence totalement dépendante d'autres entités types. On peut alors avoir recours à un identifiant relatif.
L'identification relative s'effectue :
- par une propriété stable de cette entité (qui ne remplit pas les conditions d'un identifiant absolu) dite identifiant relatif ;
- via une relation binaire porteuse d'une dépendance fonctionnelle obligatoire (c'est-à-dire cardinalité 1,1) vers une entité dite de référence ; cette patte doit également être définitive.
On note l'identification relative par (R) sur la patte servant de relativité. Dans l'exemple de la figure 7.42, l'identifiant de la ligne de commande est donc n° ligne relatif à commande (ex. ligne n° 2 de la commande n° 5432).

L'identification relative n'est pas un identifiant composé, car certaines propriétés constituant l'identification n'appartiennent pas à l'entité ainsi identifiée ; il est par ailleurs exclu de dupliquer des propriétés à fin d'identification. Enfin, l'identifiant relatif sera traité de façon particulière au niveau logique.
L'identification relative peut se propager à plusieurs niveaux, à travers des relations types binaires fonctionnelles obligatoires.
L'identification relative peut être multiple et s'exprimer à travers plusieurs relations (voir figure 7.43).
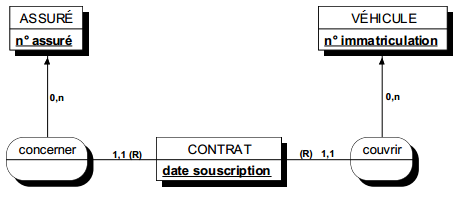
Dans certains cas d'identification relative multiple, la présence d'identifiant relatif n'est pas obligatoire ; l'identification de l'entité s'effectue alors par la composition des identifiants des entités de référence (voir figure 7.44). Dans l'exemple, une telle situation pourrait inciter à modéliser la notion de Dossier comme une relation, surtout si elle n'était pas impliquée elle-même dans une autre relation. Toutefois, le caractère d'objet concret d'intérêt pour l'utilisateur du Dossier l'emporte sur la « faiblesse » d'identification ; ainsi, une telle entité est parfois qualifiée d'entité faible.
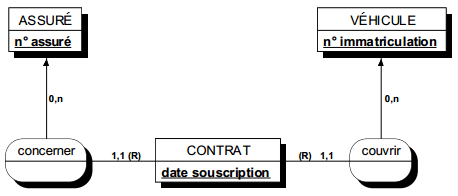
II-D-3-z. Décomposition d'une relation type▲
Si les relations binaires sont effectivement très nombreuses dans les modèles conceptuels de données (dues à la propension naturelle des concepteurs à simplifier leur perception), l'usage de relations n-aires s'avère parfois nécessaire.
Cependant, lorsque des dépendances fonctionnelles sont définies sur une relation n-aire, une décomposition de cette relation en plusieurs relations de dimension moindre est envisageable. Cette décomposition présente deux intérêts ; elle permet d'une part de mieux matérialiser certaines des dépendances fonctionnelles et d'autre part, en réduisant la dimension des relations, de les rendre plus facilement interprétables.
La décomposition de relations n-aires dotées de dépendances fonctionnelles répond à une condition préalable :
- Le nombre d'entités concernées par la dépendance fonctionnelle doit être inférieur à la dimension de la relation.
L'opération de décomposition de la relation consiste à :
Modéliser une relation dont la collection comprend les entités types impliquées dans la dépendance fonctionnelle ; cette relation est porteuse de la dépendance fonctionnelle.
Sortir de la collection initiale de la relation l'entité cible de la dépendance fonctionnelle (familièrement « couper la patte » de cette entité).
Affecter les cardinalités de la nouvelle relation :
- L'entité cible (sortie de la collection initiale) conserve les cardinalités qu'elle avait dans la relation initiale.
- Si la relation est binaire, la cardinalité mini de l'entité émettrice est celle qu'elle avait dans la relation initiale ; la cardinalité maxi est 1.
- Si la relation est de dimension supérieure à 2, les cardinalités des entités émettrices sont celles qu'elles avaient dans la relation initiale.
Les éventuelles propriétés restent rattachées à la relation initiale.
Outre le principe général de décomposition, ci-dessus présenté, il faut préciser certaines situations particulières :
- Si les entités émettrices de la dépendance fonctionnelle ont une cardinalité mini égale à 1, alors la décomposition est systématique.
- Si les entités émettrices de la dépendance fonctionnelle ont une cardinalité mini égale à 0, alors le concepteur ne procédera à la décomposition que s'il s'est assuré que les deux relations types issues de la décomposition ont une existence liée [Tabourier 86].
- Si une autre relation type, porteuse d'une dépendance fonctionnelle, partage une partie de la collection de la relation type à décomposer, le concepteur doit, auparavant, s'assurer que la relation type issue de la décomposition et porteuse d'une dépendance fonctionnelle est ou non assimilable à la relation type déjà exprimée.
Les figures 7.45 à 7.47 présentent différents exemples de décompositions.
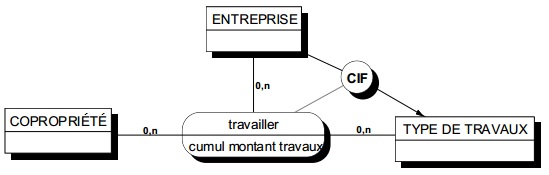 |
|
Dépendance fonctionnelle : dans le cadre de la relation travailler, chaque entreprise n'effectue qu'un type de travaux. |
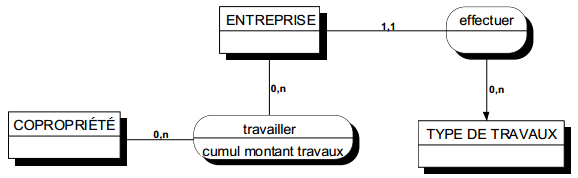 |
Une cardinalité maxi à 1. dans une relation n-aire implique, par définition, des dépendances fonctionnelles.
 |
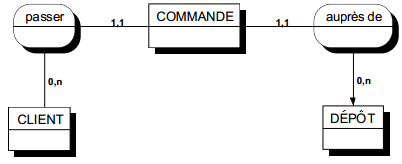 |
Dans le cas d'une cardinalité (0,1)., il est nécessaire d'ajouter une contrainte de simultanéité S (figure 7.47 a).
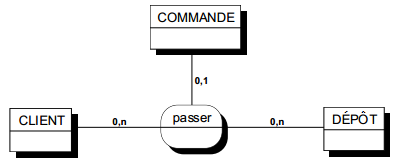 |
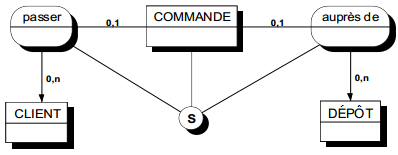 |
Prenons enfin l'exemple d'une décomposition complexe où l'on procédera par étapes.
Au départ, un contrat d'assurance souscrit par un assuré concerne, en cas de risque auto, un assuré et un véhicule, ou seulement un assuré en cas d'autres risques (figure 7.47 b) :
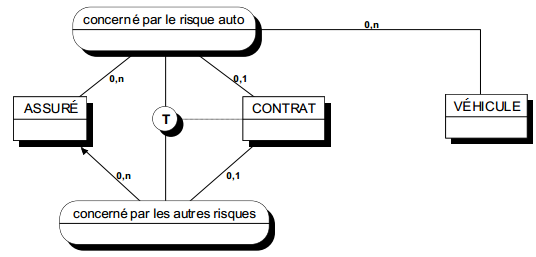
Étape 1 : on va décomposer la relation ternaire disposant d'une cardinalité (0,1).
Cette relation ternaire se décompose en deux relations binaires reliées par une contrainte de simultanéité. On choisit de conserver le nom initial pour la relation avec ASSURE, et l'on renomme COUVRIR la relation avec VEHICULE (Figure 7.47 c).
La contrainte de totalité T se reporte sur les relations décomposées.
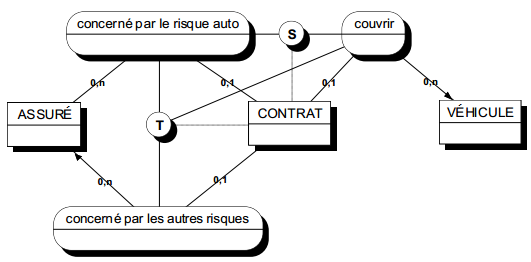
Étape 2 : on va fusionner les relations « concerné par le risque auto » et « concerné par les autres risques » munies d'une contrainte de totalité T.
Ces deux relations ont la même collection et des significations pouvant être considérées comme similaires. On fusionne ces deux relations sous le nom de CONCERNER dont la cardinalité par rapport à CONTRAT devient (1,1) — la cardinalité mini 0 se transforme en 1, la contrainte de totalité T disparaît (Figure 7.47 d).
La sémantique initiale est conservée. Tout contrat est concerné par un assuré et un seul, certains couvrent un véhicule :
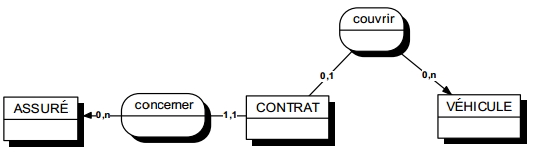
II-D-4. Compléments sur le formalisme entité-relation▲
Les notions ci-après comprennent d'une part des enrichissements introduits progressivement dans le formalisme entité - relation, d'autre part des compléments et réflexions issus de la pratique.
II-D-4-a. Règles▲
Jusqu'à présent, dans la méthode Merise, les règles de traitement étaient usuellement rattachées aux traitements où elles s'effectuaient. Cette description des règles dans le cadre des traitements était largement influencée par la situation d'une informatisation où les règles étaient, en général, mises en œuvre dans les programmes. Depuis ces dernières années, et particulièrement avec le développement du client/serveur, on assiste progressivement à la définition et à la mise en œuvre de certaines règles au niveau des données.
D'ores et déjà, certaines contraintes sont définies au niveau du modèle conceptuel de données : cardinalités, contraintes interrelations, contraintes de stabilité, historisation. Ces contraintes ou règles ont d'une part la même permanence que les entités, relations et propriétés du MCD, et d'autre part sont indépendantes du contexte d'utilisation par tel ou tel traitement.
On peut distinguer deux catégories de règles :
- Les règles de traitement qui restent spécifiques et contingentes à une ou certaines activités, c'est-à-dire conséquentes aux événements qui déclenchent l'activité (opération, tâche, ULT). Ces règles sont formalisées au niveau de la modélisation des traitements (organisationnel ou logique).
- Les règles de traitement qui sont indépendantes de toute activité (opération, tâche, ULT) spécifique et qui doivent être appliquées au niveau des données pour maintenir une cohérence globale.
Dans tous les cas, une règle s'exprime sur des données qui interviennent comme termes de l'algorithmique. Aussi, nous proposons de définir les règles au niveau du modèle conceptuel de données afin de garantir la cohérence entre l'expression de la règle et les données impliquées. Bien que définies au niveau des données, ces règles pourront toujours être utilisées au niveau des traitements (cf. Chap. 8Chapitre 8 Modélisation organisationnelle des traitements).
L'expression des règles de traitement dans un modèle conceptuel de données comporte :
- le nom de la règle ;
- la description de l'algorithmique (sous la forme de français structuré ou pseudocode) ;
- les entités, relations et propriétés utilisées par la règle.
La figure 7.48 illustre la représentation graphique d'une règle (un rectangle à coin corné) et des propriétés utilisées par la règle (des pointillés) [Morejon 94].
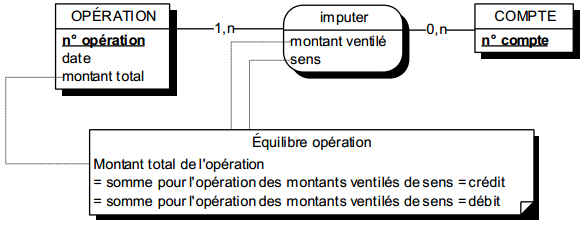
II-D-4-b. Modélisation du temps▲
Le modèle conceptuel de données est, par nature, statique. Or, le concepteur désire parfois intégrer des informations liées au temps. Cette apparente antinomie entre temps et statique pose des problèmes à certains concepteurs.
II-D-4-c. Propriété à valeurs calendaires▲
De nombreuses propriétés se réfèrent au temps, par exemple : date de livraison, mois d'échéance, année d'exercice.
Dans ce cas-là, ces propriétés suivent exactement les mêmes règles que les autres propriétés. Il n'y a aucune justification, au niveau conceptuel, à les modéliser d'une façon particulière (voir figure 7.49).
II-D-4-d. Modélisation de la chronique des valeurs d'une propriété▲
Parfois, le concepteur est confronté à la modélisation de propriétés présentant une série chronologique de valeurs : chiffre d'affaires mensuel, production quotidienne. Dans un tel cas, le temps devient une véritable dimension qu'il convient donc de modéliser explicitement comme une entité (voir figure 7.50).
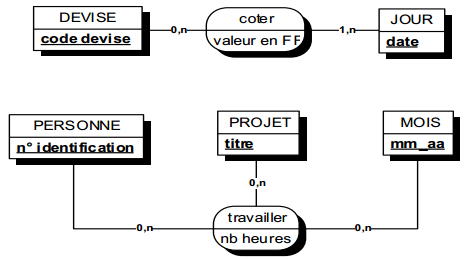
Il faut réserver cette modélisation aux séries chronologiques, c'est-à-dire les cas où les valeurs de la propriété sont régulièrement échelonnées dans le temps. On utilise fréquemment cette modélisation explicite d'une entité temporelle dans les domaines de suivi d'activités.
II-D-4-e. Historisation▲
Pour certaines propriétés, ou pour l'ensemble des propriétés d'une entité ou d'une relation, le concepteur désire parfois conserver, en cas de modification, les valeurs antérieures prises par ces propriétés, pour la même occurrence de l'entité ou de la relation de rattachement ; c'est-à-dire « historiser » les valeurs des propriétés. Dans ce cas-là, la règle de vérification (non-répétitivité des valeurs) serait théoriquement enfreinte et ces propriétés ne devraient pas être ainsi modélisées (elle est certes vérifiée pour la valeur présente, mais les valeurs antérieures créent une multiplicité). Par ailleurs, on ne peut pas véritablement considérer la liste des valeurs successives comme une série chronologique par manque de régularité dans l'échelle de temps.
Les évolutions du formalisme proposent donc d'indiquer explicitement le caractère historisable au niveau d'une propriété, d'une entité ou d'une relation.
II-D-4-e-i. Datation et profondeur▲
L'historisation de valeurs antérieures est précisée par deux caractéristiques
- La datation indique l'instant auquel chaque valeur antérieure a été historisée ; elle s'assimile à un compostage des valeurs historisées. La précision de la datation peut s'exprimer dans différentes unités de temps : jour-heure, jour, semaine, mois, année. Si deux changements de valeurs interviennent dans la même unité de datation, alors il n'y pas d'historisation, mais une simple modification de la valeur courante.
- Exemple : on choisit d'historiser les valeurs de la propriété adresse d'une personne avec une datation du mois. Une seconde modification de l'adresse dans le même mois ne provoque pas d'historisation de la première, mais est considérée comme une correction de la valeur précédente.
- La profondeur d'un historique indique le nombre de valeurs antérieures que l'on souhaite conserver ; cette profondeur peut être illimitée.
L'indication du caractère historisable peut rester facultative en étude préalable, mais devient impérative en étude détaillée. Datation et profondeur ne sont généralement précisées qu'au niveau de la modélisation organisationnelle des données (voir Quantification).
II-D-4-e-ii. Propriété historisée▲
La conservation des valeurs antérieures (historisation) ne s'applique qu'à certaines propriétés d'une entité ou d'une relation. Graphiquement, on indique alors le caractère historisable par un (H) au niveau de la propriété (voir figure 7.51).
II-D-4-e-iii. Entité historisée▲
Pour toute modification de valeur de l'une des propriétés d'une entité, on historise l'ensemble des valeurs des propriétés de l'entité. Graphiquement, on indique alors le caractère historisable par un (H) au niveau de l'entité (voir figure 7.52).

II-D-4-e-iv. Relation historisée▲
Pour toute modification de valeur de l'une des propriétés d'une relation, on historise l'ensemble des valeurs des propriétés de la relation. Graphiquement, on indique alors le caractère historisable par un (H) au niveau de la relation (voir figure 7.53).

II-D-4-e-v. Patte de relation historisée▲
Pour tout changement d'occurrence de l'entité constituant la patte d'une relation, on historise la valeur antérieure de l'identifiant de l'entité concernée. Graphiquement, on indique le caractère historisable par un (H) au niveau de la patte de la relation (voir figure 7.54).
 |
|
D'une part, un assuré peut être présent dans plusieurs dossiers, d'autre part, on conserve les changements de dossiers successifs de l'assuré. |
Il ne faut pas confondre historisation et archivage. L'historisation concerne l'évolution des valeurs des informations d'une même occurrence. L'archivage aborde la question de la durée de vie des occurrences dans la mémoire immédiate.
Ainsi, à une échéance fixée, on archivera des données qui, en règle générale, ne sont jamais concernées par une historisation.
II-D-4-f. Liste variable de propriétés▲
Une règle appliquée aux entités types préconise que toutes les propriétés d'une entité type aient une signification pour toutes les occurrences. Or, dans quelques cas, certaines propriétés ne peuvent suivre cette règle. Pour tenter de résoudre ce problème, nous proposons les solutions suivantes.
II-D-4-f-i. Accepter que ces propriétés n'aient pas de pertinence pour certaines occurrences de l'entité.▲
Cette solution n'est praticable que si le nombre de propriétés impliquées est limité. D'autre part, ce problème peut avoir des répercussions au niveau physique.
La figure 7.55 illustre cette solution. L'entité SALARIE présente la propriété « nom marital », qui n'a de sens que pour la population des salariées féminines.
On l'utilise si le nombre de propriétés concernées est limité, et l'entité stable et d'intérêt pour le domaine.

Expliciter les sous-populations évoquées par ces propriétés : modélisation en termes de sous-types.
Cette solution consiste à modéliser autant de sous-types que de sous-populations utilisant de façon pertinente les propriétés concernées (voir figure 7.56).
Remarque : On reconnaît ici la notion de spécialisation.
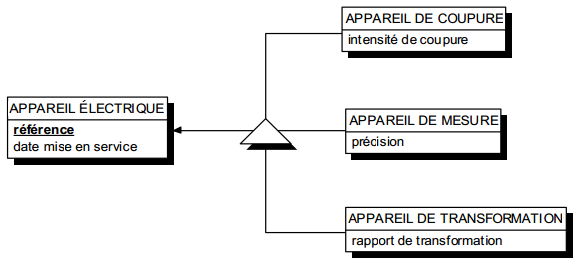
On utilise cette modélisation si les sous-populations sont stables et en nombre limité, et si les propriétés descriptives des sous-types sont stables.
II-D-4-f-ii. Modéliser les propriétés en tant qu'occurrences d'entités types : métamodélisation▲
Cette solution, appelée également métamodélisation, consiste à exprimer l'un des types de concept (ici la propriété) dans son propre formalisme (voir figure 7.57).
On modélise ainsi une entité type appelée par exemple Caractère, dont les occurrences sont les propriétés concernées ; on établit une relation type entre cette entité type Caractère et l'entité type initiale que l'on a par ailleurs dépouillée des propriétés concernées. Les valeurs prises par les propriétés initiales de l'entité sont désormais des valeurs d'une propriété appelée valeur et rattachée à la relation.
On utilise cette modélisation en cas de grande variabilité de propriétés, de sous-populations évolutives.
Ce type de modélisation apporte une très grande flexibilité, mais peut avoir par ailleurs des inconvénients. Aussi convient-il de ne l'utiliser qu'en maîtrisant la modélisation.

II-D-4-g. Propriétés à valeurs codées▲
Il s'agit de propriétés dont la valeur s'exprime par un code (numérique ou alphanumérique, mnémonique ou non) associé à un libellé explicatif.
Exemples :
-
Civilité :
- 1 = Monsieur
- 2 = Madame
- 3 = Mademoiselle
-
Type de véhicule
- CY = cyclomoteur
- MT = moto
- VL = véhicule léger
- PL = poids lourd
- RQ = remorque
En règle générale, au niveau conceptuel, il est recommandé de modéliser ce type de propriété comme les autres propriétés classiques, c'est-à-dire de les rattacher à leur entité naturelle (sans tenir compte de l'aspect code + libellé). On peut si nécessaire recourir à un type utilisateur spécifique.
Par contre, on déconseille formellement, au niveau conceptuel, de modéliser ce type de propriété par une entité à part, ne comprenant que le code et le libellé, reliée par une relation binaire fonctionnelle à son entité naturelle d'origine. Une telle modélisation conduit :
- à créer des entités dont la pertinence et la consistance sont contestables ;
- à vider de leur substance les entités d'origine ;
- à démultiplier le nombre d'entités et de relations parasitant la lisibilité du modèle au détriment d'entités plus pertinentes.
On doit toutefois recourir à la modélisation sous forme d'entité propre lorsque la notion exprimant la propriété à valeur codée (généralement un type de…) intervient de façon autonome, en particulier dans des relations avec d'autres entités.
Ces propriétés à valeurs codées seront spécifiquement prises en compte lors du passage au modèle logique de données.
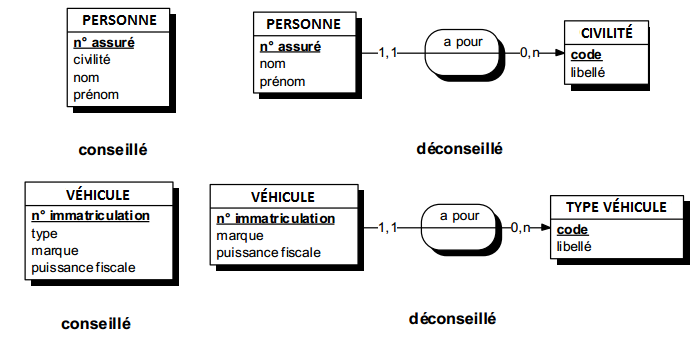
II-D-5. Construction d'un modèle conceptuel de données▲
Rappelons que le concepteur procédera deux fois à l'élaboration d'un modèle conceptuel de données : lors de l'étude préalable, puis lors de l'étude détaillée. Il est certain que, dans le cadre d'une étude préalable, le concepteur accordera plus d'importance à la structure du modèle (entités et relations) qu'aux propriétés.
La construction d'un modèle conceptuel de données ne s'effectue jamais d'un seul trait. C'est un processus itératif, d'enrichissement progressif, qui trouve souvent son origine dans une alternance avec l'étude des traitements.
Dans tous les cas, on retrouvera ces principes généraux de construction :
- Chercher d'abord à modéliser les entités types qui apparaissent le plus naturellement, puis s'intéresser aux relations.
- Dès que l'on modélise une entité type, chercher à lui affecter un identifiant, ou du moins l'illustrer par des exemples d'occurrences.
- Éviter absolument de réfléchir en termes de fonctionnement (ou traitement) ; s'astreindre à exprimer des « faits ».
- À chaque propriété affectée à une entité type ou à une relation type, s'assurer immédiatement de la règle de vérification (non-répétitivité).
- S'assurer que toutes les entités types participent au moins à une relation type.
- Préciser les cardinalités mini et maxi de chaque entité dans chaque relation.
- Rechercher, au sein de chaque relation type, les éventuelles dépendances fonctionnelles ; procéder, si les conditions le permettent, à la décomposition.
- Exprimer les éventuelles contraintes interrelations.
- Exprimer les éventuelles règles de traitement.
- Régulièrement, relire globalement le modèle afin de vérifier si les futures utilisations envisagées sont prises en compte.
La modélisation conceptuelle des données a pour objectif premier d'exprimer et formaliser les concepts métier perçus dans le discours du domaine étudié, dans un formalisme qui permettra ultérieurement une traduction vers les structures de bases de données. C'est le respect de cet objectif qui préservera son pouvoir d'expression et de communication avec les interlocuteurs du métier.
On ne peut que regretter une pratique constatée sur le terrain qui tend à transformer le MCD en une expression de la future base de données formalisée en entité-relation. Cette pratique conduit à introduire au niveau conceptuel, des modélisations, des solutions et des choix qui n'ont leur place qu'au niveau logique, détournant ainsi le MCD de son objectif premier.
II-D-6. Expression d'un modèle conceptuel de données▲
Bien que des présentations puissent être adaptées au contexte d'utilisation, évoquons les principaux éléments composant la présentation d'un modèle conceptuel de données :
- Représentation graphique du modèle (schémas). Notons que la lecture des modèles peut être facilitée par la présentation en plusieurs schémas partiels (par thème, avec propriétés, avec contraintes…) et un schéma intégral limité aux éléments structurels.
- Pour chaque entité, description (succincte ou détaillée suivant le niveau d'étude).
-
Pour chaque relation, description :
- de la collection des entités,
- des cardinalités,
- des propriétés affectées,
- des éventuelles dépendances fonctionnelles et contraintes logiques interrelations,
- de l'éventuelle historisation.
- Éventuellement, pour chaque propriété, description de sa signification.
- Pour chaque règle, sa description et les propriétés utilisées.
II-D-7. Comment communiquer à partir d'un modèle conceptuel de données▲
Dans la modélisation d'un système d'information existant, comme en conception d'un futur système, le modèle conceptuel des données constitue un outil de synthèse précieux pour l'équipe de projet.
On peut aussi souhaiter l'utiliser comme outil de communication avec d'autres intervenants : le responsable utilisateur, l'utilisateur final ou l'administrateur de bases de données. Comment, concrètement, présenter un MCD en dehors de l'équipe de projet ? Sous quelles conditions ?
Un modèle conceptuel de données est un document technique, souvent difficile à comprendre pour des personnes non formées. Pour un échange bénéfique avec vos interlocuteurs, en particulier les utilisateurs, il faut d'abord expliquer le but du document, puis les notions représentées, en procédant du plus simple au plus complexe, et en le reliant à ce qu'ils connaissent (attention ! Il ne s'agit pas de faire un cours sur le formalisme).
On parviendra à une bonne communication en associant trois descriptions cohérentes complémentaires :
- Une définition et un exemple de chaque notion élémentaire (il s'agit de définir entité ou relation par un texte court et des exemples simples).
- Des schémas très lisibles du MCD réduits à l'essentiel (rapprocher les notions dont les significations sont voisines et limiter le nombre de croisements des pattes du modèle, faire des présentations de schémas partiels où ne figurent que peu de concepts).
- Un texte de liaison en français (il permet de parcourir l'ensemble du MCD selon un scénario raisonnable).
La conjonction du dessin et du texte favorise une bonne compréhension du MCD qui constituera ainsi un outil de communication efficace.
II-E. Chapitre 8 Modélisation organisationnelle des traitements▲
II-E-1. Problématique du modèle organisationnel de traitements (MOT)▲
II-E-1-a. Définition de solutions d'organisation▲
Le modèle conceptuel de traitements a permis de décrire les activités majeures du domaine, sans référence aux ressources nécessaires pour en assurer le fonctionnement ; on s'est concentré sur le quoi et le pourquoi. La construction du modèle organisationnel de traitements se concentre sur le comment et va consister à :
- Définir les différentes ressources à mettre en œuvre (ce terme ressource est très général et concerne aussi bien des moyens techniques ou humains, de l'espace, du temps et des données).
- Décomposer les opérations spécifiées au niveau conceptuel en des éléments plus fins et homogènes : les tâches.
- Construire un enchaînement chronologique des activités.
- Organiser l'ensemble des ressources permettant d'assurer l'exécution des tâches envisagées.
En résumé, il s'agit de spécifier avec plus de détails le contenu de chaque opération conceptuelle dont l'expression des tâches était jusqu'ici très sommaire et de construire une ou plusieurs solutions d'organisation.
À la différence des modèles conceptuels (données ou traitements), l'élaboration d'un modèle organisationnel ne présente pas de difficulté théorique, liée à l'effort d'abstraction. Par contre l'extrême diversité des solutions d'organisation envisageables ou le niveau de détail nécessaire rendent cette phase parfois délicate.
La construction d'un MOT nécessite un important effort de la part de l'équipe de projet, pour plusieurs raisons.
Une solution d'organisation doit préciser au minimum :
- l'organisation prévue pour les utilisateurs, avec les différents postes de travail et/ou services ;
- la circulation des informations entre ces centres d'activités ;
- dans les postes de travail, les différentes tâches à réaliser et selon quelle chronologie.
Le niveau de détail de cette description doit tenir compte de l'étape en cours (étude préalable ou étude détaillée), mais il doit toujours permettre une compréhension immédiate pour un futur utilisateur.
Il y a en général plusieurs solutions possibles ; chaque solution doit être décrite comme précédemment (variantes).
Chaque solution d'organisation doit aussi être évaluée selon quatre types de critères :
- Critères économiques (la solution à évaluer est-elle plus efficiente que la solution actuelle ? Les coûts et les délais associés restent-ils acceptables pour l'organisation ?).
- Critères techniques (la variante à évaluer est-elle réalisable avec les technologies utilisées dans l'entreprise ou disponibles sur le marché ?).
- Critères ergonomiques (les tâches prévues sont-elles bien adaptées aux futurs utilisateurs ?).
- Critères d'ordre social (la solution envisagée est-elle conforme aux orientations de l'entreprise en matière de personnel ? Quel serait son impact en matière d'emploi et de qualifications ? Cette solution est-elle acceptable par les futurs utilisateurs ?).
La construction des variantes du MOT pose ainsi tout le problème du changement dans l'entreprise. Ce n'est pas un problème purement technique ; il est donc important, en respectant les choix de l'entreprise, de favoriser une approche ouverte de ce changement, approche sociotechnique et participative.
II-E-1-b. Répartir un système d'information▲
Cette problématique de l'organisation et du changement suppose un minimum de complexité du système d'information : les données, les traitements et les ressources ne sont pas tous réunis en un lieu géographique unique ; ils sont au contraire répartis ou à répartir de nouveau.
La distinction faite entre SIO (système d'information organisationnel) et SII (système d'information informatisé) conduit à une double répartition selon la figure 8.1 :
- Une répartition entre des unités organisationnelles de l'entreprise : dans quels établissements, services ou postes de travail sont exercées les activités de l'entreprise ? Avec quelles ressources humaines et techniques ?
- Une répartition entre des sites informatiques : où sont localisés les différents matériels utilisés ? Par quels réseaux sont-ils reliés ? Quels fichiers ou bases de données supportent-ils ? Où sont les ressources technologiques ? (voir, en troisième partie, les chapitres 12Chapitre 12 Modélisation Logique des Traitements et 13Chapitre 13 Modélisation Logique des Données).
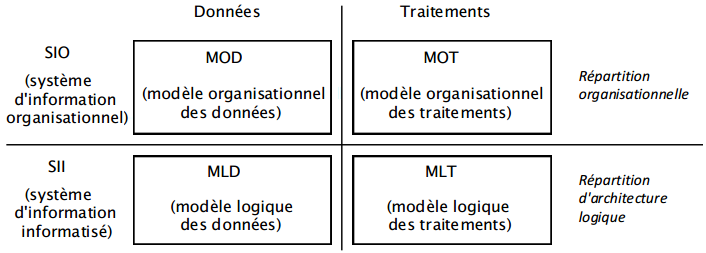
La répartition organisationnelle est visible pour les utilisateurs de l'entreprise. La répartition technologique peut n'être visible que pour les informaticiens.
II-E-1-c. Répartition organisationnelle▲
Nous traiterons dans ce chapitre la répartition organisationnelle des traitements à l'aide des modèles organisationnels de traitements ou MOT (pour les données mémorisées, voir au chapitre 10 les modèles organisationnels de données ou MODProblématique du modèle organisationnel de données (MOD)).
Cette répartition mettra d'abord en évidence des centres d'activité organisationnels, les postes de travail, dans lesquels seront réalisées les différentes activités.
Un poste de travail mobilise des ressources humaines et des ressources informatiques ; il faudra donc préciser pour chaque poste de travail et chaque tâche la part assurée par l'homme et celle assurée par la machine.
II-E-2. Formalisme de modélisation des traitements au niveau organisationnel▲
Malgré son importance en matière de conception de système d'information organisationnel, le MOT ne nécessite pas de formalisme spécifique ; il reprend très largement les concepts du MCT, parfois réadaptés et enrichis, auxquels sont ajoutés de nouveaux concepts, dont celui de poste de travail.
II-E-2-a. Le poste de travail▲
Le poste de travail type, ou poste type, constitue l'une des principales dimensions du modèle organisationnel. Un poste type est un centre d'activité élémentaire du domaine comprenant tout ce qui est nécessaire à l'exécution de traitements. Pour spécifier un poste type, on décrit :
- Les compétences et aptitudes requises par les personnes intervenant dans ce poste type.
- Les caractéristiques techniques des matériels associés à ce poste. Bien qu'aucune restriction n'existe, le matériel informatique retiendra davantage l'attention du concepteur. Notons qu'à ce niveau, il s'agit d'une description très générale sans rentrer dans des spécifications techniques de tel ou tel matériel.
- L'aménagement général du poste et sa localisation dans l'espace.
Un poste type peut, selon les cas, comprendre :
- Une personne associée à un matériel ; par exemple, pour le poste secrétariat d'admissions d'une clinique, une secrétaire médicale, un clavier et un écran.
- Plusieurs personnes partageant un matériel ; par exemple le poste réception comptoir d'un magasin, trois vendeurs, un clavier, un écran, un lecteur marques magnétiques (code à barres), un imprimante.
- Une ou plusieurs personnes sans matériel ; par exemple le poste aire de stockage d'un magasin : cinq manutentionnaires.
- Du matériel sans personnel spécialisé ; par exemple le poste « Lecteur de badge horaire flexible ».
Un poste type peut se matérialiser par plusieurs occurrences sur le terrain qui ont, par définition, le même comportement. Par exemple, le poste type secrétariat d'admissions est en trois exemplaires.
La détermination et le choix d'un poste doivent avant tout tenir compte des compétences des personnes affectées : un poste traduit un niveau de responsabilité des personnes qui conditionnera les tâches qui leur seront confiées. Le découpage en postes exprime en partie l'organisation des structures de décision du système de pilotage. La description des compétences et responsabilités d'un poste se traduit parfois par le profil d'un poste. Les postes sont formalisés graphiquement sous la forme de colonnes dans lesquelles sont représentées les tâches réalisées au sein des postes. Selon différents usages, des colonnes complémentaires peuvent accueillir :
- Les acteurs externes et leurs échanges (événements et résultats) avec les postes.
- L'échelle de temps de la chronologie des tâches.
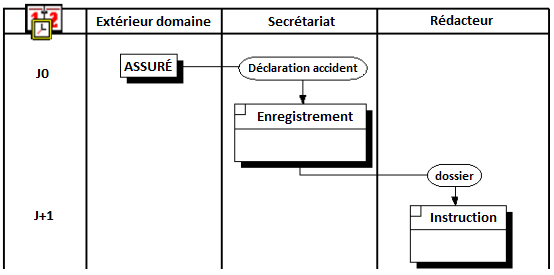
II-E-2-b. L'événement/résultat-message▲
Les concepts d'événement et de résultat (type et occurrence) sont les mêmes qu'au niveau conceptuel. Par ailleurs, tous les événements et résultats externes décrits dans le modèle conceptuel de traitements doivent se retrouver dans le modèle organisationnel, éventuellement sous une forme plus détaillée.
Exemples :
L'événement Demande client du MCT pourra se transformer, dans le MOT, en la succession d'événements suivants :
- Demande initiale.
- Demande modifiée.
L'événement Remise chèque du MCT pourra se transformer, dans le MOT, en la décomposition d'événements (sous-type d'événement) suivants :
- Chèque sur place de notre banque.
- Chèque sur place d'une autre banque.
- Chèque hors place de notre banque.
- Chèque hors place d'une autre banque.
On trouvera aussi plus fréquemment dans le MOT des événements temporels liés au rythme de l'entreprise et qui représentent des échéances. Ces événements échéances n'ont pas d'acteur émetteur explicite (il s'agit en théorie de programmation effectuée par le système de pilotage) :
- Début / fin de mois.
- Début / fin de journée.
- Chaque jour à 11h30.
- Le 25 du mois.
À ces événements périodiques peuvent s'ajouter des événements décisionnels qui représentent le déclenchement de tâches à l'initiative explicite des représentants du système de pilotage (fréquemment l'exécutant de la tâche) :
- Décision de relancer.
- Sur demande.
À la différence du MCT, dans un MOT, la présence d'un événement formalisant le déclenchement d'une tâche n'est pas obligatoirement représentée sur le schéma ; en particulier lorsque deux tâches s'enchaînent dans le même poste, la fin de la première tâche déclenchant immédiatement la seconde. Par contre, tout changement de poste ou de phase (voir plus loin « La phase ») doit faire apparaître un message (ou un état) qui assure la transmission de l'activité.
Dans le modèle organisationnel, on accordera plus d'importance au contenu des messages en décrivant la liste et la structure des informations (surtout lors de l'étude détaillée). Cet aspect de description des données, associé aux traitements, sera étudié plus en détail lors de la validation, sous l'appellation de modèle externe ou vue externe.
II-E-2-c. L'état▲
La modélisation des états reste la même qu'au niveau conceptuel ; toutefois, les états sont plus fréquemment formalisés au niveau MOT.
Ils expriment des situations du système d'information, plus particulièrement au niveau des données mémorisées, et constituent :
- soit des conditions préalables à une tâche ;
- soit des situations résultantes conditionnelles d'une tâche.
Ils permettent entre autres de répartir dans des procédures organisationnelles différentes des activités qui sont en fait dépendantes l'une de l'autre ; l'état résultant d'une tâche étant l'état préalable d'une autre.
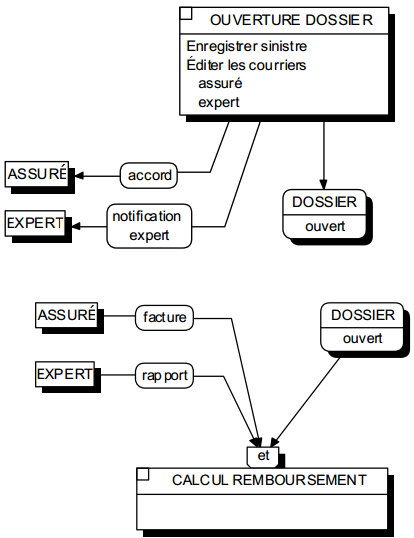
Rappelons que l'expression de l'état d'un objet peut provenir :
- de la valeur d'une propriété ad hoc de l'objet (entité ou relation) ;
- d'une règle de traitement impliquant des propriétés de l'objet, voire toute une structure de données liées à cet objet ; dans ce dernier cas, on sera en présence d'un sous-schéma de données associé à la définition d'un état.
Dans un MOT, les états se comportent comme des événements et résultats qui permettent de préciser les conditions du fonctionnement des procédures organisationnelles, l'enchaînement des tâches restant l'objectif principal de cette modélisation.
On peut par ailleurs envisager un autre type de modélisation privilégiant l'enchaînement des états successifs d'un même objet, conditionné par des événements et des transformations (activités). Cet autre angle de vue de la dynamique d'un système d'information représente le cycle de vie de l'objet (voir Chapitre 9 : « Cycle de vie des objetsCycle de vie des objets »).
II-E-2-d. La tâche▲
La tâche type modélise un ensemble nommé d'activités élémentaires, perçues comme homogènes, concourant à un même but.
La symbolisation graphique de la tâche reprend celle de l'opération et des concepts secondaires associés définis au niveau conceptuel : synchronisation, description et conditions d'émission.
La tâche peut également être perçue comme la décomposition d'une opération conceptuelle. Par exemple, la figure 8.4 montre la décomposition en tâches de l'opération conceptuelle Ouverture dossier.
La décomposition organisationnelle ne reconduit pas nécessairement la liste et l'ordre des fonctions élémentaires composant l'opération. Au contraire, le travail du concepteur consiste à imaginer de nouveaux découpages et assemblages d'activités élémentaires, ainsi que des enchaînements et répartitions adaptées aux ressources des postes. La figure 8.9 présente une procédure organisationnelle basée sur une autre décomposition de l'opération conceptuelle d'Ouverture dossier.
II-E-2-e. Caractères organisationnels▲
La tâche type est caractérisée par les paramètres suivants :
Le poste type auquel la tâche est affectée. Une tâche est intégralement assurée dans un poste type. Cette affectation est unique ; on peut toutefois parler de tâches similaires si des activités quasi identiques sont exécutées dans des postes différents. L'affectation d'une tâche à un poste se modélise en représentant la tâche dans la colonne du poste correspondant.
Le degré d'automatisation de la tâche. Par abus de langage, et par rapport à l'objectif de la méthode, seule l'informatisation sera prise en compte.
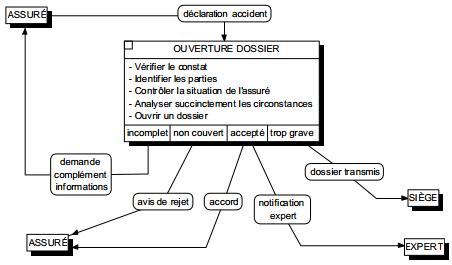 |
|
décomposé en |
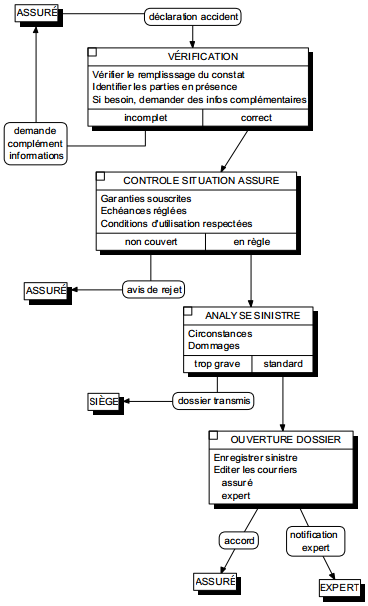 |
Le poste disposant de deux types de ressources, humaine et informatique, le degré d'automatisation traduit l'utilisation de ces ressources pour l'exécution de la tâche. On distingue ainsi trois degrés d'automatisation :
- Une tâche peut être manuelle (M) ; durant son déroulement, seule la ressource humaine est mobilisée. Par exemple, le contrôle de la déclaration d'accident, la recherche des articles dans les rayons, etc.
- Une tâche peut être interactive (I) ou conversationnelle (C) ; durant son déroulement, les ressources humaine et informatique sont mobilisées. Par exemple, la saisie d'un sinistre, l'enregistrement d'une commande.
- Une tâche peut être automatique (A) ; durant son déroulement, seule la ressource informatique est mobilisée. L'intervention humaine pour le lancement ou la récupération des résultats de la tâche ne remet pas en cause le caractère automatique, car la ressource humaine n'est pas impliquée dans l'activité même de la tâche. Par exemple, le calcul de la quittance, l'édition des relevés.
-
Le délai de réponse de la tâche. Ce délai exprime la rapidité de prise en compte d'une nouvelle occurrence d'événement, à condition que l'ensemble des ressources nécessaires à l'exécution de la tâche soient disponibles. On distingue deux valeurs :
- Réponse immédiate (I) ; dès la survenance de l'événement et si les ressources sont disponibles, la tâche traite l'événement.
-
Réponse différée (D) ; le déclenchement de la tâche n'est pas uniquement lié à la survenance de l'événement, mais attend une condition complémentaire — délai, intervalle de temps, un ordre du pilote, généralement programmé (la fin de journée, le début du mois…). Les occurrences de l'événement attendent ce top extérieur qui permettra à la tâche de les traiter.
Le mode de fonctionnement de la tâche. Comment prend-elle en compte les différentes occurrences d'événement présentes ? Ce mode de fonctionnement peut prendre deux valeurs :
-
Unitaire (U) ; la tâche et les ressources associées traitent les occurrences d'événement une par une. À la fin de la tâche, les ressources libérées redeviennent disponibles soit pour prendre une nouvelle occurrence en attente sur la même tâche, soit pour permettre à une autre tâche de démarrer.
- Par lot (L) ; la tâche et les ressources associées prennent en charge un lot (dont la taille est à préciser) et restent mobilisées jusqu'à la fin du traitement du lot.
L'évaluation du caractère unitaire ou par lot doit s'effectuer par référence à l'occurrence définie pour l'événement en entrée de la tâche.
Des caractères tels que la périodicité, la fréquence et la durée peuvent venir compléter la description organisationnelle de la tâche.
À l'exception du degré d'automatisation, ces caractéristiques organisationnelles peuvent être optionnelles en étude préalable.
II-E-2-f. Description d'une tâche▲
La tâche est décrite par l'ensemble des activités homogènes à réaliser et comporte entre autre :
- Des règles de traitements exécutées par la tâche. Une règle de traitement consiste à décrire, sous une forme structurée, un algorithme appliqué à un ensemble de données.
- Des actions effectuées par la tâche sur des données mémorisées, constituant un sous-schéma de données. Ces actions, de mise à jour ou de consultation, mettent en jeu les informations présentes sur les messages, les informations impliquées dans les règles de traitement et les informations déjà mémorisées représentées par un sous-schéma du MCD ou du MOD.
- Des choix et décisions effectués par l'utilisateur lors de l'exécution de la tâche.
Suivant le degré de détail souhaité, le concepteur peut représenter une tâche soit au sein d'une procédure organisationnelle (figure 8.10) sans détailler la description, mais en privilégiant enchaînement au sein des postes, soit en « gros plan » avec l'expression de la description, des règles et du sous-schéma (figure 8.5).
II-E-2-g. La règle de traitement▲
Une règle de traitement est un ensemble structuré sous une forme algorithmique :
- d'expressions logiques ;
- d'expressions arithmétiques ;
- d'actions.
L'introduction explicite des règles de traitement dans l'expression du contenu des tâches s'est effectuée très tôt dans la méthode Merise sans disposer pour cela de formalisation. L'isolement et la réutilisation des règles dans le processus de développement informatique ont rendu progressivement nécessaire l'expression autonome de règles de traitement nommées, conduisant à la constitution de répertoires de règles. Ce phénomène a été particulièrement sensible dans les domaines à forte composante réglementaire (administration, assurance, banque…).
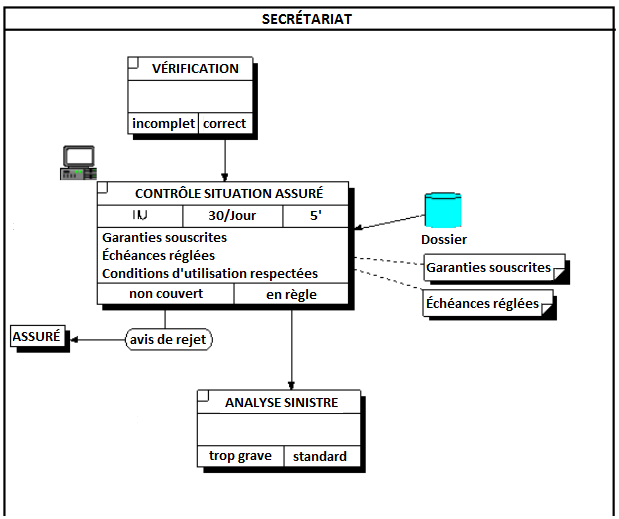
Comme nous l'avons déjà expliqué dans la modélisation conceptuelle des données (voir « Règles » dans MCD), on peut distinguer deux catégories de règles :
- Des règles de traitement spécifiques et contingentes à une ou certaines activités, c'est-à-dire conséquentes aux événements qui déclenchent l'activité. Ces règles sont à formaliser au niveau de la modélisation des traitements (organisationnel ou logique).
- Des règles de traitement indépendantes de toute activité spécifique et qui doivent être appliquées au niveau des données pour maintenir une cohérence globale. Ces règles de traitement sont décrites au niveau du modèle conceptuel de données.
Dans la description des traitements appliqués par une tâche, on peut utiliser les deux catégories de règles. La figure 8.5 illustre la représentation graphique des règles Garanties souscrites et Échéances réglées utilisées par la tâche Contrôle situation assuré.
Le contenu détaillé de la règle peut être exprimé sous forme de langage structuré (naturel ou pseudocode) où peuvent apparaître :
- des propriétés du modèle de données présentes dans le sous-schéma de données ;
- des règles de traitements, permettant ainsi une construction arborescente des règles de traitement avec possibilité de réutilisation de règles élémentaires.
On peut en outre établir une typologie des règles de traitement selon leur nature (surtout pour les règles élémentaires), par exemple : calcul, contrôle, sélection, sommation.
La mise en évidence des règles de traitement et leur modélisation autonome dès le modèle organisationnel favorisera leur implémentation informatique ultérieure.
II-E-2-h. Le sous-schéma conceptuel/organisationnel de données▲
Un sous-schéma conceptuel/organisationnel de données (voir figure 8.6) est un sous-ensemble, généralement connexe, d'entités types et de relations types, définies sur le modèle conceptuel de données (MCD) ou le modèle organisationnel de données (MOD), associé à une tâche. Cette tâche effectue des actions (mise à jour ou lecture) sur les occurrences de ces entités et relations.
Sur le schéma d'un MOT, le sous-schéma (ou vue de données) apparaît seulement par son nom, associé à une icône. Les actions sur l'entité pivot (voir Confrontation données traitements) peuvent être éventuellement symbolisées avec les conventions suivantes.
Certains auteurs détaillent explicitement le sous-schéma et les actions, ce qui nous semble surcharger la représentation graphique d'un MOT.
 |
 |
Plusieurs tâches différentes peuvent partager un même sous-schéma conceptuel/organisationnel de données, avec éventuellement des actions différentes.
On peut également associer un sous-schéma à une procédure organisationnelle, à une phase, voire à une règle de traitement ou un état.
II-E-2-i. Les ressources▲
Le formalisme préconisé par Merise, au niveau organisationnel des traitements, ne propose pas explicitement de modélisation et de représentation graphique des ressources utilisées, de leur disponibilité et de leur consommation.
Cependant, le formalisme des réseaux de Petri (base théorique de la modélisation des traitements dans Merise) permettrait de représenter cette disponibilité et consommation d'une ressource, en la modélisant sous un concept au comportement équivalent à celui d'un événement/résultat, avec de préférence un symbole différent. Certains praticiens de Merise utilisent depuis plusieurs années cette formalisation (voir figure 8.7).
Il est certain que les consommations de ressources par les tâches du MOT permettent une approche du dimensionnement technique et organisationnel (effectif et charges de travail des ressources humaines, caractéristiques des ressources techniques).
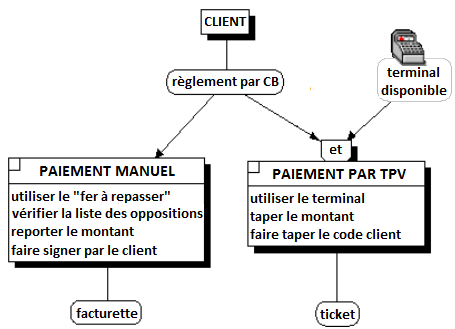
II-E-2-j. La phase▲
La phase est une succession de tâches exécutées consécutivement au sein d'un même poste. Dès qu'une occurrence d'événement rentre dans la phase, c'est-à-dire déclenche la première tâche de cette phase, les ressources humaine et informatique nécessaires à l'exécution de ces tâches restent mobilisées et indisponibles (même si elles ne sont pas utilisées par certaines tâches) jusqu'à la fin du traitement de l'occurrence d'événement initial (cette sortie pouvant survenir à l'issue de toute tâche de la phase) ; la phase pourra alors traiter une nouvelle occurrence d'événement. La figure 8.8 illustre un exemple de regroupement en phase.
La phase permet de reconstituer une séquence d'activités qui ne peuvent être interrompues par d'autres événements. Le découpage en tâches au sein de la phase est alors fréquemment dû à une alternance de degrés d'automatisation différents.La notion de phase est intéressante à plusieurs titres :
- Elle permet une meilleure analyse de l'utilisation optimale des ressources dans le cas où certaines ressources ne sont pas mobilisées tout au long de la phase.
- Elle offre un découpage des rythmes de travail au sein du poste.
- Elle met en évidence des points d'attente entre les phases, en particulier entre les postes de travail, qui risquent de générer des files d'attente.
Si des tâches consécutives au sein d'une phase sont de mêmes caractéristiques (par exemple Automatisée, Immédiat), il est possible de regrouper ces tâches en une seule et même tâche.
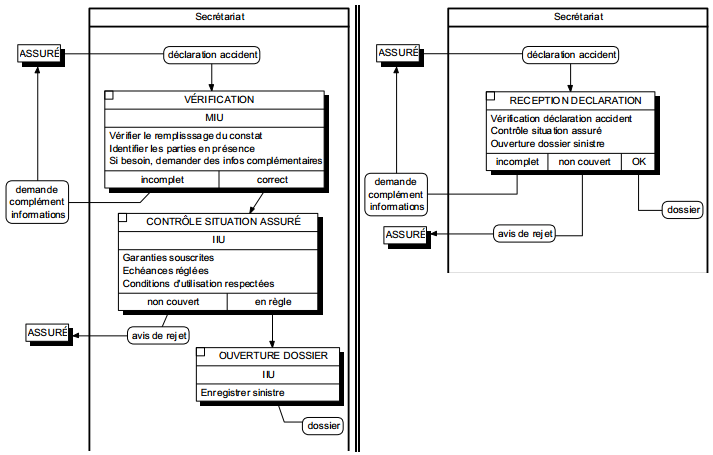
II-E-2-k. La procédure organisationnelle▲
C'est un enchaînement de tâches et/ou de phases, d'intérêt pour l'organisation. La procédure organisationnelle prend en compte un événement type (ou plusieurs synchronisés), appelé événement initial de la procédure, et produit tous les résultats types qui en découlent.
Procédures, phases et tâches permettent d'introduire de façon naturelle une modularité dans la présentation du MOT.
Il arrive qu'un événement type présente en fait plusieurs variantes.
Par exemple, la demande de passeport recouvre les deux cas suivants : demande d'un premier passeport, demande de renouvellement.
Selon le cas, le déroulement de la procédure sera différent ; certaines tâches ne seront pas exécutées, ou seront exécutées selon des règles différentes.
On parle alors de variantes différentes de la procédure ; on précise souvent la fréquence de ces variantes (40 % en première délivrance, 60 % en renouvellement).
II-E-2-l. Représentation graphique d'un modèle organisationnel de traitements▲
Cette représentation reprend largement les diagrammes de circulation bien connus des organisateurs. En pratique, la présentation de la modélisation organisationnelle des traitements s'effectue à travers les différents schémas de procédures, exprimés en phases ou tâches selon le degré de détail souhaité. La figure 8.9 présente un schéma MOT associé à la procédure d'Ouverture d'un dossier de sinistre du cas assurance.
II-E-2-m. Organisation synchrone ou asynchrone▲
Dans la modélisation organisationnelle des traitements, l'enchaînement entre les tâches est un aspect important de l'expression de la procédure organisationnelle. La modélisation de ces enchaînements peut s'effectuer de diverses manières qui, chacune, traduisent des fonctionnements différents.
Au sein d'une phase, l'enchaînement entre deux tâches se modélise par un simple lien fléché (pas d'événement ou d'état intermédiaire), exprimant ainsi la continuité des activités dans la phase (non interruptible).
Par contre, lorsque l'enchaînement s'effectue entre des tâches appartenant à des phases différentes (au sein d'un même poste ou entre des postes distincts), l'enchaînement doit être formalisé par l'intermédiaire soit d'un événement, soit d'un état. Le choix de l'une ou l'autre modélisation exprimera un fonctionnement synchrone ou asynchrone de la procédure.
Dans le cas d'un fonctionnement synchrone, modélisé par un événement (quel que soit son support), l'événement émis par l'une des tâches vient « stimuler » l'autre tâche qui la prendra en compte généralement immédiatement (si ses ressources sont disponibles). Le rythme de fonctionnement de la tâche réceptrice est totalement synchronisé par celui de la tâche émettrice.
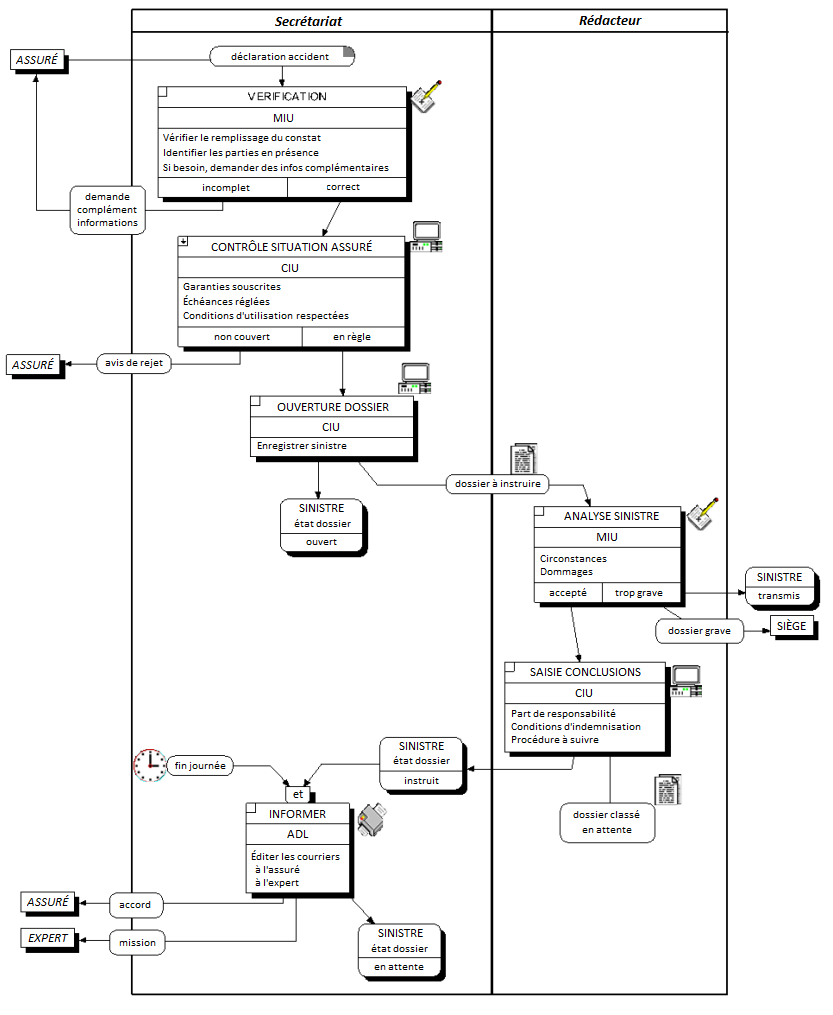
Par exemple, dans la figure 8.9, le concepteur a choisi un fonctionnement synchrone entre la tâche Ouverture dossier au secrétariat et la tâche Analyse du sinistre du rédacteur. L'enchaînement est donc modélisé par un événement, matérialisé ici par la transmission du dossier à instruire. Le rédacteur sera immédiatement averti qu'un dossier est à instruire ; normalement il devrait traiter dans la séquence le dossier communiqué (un tel choix d'organisation est bien évidemment discutable).
Dans le cas d'un fonctionnement asynchrone, la tâche émettrice produit en résultat un état qui est repris en entrée de la tâche réceptrice, synchronisé par un événement temporel ou décisionnel ; à la différence de l'événement, l'état n'a aucun rôle de stimulus. Le rythme de fonctionnement de la tâche réceptrice est totalement désynchronisé par rapport à celui de la tâche émettrice ; la tâche réceptrice doit prendre l'initiative du déclenchement des traitements.
Toujours dans la figure 8.9, le concepteur a choisi un fonctionnement asynchrone entre la tâche Saisie des conclusions et la tâche Informer l'assuré et l'expert. L'enchaînement est modélisé par un état, matérialisé par Sinistre état dossier instruit. La tâche Informer qui prendra en compte ces dossiers sera déclenchée à l'initiative du secrétariat, en l'occurrence en fin de journée.
Dans le cas d'une modélisation de fonctionnement asynchrone, il n'est pas nécessaire de faire obligatoirement figurer l'enchaînement entre les tâches. On retrouve alors la même problématique que celle évoquée au niveau des MCT entre l'approche orientée processus et l'approche orientée états.
Le choix d'une organisation synchrone ou asynchrone relève également des préoccupations du B.P.R. et trouve aujourd'hui un écho particulier dans les nouvelles approches de « workflow ».
II-E-2-n. Notions complémentaires pour la formalisation organisationnelle des traitements▲
Les concepts de base présentés suffisent généralement pour construire un modèle organisationnel de traitements. Toutefois, certaines situations à modéliser rendent nécessaires des éléments complémentaires tels que :
- La fréquence d'un événement, fréquence de survenance des occurrences de cet événement. Elle peut être constante (100 commandes/jour) ou variable (loi de distribution dans le temps).
- La capacité d'un événement, nombre maximum d'occurrences qu'un événement type peut accepter. Par défaut, cette valeur est infinie.
- La participation d'un événement à une synchronisation, nombre d'occurrences différentes de l'événement nécessaires au déclenchement de la synchronisation. Par défaut cette valeur est 1, une valeur typique est tous.
- La durée de contribution d'un événement à une synchronisation, temps d'attente maximum entre la survenance de l'événement et sa consommation par la tâche ; au-delà, cette occurrence d'événement disparaît. Par défaut, cette valeur est infinie. Une valeur typique est 0, indiquant que l'événement doit survenir en dernier si l'on veut démarrer la tâche.
- Des conditions locales d'une synchronisation, expression logique portant sur les valeurs des messages permettant de sélectionner des occurrences d'événements devant participer à la synchronisation.
- La durée limite de synchronisation, temps maximum d'attente entre la survenance du premier événement contributif et l'activation de la synchronisation. Si ce délai est dépassé, toutes les occurrences d'événements en attente sur cette synchronisation sont purgées.
- Le délai de synchronisation, temps passé entre le moment où la condition est vraie et le moment où la tâche est déclenchée. Par défaut, cette valeur est 0.
- La durée de la tâche, temps passé entre le déclenchement de la tâche et la production de résultat. Cette durée peut être variable suivant les conditions d'émission des résultats.
- La périodicité de la tâche, période ou cycle de répétition d'une tâche. Par exemple : quotidienne, hebdomadaire, mensuelle, annuelle.
- La duplication d'un résultat, nombre d'occurrences identiques d'un résultat émis par la tâche. Par défaut, cette valeur est 1.
Les notions de fréquence, de périodicité et de durée sont essentielles, et dès l'étude préalable, il est nécessaire de les connaître avec une précision suffisante. On indiquera pour chaque estimation la valeur minimale, la valeur maximale et la valeur la plus probable. Bien entendu ces estimations devront être cohérentes avec la quantification établie pour le modèle organisationnel des données (voir MOD).
II-E-3. Construction d'un modèle organisationnel de traitements▲
Par deux fois, le concepteur procédera à l'élaboration d'un modèle organisationnel : lors de l'étude préalable, puis lors de l'étude détaillée. Il faut noter cependant la grande différence d'attitude dans la modélisation, selon les deux étapes d'étude :
- En étude préalable, le concepteur doit s'attacher à proposer une variété de solutions par le choix des postes, du degré d'automatisation et de l'organisation des tâches. Le concepteur ne doit pas, par contre, s'attarder à détailler le contenu des tâches ou des messages.
- En étude détaillée, les principes organisationnels ont été fixés, il reste au concepteur à détailler le contenu des tâches et des messages, à expliciter toutes les procédures même secondaires.
Dans tous les cas, on retrouvera des principes généraux de construction que nous résumons :
- Faire le choix des postes, en spécifiant les ressources humaines et informatiques.
- Décomposer chaque opération en tâches, les ordonner (le nouvel enchaînement des tâches n'est pas nécessairement celui des fonctions de l'opération), les affecter aux postes, préciser les différentes caractéristiques (degré d'automatisation, délai de réponse, mode de travail).
- S'assurer de la faisabilité des tâches par rapport aux ressources composant le poste.
- Préciser les différentes phases.
- Évaluer l'ergonomie générale de chaque poste par rapport à l'ensemble des phases à assurer ; évaluer si la nature des tâches assignées est compatible avec les qualifications des personnes affectées au poste, avec les conditions générales de l'environnement.
- Envisager des solutions alternatives : variantes de procédures.
II-E-4. Expression d'un modèle organisationnel de traitements▲
Du point de vue de la documentation, pour exprimer les solutions d'organisation (variantes du MOT), on présentera les éléments suivants :
- description des postes ;
- schéma d'enchaînement des tâches présenté par procédure organisationnelle ;
- suivant la nécessité, présentation de quelques variantes de la procédure ;
- liste des phases par poste ;
-
pour chaque tâche, description (succincte ou détaillée suivant le niveau de l'étude) ;
- des événements et états en entrée ;
- des règles de traitement exprimées en termes d'algorithme ;
- du sous-schéma conceptuel ou organisationnel de données ;
- des actions effectuées sur les données mémorisées ;
- des résultats et états produits ;
- des conditions de production de ces résultats.
Plus largement, ces solutions d'organisation doivent être présentées aux gestionnaires et aux utilisateurs du domaine, selon des modalités adaptées à l'entreprise.
Cette présentation permettra une évaluation et si nécessaire une amélioration des solutions envisagées, mais aussi une sensibilisation des personnels aux changements liés à la future organisation du travail.
Cela suppose bien entendu une préparation sérieuse de ces présentations, et un temps suffisant de parole pour les gestionnaires et les utilisateurs, leur permettant de formuler leurs observations, critiques et suggestions :
- sur le contenu et la désignation des postes de travail, des tâches et des messages ;
- sur le déroulement des tâches dans le temps, sans oublier les principaux cas particuliers ;
- sur les différentes variantes présentées ; comment satisfont-elles les exigences ergonomiques et techniques, sociales et économiques ?
II-E-5. Modularité dans un modèle organisationnel de traitements▲
Comme pour le MCT, il est nécessaire de pouvoir représenter un MOT sous une forme globale ou sous une forme détaillée.
Au niveau organisationnel, nous optons pour la technique de stratification (voir chapitre 3 « Niveaux d'abstraction et degrés de détailsNiveaux d'abstraction, couverture du domaine étudié et degré de détail »), qui consiste à définir des modèles avec des concepts types différenciés. Notre expérience nous conduit à utiliser trois niveaux de détail : modèle organisationnel de procédures, modèle organisationnel de phases, modèle organisationnel par tâches.
Dans chaque type de modèle, l'activité (la procédure, la phase, la tâche) est représentée par le symbole classique de l'activité.
Le modèle organisationnel de procédures permet une vision très macroscopique : seuls figurent sur le schéma les procédures et leurs enchaînements avec, pour chacun, le ou les événements initiaux et les résultats qui en découlent. On retient comme critère organisationnel la répartition en postes et un degré très global d'automatisation (essentiellement manuel, essentiellement transactionnel, essentiellement automatisé…). Pratiquement, une telle modélisation est assez proche du degré de détail d'un MCT courant auquel on adjoint certains aspects organisationnels. Ce degré de modélisation peut être utilisé avec profit pour l'analyse de l'existant (voir chapitre 15 « Analyse du modèle organisationnel actuelAnalyse du modèle organisationnel actuel »). On peut appeler ce type de modèle Macro-MOT.
Le modèle organisationnel de phases permet une vision intermédiaire du fonctionnement organisé : seuls figurent sur le schéma les phases et leurs enchaînements avec, pour chacun, le ou les événements initiaux et les résultats qui en découlent. Comme pour le modèle de procédures, on exprime la répartition par poste et le degré global d'automatisation. L'intérêt d'un tel modèle réside dans l'unité de temps et de mobilisation des ressources exprimée par la phase, qui permet de formaliser les rythmes de fonctionnement. Cette modélisation offre un degré intermédiaire très apprécié dans les présentations des solutions organisationnelles.
Le modèle organisationnel de tâches est une vision relativement détaillée : elle seule permet cependant de préciser la nature exacte et homogène des activités organisées ainsi que leurs enchaînements. D'après notre expérience, ce niveau de modélisation est le plus approprié, même au niveau de l'étude préalable, pour élaborer des solutions organisationnelles, quitte à le présenter ensuite sous la forme d'un modèle de phases. Ce modèle est, par contre, indispensable au niveau de l'étude détaillée, pour préparer le passage au niveau logique.
II-E-6. Ergonomie et modèles organisationnels de traitements▲
Pour analyser ou concevoir un système d'information, il ne suffit pas d'avoir une bonne approche technique pour obtenir un système performant, c'est-à- dire sûr, maniable et minimisant les risques d'erreur humaine.
Comme pour tous les systèmes complexes (nucléaire, navigation aérienne, industrie chimique), il faut de plus en plus prendre en compte la qualité de l'interface homme-machine, c'est-à-dire la dimension ergonomique.
Dans le cadre de cet ouvrage, nous ne traiterons pas en détail cet aspect fondamental de l'ergonomie. Nous nous limiterons à évoquer les questions principales que le concepteur doit se poser :
- Comment analyser l'activité réelle d'un opérateur au travail ?
- Comment définir les interfaces de dialogue d'un logiciel ?
- Comment évaluer l'ergonomie d'un logiciel ou d'un progiciel préexistant ?
Nous renvoyons le lecteur à des études et livres traitant de l'ergonomie en général [Guelaud et al. 75] [Laville 81] [Sperandio 84] [De Moulin 86] ou spécialisés en ergonomie du logiciel comme [Valentin & Lucongsang 87] dont nous nous inspirerons largement.
II-E-6-a. Introduction à l'ergonomie du logiciel▲
L'ergonomie peut être définie comme l'ensemble des connaissances scientifiques relatives à l'homme et nécessaires pour concevoir des outils, des techniques et des dispositifs qui puissent être utilisés avec le maximum de confort, de sécurité et d'efficacité.
Les principales caractéristiques de l'ergonomie sont :
- la nécessité de connaissances interdisciplinaires (physiologie, psychologie, sociologie, ingénierie, médecine…) ;
- l'effort de prise en compte de la globalité d'une situation de travail (contenu des tâches, environnement, organisation, formation…) ;
- l'analyse du travail réel effectué par les opérateurs.
Plus précisément, l'ergonomie du logiciel a pour objectif de permettre une meilleure adéquation des applications informatiques aux besoins des utilisateurs.
En ingénierie de systèmes d'information, nous intégrerons les considérations ergonomiques :
- au niveau organisationnel à travers l'analyse des postes ;
- au niveau logique à travers la conception des interfaces homme-machine.
II-E-6-b. L'analyse du travail▲
En ergonomie du logiciel, un certain nombre de techniques, d'éléments méthodologiques ont été proposés afin de guider l'ergonome. Son travail sera tout d'abord centré sur une analyse du travail regroupant une analyse de la tâche et une analyse de l'activité [Valentin & Lucongsang 87].
Lors de l'analyse de la tâche, l'ergonome recueillera des éléments sur l'organisation du travail, les liens entre les services, les caractéristiques des postes de travail et il précisera surtout le contenu du travail prescrit dans le cadre de cette tâche. Il précisera ainsi les objectifs à atteindre, les procédures et les règles de fonctionnement que l'utilisateur est censé utiliser.
Ensuite, au travers de l'analyse de l'activité, l'ergonome s'efforcera de comprendre comment l'utilisateur travaille ou travaillera réellement à son poste de travail pour réaliser cette tâche prescrite. Une observation fine permettra de relever les aspects de l'activité qui conditionnent le plus la réalisation de la tâche. Elle consistera entre autres à identifier les informations et les ressources nécessaires au déroulement de la tâche, leur ordre d'utilisation, les informations manquantes, inutilisées, les repères principaux permettant à l'utilisateur de prendre ses décisions, ainsi que les erreurs, oublis constatés.
L'ergonome peut ensuite effectuer une synthèse, en comparant les données recueillies lors des analyses de tâche et d'activité. En cherchant les raisons des écarts observés entre le prescrit et le réalisé, il fera ressortir des points critiques dans le fonctionnement de l'application sur le poste de travail.
Pour conclure, nous dirons que l'ergonomie n'est pas un vernis supplémentaire ajouté à un logiciel classique par ailleurs ; c'est une autre façon d'étudier et de comprendre le travail humain, en particulier pour concevoir de nouveaux systèmes plus souples et mieux adaptés aux utilisateurs.
Le logiciel n'est pas le tout du travail de l'entreprise ; pour le travail de production administrative quotidienne, même sans informatique, l'ergonomie peut apporter beaucoup en matière de conditions de travail au sens large, comme en matière d'efficacité. Il est important de situer les efforts en ergonomie du logiciel dans la perspective d'ensemble de l'amélioration de la performance de l'entreprise. S'il est parfois nécessaire de consulter des spécialistes de ces problèmes, il faut aussi se rappeler que les utilisateurs ont certainement de bonnes idées sur la façon d'améliorer ou de mieux organiser leur travail ; une approche sociotechnique et participative est le meilleur complément à l'approche ergonomique.
II-F. Chapitre 9 Cycle de vie des objets et objets métiers▲
II-F-1. Introduction ▲
Ces dernières années, l'approche objet a progressivement doté le génie logiciel d'un nouveau référentiel méthodologique dont la méthode Merise a su tirer profit en adaptant certains concepts au contexte de l'ingénierie de systèmes d'information.
Ainsi (cf. chapitre 7Chapitre 7 Modélisation conceptuelle des données) le formalisme entité-relation a été étendu pour prendre en compte dans les modèles de données le sous-typage d'entité, la spécialisation et la généralisation. Il en est de même de la notion d'état qui a naturellement trouvé sa place dans la modélisation des traitements. Cette notion d'état est associée à une modélisation dynamique des traitements qui se développera dans Merise au travers de l'élaboration de cycles de vie d'objets (CVO).
La notion d'objet métier est aussi apparue dans le sillage des méthodes objet en différenciation de celle d'objet logiciel. Souvent associée à une offre commerciale de composants logiciels répondant aux besoins d'un métier donné, la notion d'objet métier reste encore floue et en conséquence difficilement opératoire dans le cadre d'une méthode de conception de systèmes d'information comme Merise. Elle est cependant une notion en pleine émergence, permettant d'appréhender l'ingénierie des systèmes d'information selon de nouveaux éclairages, notamment celui de la réutilisation.
Dans ce chapitre, nous présentons en premier la modélisation du cycle de vie d'objet (CVO) en exposant l'intérêt de sa spécification, le formalisme que nous préconisons pour les modéliser, ainsi que quelques conseils d'élaboration. En second, nous abordons le concept d'objet métier en le positionnant tout d'abord dans le cadre de l'ingénierie des systèmes d'information avec Merise, puis en introduisant un ensemble d'éléments méthodologiques de modélisation relatifs d'une part à leur formalisation et d'autre part aux démarches associées à leur élaboration.
Notons que les notions de CVO et d'objet métier, dont l'intérêt a été confirmé par la pratique, ont été évoquées dans Merise dès le milieu des années 90, notamment dans Merise/2 [Panet, Letouche 94]. Enfin, ces deux notions complètent le cadre de modélisation proposé par Merise et concernent principalement les niveaux d'abstraction conceptuel et organisationnel, et dans une moindre mesure le niveau logique.
II-F-2. Cycle de vie des objets▲
II-F-2-a. Approche fonctionnelle ou dynamique des traitements▲
L'analyse séparée données - traitements est, nous l'avons vu en première partie, l'un des principes fondamentaux de la méthode Merise où les données représentent l'aspect statique, et les traitements l'aspect activités. Depuis le début des travaux sur la méthode Merise, deux approches se sont présentées voire opposées - pour la description des activités (les traitements) et de leur dynamique :
- une approche « fonctionnelle et événementielle » dans laquelle les activités (processus assurant des fonctions) sont déclenchées par l'apparition d'événements (approche fonctionnelle orientée événement activité) ;
- une approche centrée sur la spécification de l'évolution des données dans le temps, leur changement de valeur ou d'état prescrit ou proscrit suite à leur transformation par des activités (approche orientée état transition) et que nous qualifierons aussi, par abus de langage, d'approche « dynamique ».
L'approche retenue dans Merise est une approche fonctionnelle événementielle en partie inspirée des réseaux de Pétri (domaine de l'automatique) que l'on retrouve dans les modèles conceptuels, organisationnels et logiques de traitements. Cette approche novatrice par l'aspect événementiel reste assez classique de par son caractère fonctionnel.
Dans les domaines de l'informatique technique et scientifique, sous l'influence des modélisations des automatismes (automates à états finis), l'approche état transition s'est progressivement développée. L'approche objet trouvant en grande partie ses origines dans ces domaines, il était naturel de voir la modélisation dynamique réapparaître et cohabiter avec une modélisation fonctionnelle.
Aussi de nombreux auteurs, dont ceux de Merise /2 [Panet, Letouche 94], préconisent une modélisation selon trois aspects complémentaires : statique, fonctionnel et dynamique, au lieu de s'en tenir aux deux aspects statique et fonctionnel préconisés à l'origine dans Merise (figure 9.1).
L'aspect fonctionnel décrit ce que fait le système (les fonctions réalisées) ; l'aspect dynamique décrit comment le système se comporte (les changements d'état de ce dernier). On retrouve ainsi, outre l'aspect statique toujours représenté par les données, les deux approches fonctionnelle et dynamique de modélisation des traitements précédemment évoquées et qui cohabitent.
II-F-2-b. Modélisation fonctionnelle▲
C'est une modélisation de l'activité du SIO guidée par la chronologie des activités consécutives à un événement déclencheur (que fait-on suite à l'arrivée d'une déclaration d'accident ?). Elle représente d'abord une vision utilisateur du fonctionnement de son domaine.
On retrouve aujourd'hui cette approche dans le Business Process Reengineering, ainsi que dans l'analyse des procédures en vue de certification ISO 9000. Pratiquée depuis longtemps en gestion par les organisateurs, elle s'est appuyée sur des modélisations différentes suivant les méthodes (Structured Analysis, SADT…) considérant toujours l'activité comme concept central.
Dans la méthode Merise, cette modélisation se traduit par l'élaboration des modèles conceptuel, organisationnel et logique de traitements qui sont amplement développés dans cet ouvrage.
II-F-2-c. Modélisation dynamique▲
Cette modélisation des activités se situe dans le contexte d'une approche centrée sur les données. La vision statique des données est représentée par des objets et des associations, modélisés par des entités et des relations d'un MCD ou un MOD dans Merise.
L'évolution de ces objets et associations dans le temps (création, modification des valeurs, suppression ) est appelée dynamique des données. L'expression de cette dynamique repose essentiellement sur la modélisation des états successifs pris par ces objets, le passage d'un état à un autre et les traitements associés consécutifs à un événement (le règlement du sinistre à l'assuré fait passer le dossier de « en cours » à « réglé »). La modélisation dynamique correspondant ainsi à une vision des traitements à partir des objets de données.
Cette modélisation dynamique des activités est largement utilisée dans les méthodes objets. La deuxième génération de la méthode Merise propose de modéliser cette dynamique sous la forme de cycles de vie d'objets (CVO).
II-F-3. Formalisme de modélisation du cycle de vie des objets▲
II-F-3-a. Concepts généraux de la modélisation de la dynamique▲
Comme nous venons de le rappeler, la modélisation de la dynamique des données n'est pas nouvelle. Cette modélisation consiste à spécifier les différents changements d'état caractérisant un objet spécifique (ici une entité).
La plupart des formalismes utilisés à cet usage, et en particulier ceux retenus dans les méthodes ou notations objet (OMT ou UML par exemple), reposent sur les concepts suivants :
- État (abstraction des valeurs des attributs et des associations d'un objet).
- Événement (stimulus accompagné éventuellement d'information).
- Transition (modification d'état provoquée par un événement).
Ces formalismes s'expriment par des diagrammes d'état - transitions, communément appelés diagramme d'états, graphes dont les nœuds sont des états et les arcs orientés des transitions, transitions généralement désignées par des noms d'événements, événements à l'origine du changement d'état.
La figure 9.2 illustre le diagramme d'état du dossier de sinistre reprenant l'exemple utilisé dans les chapitres de l'ouvrage relatifs au MCT et au MOT.
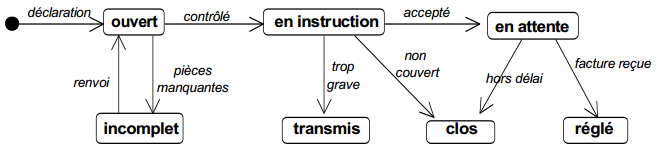
Dans les méthodes de génie logiciel orientées objet, le comportement des objets d'une classe peut être décrit formellement en termes d'états et d'événements par un automate à états finis. Cette description ne concerne que les objets ayant un comportement réactif significatif. Les modèles dynamiques préconisés dans OMT spécifient de tels comportements. Dans la notation UML, le formalisme retenu pour représenter ces automates s'inspire des « statecharts » proposé par Harel. Ce formalisme, de type diagramme d'états - transitions, permet entre autres de spécifier des conditions booléennes associées au déclenchement d'une transition lors de l'occurrence d'un événement, de spécifier des actions attachées au déclenchement d'une transition et enfin une généralisation et une agrégation d'états.
II-F-3-b. Concepts retenus pour le cycle de vie des objets dans Merise▲
Pour modéliser la dynamique associée aux données, nous proposons d'une part de s'inspirer des concepts communément retenus avec les diagrammes d'états, d'autre part de réaliser une économie de formalisme en utilisant celui déjà introduit pour la modélisation des traitements dans Merise.
En effet, les concepts des diagrammes d'états évoqués ci-dessus permettant la modélisation de la dynamique existent déjà dans le formalisme des traitements proposé dans Merise :
- l'État (appliqué généralement à une entité - objet) ;
- l'Événement ;
- l'Activité (opération, tâche) qui sera pour la circonstance, dans ce type de modèle, appelée Transition avec si nécessaire la possibilité d'exprimer des synchronisations et des conditions.
La modélisation du CVO Merise présente cependant quelques particularités propres à son utilisation dans le cadre d'un SIO :
- Le passage d'un état à un autre nécessite obligatoirement une transition indiquant a minima les activités permettant ce changement d'état.
- Une transition n'est pas obligatoirement déclenchée par un événement explicite ; on peut alors considérer que le déclenchement de la transition est implicitement lié à un événement décisionnel.
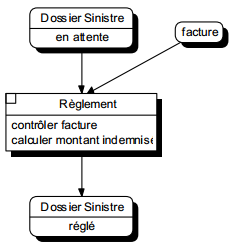
La figure 9.3 illustre le passage de l'état « en attente » de l'objet « Dossier Sinistre » à l'état « réglé », passage déclenché par la survenance de l'événement « facture » et nécessitant la réalisation de l'activité « Règlement ».
Ce choix de réutilisation des concepts et des symboles est délibéré. Nous estimons qu'il n'est pas souhaitable dans une méthode (nous ne sommes pas ici dans le contexte d'une notation) de multiplier inutilement les formalismes. Nous avons déjà eu recours à un même formalisme pour spécifier les différents modèles fonctionnels de traitements ; nous l'étendons désormais au modèle dynamique. Ainsi les MCT, les MOT, les MLT et les CVO constituent différentes modélisations de l'activité d'un système d'information organisationnel (SIO) ou informatisé (SII).
En fait, dans la modélisation des cycles de vie d‘objets, les concepts de modélisation restent identiques, seuls l'approche de modélisation et donc l'agencement des différents concepts changent. Tout d'abord, on se préoccupe d'un objet (entité ou relation) pour lequel on recense l'ensemble des états possibles. Ensuite, on analyse quand et comment (événement, condition) peut s'effectuer le passage (transition) d'un état à un autre, et quelles sont les activités associées à cette transition.
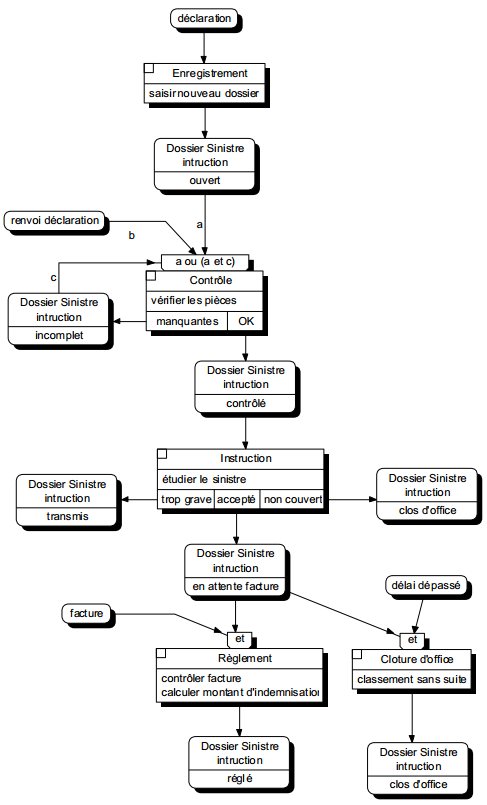
Un CVO est représenté graphiquement par l'ensemble des états de l'objet avec les transitions et les événements déclencheurs, comme l'illustre la figure 9.4 présentant le CVO de l'objet « Dossier Sinistre ».
L'analyse des états d'un objet peut parfois s'effectuer selon plusieurs types d'états, plusieurs cycles de vie. Par exemple, le Dossier de sinistre peut être analysé selon :
- Les différents états d'avancement de l'instruction (type d'état : instruction) : ouvert, contrôlé, transmis, en attente facture, réglé, clos d'office…
- Les différents états du suivi entre compagnies (type d'état : suivi compensation) : non communiqué, déclaration transmise, évaluation transmise, régularisé,…
II-F-3-c. C.V.O., niveau d'abstraction et degré de détail▲
Les principes généraux de modélisation dans la méthode Merise reposent sur un découpage en niveaux d'abstraction (conceptuel, organisationnel, logique, physique) associé, dans le cas des activités, à un degré de détail (de global à détaillé) (cf Chapitre 3Chapitre 3 Les trois composantes de Merise). Comment se situe la modélisation des CVO dans ce découpage ?
Dans la modélisation fonctionnelle des traitements, les états et les événements apparaissent dès le niveau conceptuel, associés aux opérations. Ils se reconduisent au niveau organisationnel où d'autres états et événements peuvent alors apparaître suite à la décomposition organisationnelle des opérations en tâches. Ces états d'origine organisationnelle traduisent des situations généralement transitoires dues à des choix de segmentation en tâches manuelles / informatisées ou de répartition dans des postes différents. Il faut également rappeler que le passage du niveau conceptuel au niveau organisationnel s'accompagne généralement d'un accroissement du degré de détail.
On peut donc distinguer deux niveaux de CVO dépendant essentiellement du niveau auquel sont pris en compte les états :
- Un CVO conceptuel est construit avec des états qui interviennent au niveau conceptuel de traitements. Ce sont des états stables, perçus par les acteurs de l'environnement.
- Un CVO organisationnel est construit avec les états exprimés au niveau organisationnel (intégrant donc ceux du niveau conceptuel). Ce niveau de CVO est donc nécessairement plus détaillé et riche en états. Certains de ces états ne sont perceptibles que par les acteurs internes au système (on les nomme souvent états intermédiaires ou transitoires).
Dans la pratique, afin de prendre en compte tous les états possibles, le CVO présenté est implicitement de niveau organisationnel. Nous retrouverons cette hypothèse dans la démarche d'élaboration d'un CVO.
II-F-3-d. Dualité entre la modélisation fonctionnelle des traitements et la modélisation du cycle de vie des objets▲
Les modélisations conceptuelle puis organisationnelle des traitements ont mis en situation la quasi-totalité des concepts du CVO (états, événements, activités), mais avec des points de vue différents. Aussi, nous souhaitons mettre en évidence une certaine dualité et complémentarité existant entre la modélisation fonctionnelle (MCT, MOT) et le CVO, tant dans l'expression que dans le processus d'élaboration :
- Dans le MCT / MOT, on modélise (approche fonctionnelle) sous la forme d'un processus ou d'une procédure, la succession des activités consécutives à un événement initial. Les états de divers objets apparaissent comme des conditions préalables ou des résultats conditionnels de ces activités. On s'intéresse essentiellement à l'analyse, à la répartition et aux ressources mises en œuvre pour effectuer ces activités. Chaque schéma représente un processus ou une procédure. Seuls le degré de détail et la prise en compte des choix et contraintes organisationnelles introduisent une différence entre ces deux niveaux de modélisation.
- Dans le CVO, on modélise (approche dynamique) l'ensemble des états possibles d'un même objet. Les événements et les transitions expriment les conditions de passage d'un état à un autre. On s'intéresse au comportement d'un objet à travers tous les traitements qui peuvent lui être associés. Chaque schéma représente le cycle de vie d'un objet donné.
- Dans le MCT /MOT, l'événement et l'activité (opération ou tâche) sont les concepts principaux, l'état est un concept secondaire.
- Dans le CVO, l'état est un concept principal, l'événement et l'activité (transition) sont des concepts secondaires
Notons qu'un processus ou une procédure organisationnelle peuvent être considérés comme une partie du « cycle de vie » du SIO, c'est-à-dire un ensemble de traitements successifs à un flux et concernant plusieurs objets, à travers les états et les sous-schémas de données. Une procédure organisationnelle reste cantonnée dans un domaine ou sous -domaine. Le cycle de vie d'un objet réunit l'ensemble des traitements possibles sur un objet. Il peut ainsi s'étendre sur plusieurs domaines.
II-F-3-e. Élaboration d'un C.V.O.▲
On peut envisager deux démarches pour la construction d'un CVO :
- Le CVO est déduit de l'ensemble des traitements fonctionnels. Pour chaque objet, on extrait ses différents états modélisés dans les différents processus ou procédures avec les activités et les événements associés. En considérant les activités (opération ou tâches) comme des transitions, on reconstitue dans un schéma unique les traitements (transitions) conduisant à un changement d'état. Une telle démarche suppose que la modélisation fonctionnelle soit complète.
- Le CVO est construit directement. Pour chaque objet issu du MCD / MOD et pour lequel on perçoit des états possibles, on recense les états, puis on exprime les événements et les transitions associés.
Pratiquement, les modèles MCT/MOT et CVO peuvent être élaborés alternativement, chacun venant enrichir et vérifier l'autre.
- La construction du MCT/MOT, par la prise en compte des états, met en évidence des traitements associés (en condition préalable ou en résultat) qui permettent d'alimenter par déduction la construction du CVO.
- La construction du CVO, par la recherche exhaustive des états d'un objet, oblige à exprimer des événements et des activités qui auraient probablement échappé à une analyse fonctionnelle, et conduit ainsi à un enrichissement du MCT/MOT.
Cette complémentarité entre MCT/ MOT et C.V.O. contribue à la qualité de la modélisation des traitements.
En pratique, on n'élaborera des CVO que pour les objets qui présentent un ensemble d'états significatifs ; on considère que les états triviaux (créé, modifié, supprimé) ne présentent qu'un intérêt très limité au niveau SIO
En conclusion, la modélisation du cycle de vie des objets apparaît tout à fait adaptée au cadre de la méthode Merise. Elle vient judicieusement combler une lacune face aux méthodes de conception orientées objet, la dotant ainsi d'un nouvel atout pour affronter le challenge des nouvelles évolutions méthodologiques.
II-F-4. Objets métiers▲
La notion d'objet métier est progressivement apparue dans la méthode Merise au début de la décennie 90 comme une extension de la modélisation conceptuelle des données. Elle a été par ailleurs mise en avant à partir des méthodes objet, par différentiation avec les objets logiciels(5). Enfin, cette notion est souvent reprise en tant qu'offre commerciale de composants logiciels adaptés à un métier et prêts à l'emploi.
Cette notion d'objet métier présente pour le moins de multiples facettes. Dans le cadre de la méthode Merise, elle ne bénéficie pas encore de suffisamment de retour d'expérience pour constituer une base méthodologique éprouvée.
Toutefois dans le cadre de la quatrième édition de cet ouvrage, il nous est apparu judicieux de présenter tout d'abord deux différentes perspectives méthodologiques associées à l'objet métier, d'une part la macro-modélisation et d'autre part la modélisation intégrative. Ensuite dans la perspective de la macro-modélisation, qui nous apparaît actuellement la plus praticable, nous introduirons un certain nombre d'éléments méthodologiques permettant la conception d'objets métiers dans le cadre de Merise. Ces éléments nous semblent ouvrir une voie opérationnelle que nous espérons intéressante.
II-F-4-a. L'objet métier : une macro-modélisation de données▲
La modélisation en termes d'entités et de relations proposées dans le MCD est certes centrée autour « d'objets d'intérêt pour l'utilisateur », mais elle reste encore fortement contrainte par des règles de modélisation (en particulier celle de vérification). Ces règles sont nécessaires pour obtenir une certaine rigueur de modélisation indispensable pour permettre une informatisation (passage du SIO au SII), mais elles déroutent parfois l'utilisateur d'une perception plus « naturelle ».
Prenons l'exemple classique de la notion de Commande où, quelle que soit la modélisation adoptée, les lignes composant cette commande sont naturellement intégrées par un utilisateur dans cette notion de Commande.
La perception de l'utilisateur tend ainsi à regrouper autour d'un concept majeur, généralement représenté par une entité conceptuelle de même nom, des relations et des entités fortement liées sémantiquement (du point de vue du métier, les lignes d'une commande font partie intégrante d'une commande).
L'objet métier apparaît ainsi comme une agrégation nommée d'entités et de relations, perceptible comme un tout par le métier. L'objet métier permet une modélisation macroscopique, sa composition détaillée en termes d'entités et de relations résultant du respect des règles de formalisation conceptuelle (figure 9.5).
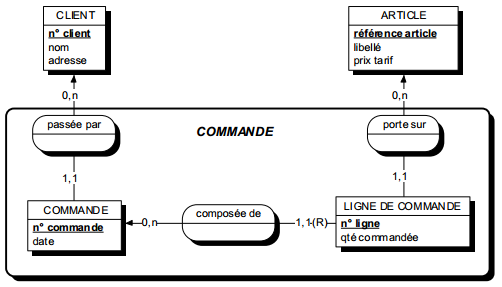
L'objet métier en tant qu'agrégation ou macro-modélisation a été initialement proposé dans le cadre des évolutions de la méthode Merise par P.A. Bres sous le concept d'objet « naturel » [Bres 91]. Dans cette approche, la modélisation des objets métiers est obtenue par un découpage disjoint (partitionnement) du modèle de données (en général de niveau conceptuel) et représente une macromodélisation des données qui offre ainsi un « effet de zoom » sur les données, contextuel à un métier, analogue à celui de la décomposition hiérarchique (raffinement) présente dans les traitements.
Notons que cette approche est également introduite dans la méthode P+ (méthode voisine de Merise et proposée au Québec par la Sté DMR) où les « sujets » (objets métiers) se décomposent en « facettes » modélisées en entité - relation.
Cette expression des objets métiers comme une macro-modélisation construite sur le modèle conceptuel de données semble être actuellement la plus communément admise. Aussi l'avons-nous retenue comme approche de conception des objets métiers.
II-F-4-b. L'objet métier : une modélisation intégrative▲
Dans la méthode Merise, un concept nommé du monde réel peut se retrouver modélisé sous le même nom, de différentes façons, selon le type de modélisation. Par exemple dans le domaine de l'assurance :
- L'assuré est modélisé comme un acteur dans un diagramme de flux et un MCT, et comme une entité dans un MCD.
- Le sinistre se retrouve modélisé (avec des nuances d'appellation) sous la forme d'une entité, d'un état, de différentes évolutions de messages, probablement comme une vue externe et enfin présenté au travers d'une maquette.
Le concept d'objet métier peut alors recouvrir, pour un même concept du monde réel, l'ensemble des aspects de la modélisation : sa définition statique, son comportement dynamique, son utilisation fonctionnelle (cf. figure 9.1). L'objet métier apparaît alors comme l'intégration de diverses facettes d'un concept du métier qu'explicitent les différentes modélisations formalisées :
- sa modélisation de données (MCD) ;
- son fonctionnement (MCT, MOT) ;
- son comportement (CVO) ;
- ses présentations (maquettes d'IHM).
L'objet métier, intégrant les diverses facettes ou composantes modélisées, devient alors une « superstructure » des modélisations classiques de la méthode Merise. On remarquera que la vision du paragraphe précédent (macromodélisation de données) n'est alors qu'une des facettes de la décomposition de l'objet métier intégrateur.
Cette vision intégrative de l'objet métier présente de nombreux intérêts, notamment de :
- favoriser une approche modulaire de l'étude des SIO ;
- reprendre des techniques de modélisation connues tout en réduisant l'étendue ;
- préparer la constitution de composants métiers réutilisables.
Cette approche de l'objet métier en tant que modélisation intégrative nous apparaît plus ambitieuse et plus prometteuse que celle d'une macromodélisation. Cependant, elle nécessite encore bien des réflexions, des expérimentations et la mise au point d'outils logiciels l'instrumentant pour pouvoir constituer un véritable apport méthodologique opérationnel.
II-F-5. Conception des objets métiers▲
Nous venons de distinguer deux perspectives méthodologiques différentes de l'objet métier dans la conception de systèmes d'information organisationnels (SIO) : la macro-modélisation et la modélisation intégrative. Cette dernière nous apparaît encore en gestation. Par contre, il est dès à présent possible de proposer, dans le cadre de Merise, des éléments méthodologiques permettant tout d'abord la modélisation d'objets métiers et ensuite d'accompagner le concepteur dans l'élaboration de ces modèles en lui proposant une démarche spécifique.
II-F-5-a. Formalisation des objets métiers dans Merise ▲
Issue d'une macro-modélisation, un objet métier formalise un regroupement nommé d'entités et de relations d'un modèle conceptuel de données, fortement liées sémantiquement et permettant une définition globale de son contenu et de son comportement.
Le symbole retenu pour représenter un objet métier s'inspire (dans le graphisme et la construction) de celui de paquetage dans UML, comme l'illustre la figure 9.7 suivante :
L'objet métier peut être représenté sous deux formes :
- objet plié : seul le symbole de l'objet métier est représenté (Figure 9.7) ;
- objet déplié : le contenu de l'objet métier en termes d'entités et de relations est représenté dans le symbole (Figure 9.8).
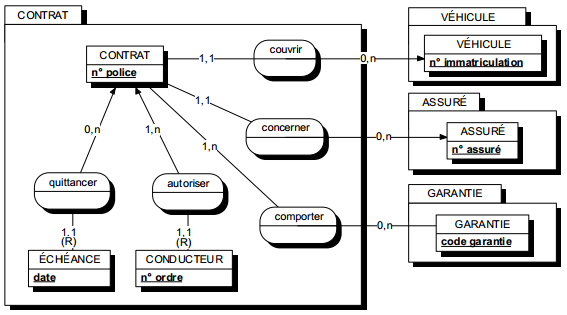
II-F-5-b. Entité racine d'un objet métier▲
On appelle racine d'un objet métier l'entité composante ayant la plus grande affinité sémantique avec l'objet métier, qui en exprime l'essentiel de sa signification. Cela se concrétise généralement par l'identité de nom entre l'objet métier et son entité racine. Par exemple, dans la figure 9.8, l'entité Contrat est considérée comme la racine de l'objet métier Contrat.
Cette assimilation sémantique entre l'objet métier et son entité racine implique une même distinguabilité d'occurrences. Ainsi, une occurrence de l'objet métier Contrat équivaut à une occurrence de l'entité Contrat. Bien qu'un objet métier ne soit pas explicitement doté d'un identifiant, on voit bien que la problématique de l'identification de l'entité racine (ou le choix de cette entité racine) conditionne la perception et la compréhension de l'objet métier.
Les autres entités, ainsi que les relations composant l'objet métier, sont qualifiées de secondaires et apparaissent « encapsulées » dans l'objet métier.
II-F-5-c. Lien entre objets métier▲
La construction d'un objet métier par regroupement d'entités et de relations conduit à un découpage du MCD selon des règles qui seront précisées dans le paragraphe suivant. Ce découpage passe nécessairement sur des pattes de relations qui lient une relation appartenant à un objet métier à une entité appartenant à un autre objet métier.
Le lien entre objets métier est équivalent à la patte « coupée ». C'est par ce lien entre objets métier que s'effectue la continuité sémantique exprimée dans le MCD, concrétisant le fait que les objets métier ne sont pas indépendants. Le lien d'un objet métier (origine, référant) vers un autre objet métier (référé) exprime que, dans l'objet métier origine, on utilise des données présentes dans -ou fournies par- l'objet métier référé.
Dans le cas d'une représentation pliée des objets métiers, on représente ces liens sous la forme d'une flèche en pointillés rappelant le lien de référence à un autre objet métier comme l'illustre la figure 9.9.
II-F-5-d. Entité externe dans un objet métier▲
La modélisation en termes d'objets métiers, sous la forme pliée ou dépliée, montre la nécessité de liens entre les objets métiers. Or, l'approche objet métier a pour objectif la recherche d'une modularité visant à réduire l'étendue de la modélisation conceptuelle des données en la bornant aux entités et relations sémantiquement regroupées autour du concept métier.
Il apparaît alors nécessaire, dans une modélisation conceptuelle limitée au contenu d'un objet métier (représentation dépliée autonome), de distinguer :
- les entités et les relations propres ou internes à l'objet métier ;
- des entités externes qui évoquent des données d'autres objets métiers, mais dont le contenu est nécessaire et utilisé dans le cadre de l'objet métier modélisé.
Dans la description conceptuelle des données d'un objet métier, l'entité externe représente ainsi la perception du contenu partiel d'un autre objet métier, vu à partir de l'objet métier étudié. Sa formalisation et ses principes de construction sont identiques à ceux définis pour l'entité externe dans le cadre des vues externes (cf. chap. 11Chapitre 11 Confrontation données / traitements).
Dans la représentation dépliée autonome d'un objet métier (limitée à son contenu), une entité externe :
- se symbolise comme une entité avec un style graphique distinctif (pointillé, non ombré) ;
- comporte des propriétés externes respectant la règle de vérification ;
- ne possède par obligatoirement d'identifiant ;
- participe à des relations avec des entités internes à l'objet métier ;
- fait référence à un seul objet métier, plusieurs entités externes pouvant faire référence à un même objet métier ;
- peut s'appeler comme l'objet métier référencé, mais aussi utiliser une autre appellation exprimant la perception externe de l'objet métier.
Comme dans le contexte de la modélisation des vues externes, la spécification d'une entité externe au sein d'un objet métier ne cherche pas à définir des entités conceptuelles. Elle se borne à exprimer, dans un formalisme unique, un ensemble d'informations nécessaires à l'objet métier étudié, en provenance d'un autre objet métier, sans que son contenu soit structuré et conceptualisé. Il ne s'agit pas de reconstituer la structure conceptuelle qu'auraient ces informations dans l'objet métier référé.
La figure 9.10 présente la vision dépliée autonome de l'objet métier Sinistre avec :
- l'entité externe Contrat qui réfère à l'objet métier Contrat ;
- l'entité externe Garantie qui réfère à l'objet externe Garantie.
Dans l'entité externe Contrat, on remarquera que certaines des propriétés externes évoquant l'assuré et le véhicule sont perçues comme provenant de l'objet métier Contrat, sans préjuger de leur réelle appartenance directe à cet objet. L'entité externe Contrat est la vision qu'a l'objet métier Sinistre de l'objet métier Contrat.
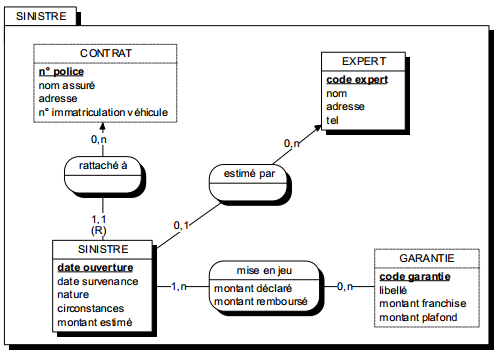
Dans le processus d'élaboration des objets métiers, il faut s'assurer que toute entité externe a une correspondance sémantique (structure et contenu) dans la description conceptuelle des données de l'objet métier auquel elle se réfère. Pour valider cette correspondance, on appliquera les mêmes règles que celles définies pour la confrontation détaillée des vues externes (cf. chap. 11 : Algorithme de confrontation détailléeConfrontation algorithmique détaillée) dont nous résumons les principes :
-
Équivalence entre propriété externe et propriété conceptuelle :
- directement,
- via une relation,
- via une règle.
-
Correspondance entre entité externe et sous-ensemble conceptuel :
- reconstitution du sous-ensemble conceptuel portant les propriétés conceptuelles obtenues par équivalence,
- détermination du « pivot » du sous-ensemble, entité conceptuelle dont l'occurrence (distingabilité) correspond à celle de l'entité externe.
II-F-5-e. Représentations de la modélisation en objets métier▲
Comme nous venons de le constater, on dispose de plusieurs présentations graphiques possibles de la modélisation en objets métiers. Ces diverses représentations, que nous déclinons ci-après, permettent de mettre en évidence tantôt une présentation générale de l'ensemble des objets métiers interreliés (vision macroscopique), tantôt une description plus détaillée d'un objet métier (vision dépliée autonome), tantôt une superposition du découpage en objets métiers sur un modèle conceptuel de données (vision explicative).
Suivant le besoin et le contexte, le concepteur utilise la représentation qui lui semble la plus adaptée.
II-F-5-e-i. Schéma général d'objets métiers▲
Dans un tel schéma, l'ensemble des objets métiers identifiés dans le domaine étudié sont représentés sous forme pliée avec leurs liens entre objets métiers. La figure 9.9 est une illustration d'une telle présentation.
Cette présentation offre une vision générale « panoramique » et macroscopique des objets métiers et de leurs interrelations. C'est cette représentation qui est usuellement nommée Modèle d'Objets Métiers (MOM)(6).
II-F-5-e-ii. Schéma détaillé d'un objet métier▲
Il s'agit de la représentation dépliée autonome d'un objet métier dont le contenu sémantique détaillé est modélisé conceptuellement en termes d'entités (propres et externes) et de relations. Les figures 9.10 et 9.13 sont des illustrations d'une telle présentation.
Dans la pratique, on établira un schéma distinct pour chaque objet métier. On peut alors éventuellement faire l'économie de la représentation du symbole de l'objet métier.
II-F-5-e-iii. Schéma de découpage en objets métiers▲
Ce schéma est en fait un modèle conceptuel de données sur lequel on fait figurer le contour des objets métiers sous forme évidemment dépliée. Les figures 9.8 et 9.12 sont des illustrations d'une telle représentation.
Un tel schéma est plutôt destiné à expliquer le découpage en objets métiers opéré sur un modèle conceptuel de données. Dans la pratique, il devient assez difficile de respecter la symbolisation de l'objet métier qui prend rapidement une forme polygonale. De plus, cette représentation atteint très vite des limites de taille et de lisibilité qui conduisent le concepteur à fractionner ces schémas en se focalisant, pour chacun, sur un objet métier.
II-F-5-f. Élaboration des objets métiers▲
Élaborer un objet métier c'est d'une part le définir, d'autre part décrire son contenu (en termes de données dans le contexte de l'approche macromodélisation retenue).
Deux démarches peuvent être adoptées pour l'élaboration d'objets métier :
- Une démarche par composition, qui fait apparaître les objets métiers à partir d'une modélisation conceptuelle de données, en appliquant certaines règles de découpage.
- Une démarche par décomposition qui consiste à définir d'abord les objets métier du domaine étudié, à formaliser le contenu conceptuel des données de chacun, puis à reconstituer les liens entre objets métier permettant de vérifier une continuité et une compatibilité sémantique au niveau de la modélisation conceptuelle des données de l'ensemble du domaine étudié.
Ces deux approches sont complémentaires et l'on peut, selon la complexité et l'étendue du domaine étudié, préférer l'une ou l'autre approche, voire mixer les deux. Notons que cette dualité d'approche est similaire à celle déjà rencontrée pour l'élaboration d'un MCD : déductive ou inductive (cf. chap. 7Chapitre 7 Modélisation conceptuelle des données).
II-F-5-g. Élaboration d'objets métier par composition▲
Dans cette approche, la détermination des objets métier est réalisée par un découpage du MCD, en regroupant des entités et relations autour d'entités racines « candidates ». Elle nécessite l'existence préalable d'une modélisation conceptuelle des données sur l'ensemble du domaine étudié, à partir de laquelle sont déterminés les objets métiers. On peut qualifier cette approche de « bottom - up ».
Pour réaliser ce découpage, nous proposons une démarche(7) heuristique, aidée par l'application de règles qui, bien que non formelles, guident le concepteur dans l'identification des objets métier. Cette démarche s'articule autour des étapes chronologiques suivantes :
1/ Choisir des entités racines candidates.
On retient, parmi les entités du MCD, celles dont le nom évoque un concept important dans le discours du métier.
2/ Étendre autour des entités racines.
À partir d'une entité racine, agréger les entités que l'on peut considérer comme structurellement et sémantiquement sous la dépendance de l'entité racine. Ces entités sont considérées comme internes à l'objet métier, ainsi que les relations qui les relient.
3/Délimiter la frontière de chaque objet métier.
Poursuivre l'extension de l'objet métier jusqu'à rencontrer une entité que l'on considère comme n'appartenant pas à cet objet métier. Ce choix ne repose pas sur des règles formelles, mais plus sur le choix du concepteur interprétant la perception du métier. Indiquons cependant quelques principes pour appréhender la frontière de l'objet métier :
- On ne peut intégrer dans un objet métier une entité qui serait déjà intégrée dans un autre objet métier, en particulier une entité racine candidate.
- Les entités sous-types devraient appartenir au même objet métier que leur surtype.
4/ Déterminer le lien entre les objets.
Il s'agit de déterminer si la relation impliquée à la frontière de l'objet métier considéré appartient ou non à cet objet. Cette frontière coupe nécessairement une des pattes de la relation qui correspondra au lien entre objets métier. Pour ce choix de découpage, on s'appuie sur les règles illustrées par le tableau suivant :
Conventions :
- Le trait vertical positionne la coupure de la frontière.
- L'une des entités est interne (appartient à l'objet métier à délimiter).
- L'autre entité est étrangère (appartient à un autre objet métier).
- La règle sur les cardinalités est symétrique selon le positionnement de l'entité interne.
- Pour les relations de dimension > 2, on applique la règle pour chaque couple de pattes.
 |
La coupure est indifféremment possible d'un côté ou de l'autre |
 |
On doit cependant s'interroger sur la pertinence de la délimitation de la frontière au niveau de cette relation |
 |
|
 |
Bien que possible des deux côtés, la coupure se fait de préférence côté Ent_2 |
 |
|
 |
|
 |
La coupure est indifféremment possible d'un côté ou de l'autre |
 |
|
 |
La coupure est indifféremment possible d'un côté ou de l'autre |
5/ Établir les entités externes.
Afin de rendre relativement autonome chaque objet métier déterminé et de permettre une représentation dépliée autonome, on matérialise, dans l'objet métier, la conséquence de la coupure de la patte de la relation frontière par une entité externe correspondant a minima à l'entité étrangère impliquée dans la relation frontière. Ultérieurement, le concepteur pourra enrichir cette entité externe avec de nouvelles propriétés externes, voire définir de nouvelles entités externes.
À l'issue de ce processus de composition des objets métiers, il convient de vérifier globalement la qualité du résultat en appliquant les principes suivants qui relèvent plus de la « bonne pratique » que de règles formelles :
- Pertinence : chaque objet métier doit avoir un intérêt du point de vue du métier. Son nom doit être intelligible dans le discours utilisateur.
- Consistance : l'envergure de l'objet métier, en termes de contenu (entités, relations, propriétés), doit être consistant. On doit s'interroger sur un objet métier ne contenant qu'une entité décrite seulement par quelques propriétés.
- Disjonction : une entité, ou une relation conceptuelle, ne peut appartenir qu'à un seul objet métier. Le découpage en objets métier réalise une partition du MCD.
- Continuité : dans un objet métier, toutes ses entités sont atteignables à partir de sa racine (directement ou indirectement) via des relations. L'ensemble des entités et des relations forment un graphe connexe.
- Granularité : l'étendue d'un objet métier, en termes de nombre d'entités et de relations, doit rester raisonnable (inférieure à la vingtaine…).
- Autonomie : l'existence d'une occurrence d'un objet métier est autant que possible indépendante des autres objets métier. Dans l'application des règles de découpage, on privilégiera les relations « frontières » à cardinalités mini 0 sur l'ensemble des pattes. Des cardinalités mini à 1 induisent en effet une dépendance d'existence entre les objets métiers.
En illustration de cette élaboration d'objets métier par composition, la figure 9.12 présente un MCD découpé en objets métier (schéma de découpage en objets métiers). La figure 9.13 détaille le contenu de l'objet métier Contrat avec les entités externes a minima issues du découpage (schéma détaillé d'un objet métier).
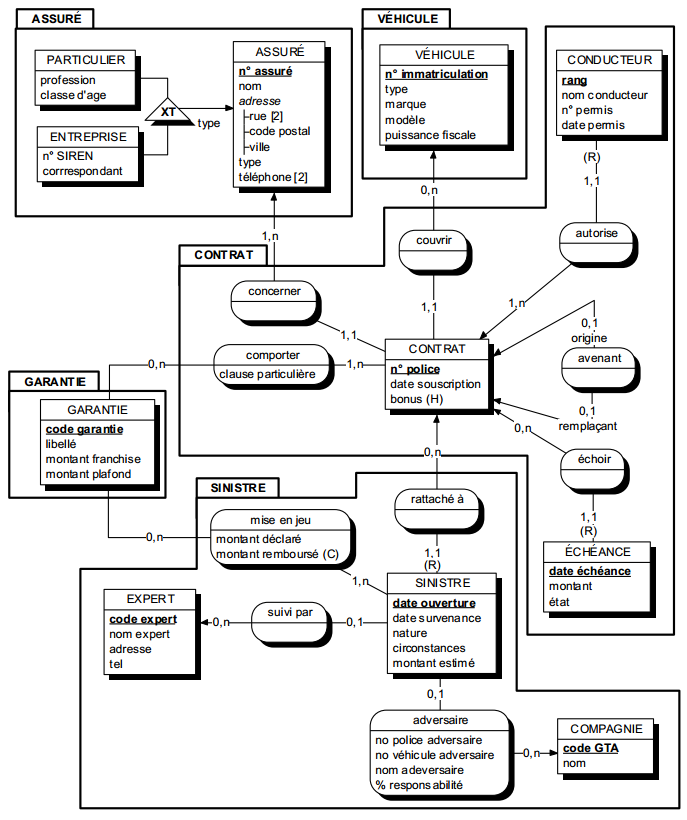
II-F-5-h. Élaboration d'objets métier par décomposition▲
Dans cette démarche, la détermination des objets métier est un choix a priori du concepteur en fonction de la pertinence perçue de la notion associée à cet objet dans le discours du métier. Le concepteur détaille ensuite le contenu des données de l'objet par une modélisation conceptuelle de données. On peut qualifier cette approche de « top - down ».
Cette modélisation du contenu des données conceptuelles de l'objet métier s'effectue selon les règles habituelles d'utilisation du formalisme Entité - Relation ; seule l'étendue de la modélisation est limitée à la frontière estimée de l'objet. Lorsque certaines données (entités et propriétés) sont considérées comme provenant d'un autre objet métier, elles sont modélisées sous la forme d'entités (et de propriétés) externes.
Cette démarche par décomposition produit une modélisation conceptuelle des données de chaque objet métier, en faisant toutefois référence à d'autres objets métier par l'intermédiaire des entités externes.
À l'issue de cette première étape de la démarche, le concepteur doit s'assurer de la recomposition possible et cohérente d'un MCD portant sur l'ensemble du domaine étudié, à partir des modélisations conceptuelles des données de chaque objet métier.
II-F-5-i. Validation par recomposition▲
Cette recomposition consiste à réunir l'ensemble des données modélisées des objets métiers et à reconstituer les liens entre les objets métiers qui théoriquement correspondent à des pattes de relations (cf. § Lien entre objets métierLien entre objets métier). Cette validation s'appuie sur les entités externes définies dans chaque objet métier.
Pour chaque entité externe (cf. § Entité externe dans un objet métierEntité externe dans un objet métier), on applique l'algorithme de validation externe/conceptuel, par rapport à la modélisation conceptuelle des données de son objet métier de référence. Cet algorithme, qui est identique à celui appliqué pour la validation des entités externes dans les vues externes (cf. chapitre 11 : Validation algorithmique) permet de déterminer :
- le sous-ensemble conceptuel correspondant à l'entité externe ;
- l'entité pivot de ce sous-ensemble.
Le lien entre les objets doit correspondre à une patte de relation entre :
- la relation interne à laquelle participe l'entité externe ;
- l'entité pivot déterminée dans l'autre objet métier.
On va ainsi reconstituer les pattes « coupées » qui apparaissaient dans une démarche par composition.
Illustrons cette démarche par un exemple :
- La figure 9.10, par une représentation dépliée autonome ou schéma détaillé, propose une modélisation conceptuelle des données de l'objet métier Sinistre, avec notamment l'entité externe Contrat qui réfère à l'objet métier Contrat.
- La figure 9.14 présente la correspondance entre l'entité externe Contrat et son sous-ensemble conceptuel dans l'objet métier Contrat, ainsi que son pivot l'entité Contrat. On remarquera que ce sous-ensemble comporte des entités externes qui à leur tour devront être validées.
- On a donc bien reconstitué la patte de relation entre Rattaché à et Contrat qui apparaît bien comme coupée dans la figure 9.12 (schéma de découpage).
Cette démarche de recomposition ne vise pas nécessairement à reconstituer un MCD général sur l'ensemble des objets métiers, mais plutôt à valider les objets métier deux à deux pour vérifier la cohérence de leurs liens d'utilisation à travers les entités externes.
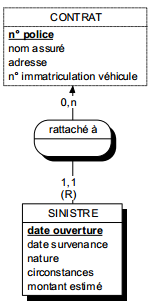 |
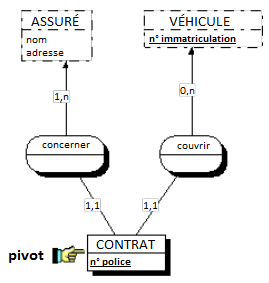 |
II-F-5-j. Conclusion sur la modélisation des objets métier▲
La modélisation en termes d'objets métier n'a été que succinctement abordée dans ce chapitre et uniquement à travers sa composante données de niveau conceptuel, selon une approche de macro-modélisation.
Les prolongements méthodologiques conduisant à une approche intégratrice, évoquée en introduction de la notion d'objet métier et consistant à prendre en compte les autres composantes de l'objet métier (comportement, fonctionnement, présentation) y compris pour les autres niveaux (organisationnel et logique), nécessitent des développements qui dépassent le cadre de cet ouvrage. L'approche objets métier peut désormais s'inscrire comme un complément et une évolution prometteuse de l'approche« merisienne » classique en ingénierie de systèmes d'information.
II-G. Chapitre 10 Modélisation organisationnelle des données▲
II-G-1. Problématique du modèle organisationnel de données (MOD)▲
Comme nous l'avons vu précédemment, la modélisation conceptuelle des données visait à représenter la signification des informations utilisées dans un domaine d'activité de l'entreprise sans tenir compte de contraintes organisationnelles, économiques ou techniques. Elle exprimait des objets concrets ou abstraits, des associations entre ces objets et des informations descriptives, formalisées en termes d'entités, de relations et de propriétés.
La modélisation organisationnelle des données va permettre de prendre en compte des éléments relevant de l'utilisation des ressources de mémorisation :
- Le choix des informations à mémoriser informatiquement.
- La quantification (ou volume) et la durée de vie des informations à mémoriser.
- La répartition des données informatisées entre unités organisationnelles.
- L'accès aux données informatisées pour chaque unité organisationnelle.
Ces différentes préoccupations nous conduiront à définir deux niveaux de modélisation organisationnelle des données : le MOD global, directement dérivé du MCD, et les MOD locaux, spécifiques chacun à une unité organisationnelle. Les MOD locaux seront dérivés du MOD global en prenant en compte des choix d'organisation, en particulier de répartition.
Les modèles organisationnels de données s'expriment avec le même formalisme que le modèle conceptuel de données (entité - relation) auquel on ajoutera quelques notions complémentaires. Aussi, dans la première génération d'utilisation de la méthode Merise, les concepteurs ont-ils pu sans difficulté considérer ce modèle organisationnel des données comme un affinement du modèle conceptuel des données, intégrant les conséquences des choix organisationnels cohérents avec le modèle organisationnel des traitements.
Le modèle organisationnel de données apparaît donc comme une représentation, exprimée avec le formalisme entité - relation, des informations qui seront mémorisées informatiquement compte tenu des volumes, de la répartition et de l'accessibilité, sans encore tenir compte des conditions de structuration, de stockage et de performance liées à la technologie de mémorisation informatique qui sera utilisée.
Il est important de distinguer :
- la répartition organisationnelle des données qui impacte directement les tâches de l'utilisateur à travers le besoin et la disponibilité des données (quelle que soit la localisation physique de mémorisation) ; cette répartition est exprimée par les MOD locaux ;
- la répartition informatique des données, liée à l'implantation du stockage des données, éventuellement transparente à l'utilisateur et exprimée dans les modèles logiques et physiques de données.
II-G-2. Choix des données à mémoriser▲
Il s'agit de choisir, à partir des informations formalisées sur le MCD, celles qui devront être effectivement mémorisées informatiquement dans le système d'information informatisé (SII) (ou données informatisées). Notons que les autres informations seront mémorisées « manuellement » (support papier ou autre non informatique) mais feront toujours partie des informations constituant la mémoire du système d'information organisationnel (SIO).
Le modèle organisationnel des données ainsi obtenu est de niveau global ; il ne prend pas en compte les choix d'utilisations réparties. Ce MOD dérive directement du MCD auquel on peut être conduit à :
- Supprimer des éléments (entités, relations, propriétés) qui ne seront pas mémorisés informatiquement.
- Modifier certains éléments (entités, relations, propriétés, cardinalités…) compte tenu du choix de mémorisation informatisé.
-
Ajouter de nouvelles informations :
- pour permettre de faire le lien entre les données mémorisées et les données restées manuelles ; par exemple la référence de fiches, de dossiers, d'un ensemble de mesures réalisées, de plans…,
- pour mémoriser des états du système d'information consécutifs au déroulement des traitements dans le MOT.
La détermination des informations informatisées ou manuelles peut s'effectuer :
- Par rapport à l'intérêt de conserver telle information (dialogue avec l'utilisateur).
- Pour des motifs de volume (voir paragraphe suivant).
- Suite à l'utilisation d'informations exclusivement par des tâches manuelles (MOT et confrontation données traitements : grille de cohérence ou confrontation détaillée).
- Pour rester en cohérence avec des choix de types de ressource informatisée, effectués au niveau du modèle organisationnel de traitements.
Les praticiens de la méthode Merise retrouveront ici la plupart des modèles conceptuels de données qu'ils ont réalisés, tout en s'interrogeant parfois sur la pureté conceptuelle de leur modélisation. Sur le terrain, la confusion éventuelle entre le modèle conceptuel de données et le modèle organisationnel de données global, du fait de l'identité du formalisme utilisé, ne remet pas en cause le rôle primordial d'expression de la signification des informations utilisées et le dialogue avec les utilisateurs.
II-G-3. Quantification du modèle organisationnel de données▲
La quantification du MOD s'effectue essentiellement au niveau du MOD global. Elle consiste à préciser le type et la longueur des propriétés, ainsi que les contraintes sur les valeurs et le nombre d'occurrences des entités et des relations.
Cette quantification peut s'effectuer déjà au niveau conceptuel ; c'est en fait une préoccupation constante du concepteur. Par exemple, l'évaluation du nombre d'occurrences d'une entité peut être un révélateur de la compréhension de cette entité. Notons que cette quantification est statique et détermine en première approximation le volume des données à mémoriser. Elle permettra entre autres de mieux évaluer les possibilités de répartition organisationnelle des données et en conséquence de dériver les MOD locaux.
II-G-3-a. Type et taille des propriétés▲
Le concepteur doit préciser le type de données ainsi que la taille des propriétés, en termes de nombre de caractères. Il peut recourir aux types standards utilisés en informatique ou définir des types utilisateurs. Il indiquera enfin les domaines de valeurs à respecter par certaines propriétés.
II-G-3-b. Types standards▲
Au niveau du MOD, on doit a minima distinguer les types de données caractères et numériques, ainsi que le nombre de caractères significatifs (la longueur). Nous proposons, à défaut, la notation suivante :
- An (champ alphanumérique de n caractères).
- Nn (champ numérique de n chiffres — valeur entière).
- Nn.p (champ numérique de n chiffres significatifs dont p chiffres après la virgule).
On peut également s'inspirer de la typologie de données définie en informatique, et plus particulièrement dans les bases de données. On peut ainsi distinguer, avec plus ou moins de détail selon le contexte et les outils de modélisation utilisés, les types suivants :
- An (alphanumérique de n caractères).
- Caractère (variable, long).
- Nn.p (champ numérique de n chiffres significatifs et p chiffres après la virgule - précision).
- Entier (court, long), décimal, réel (double précision), monétaire.
- Dn (champ calendaire de n caractères significatifs).
- Date, heure, date + heure.
- Sn (type spécial de n caractères significatifs)
- Booléen, binaire, mémo, image, son, etc.
Ces longueurs indiquées ne permettent pas réellement une estimation du volume qu'occuperont ces données, car, suivant la technique de mémorisation retenue ultérieurement aux niveaux logique et physique, la taille en octets peut être très variable. De plus, selon certains systèmes, le choix du mode de représentation informatique peut être un paramètre d'optimisation. On peut cependant, pour chaque cible de base de données envisagée, se doter d'une règle d'équivalence entre les longueurs indiquées selon les types de données et leur occupation probable en octets.
II-G-3-c. Domaines de valeur▲
Il s'agit de contraintes que doivent respecter les valeurs d'une propriété. Celles-ci peuvent porter sur :
- des valeurs minimales, maximales ;
- des valeurs par défaut ;
- une liste limitée de valeurs à respecter.
II-G-3-d. Types utilisateurs▲
Un type utilisateur est une particularisation nommée de type de données pour lequel on fixe un type, une longueur et éventuellement un domaine de valeur.
Exemple :
- Nom standard : A40.
- Ligne adresse : A60.
- Taux en % : N5.2.
- Oui Non : Booléen 0=non 1 = oui.
II-G-3-e. Nombre d'occurrences des entités et relations▲
Il s'agit d'évaluer le nombre maximum d'occurrences des entités et des relations que l'on voudra avoir dans la future base pour constituer la mémoire immédiate du système d'information.
II-G-3-f. Mémoire immédiate, mémoire à long terme▲
Jusqu'à présent, dans la modélisation conceptuelle des données, aucune notion de leur durée de vie n'a été prise en compte ; la mémoire du système d'information était considérée comme illimitée. Toute information, quelle que soit son ancienneté, était théoriquement disponible dès qu'elle était exprimée dans le modèle. Les préoccupations économiques du modèle organisationnel de données ne peuvent se satisfaire de cette hypothèse. On distingue alors deux mémoires (voir figure 10.1) :
- La mémoire immédiate, contenant l'ensemble des données immédiatement accessibles aux traitements ; généralement « en ligne » sur les mémoires du système informatique.
- La mémoire à long terme, composée des archives intégrales ou condensées des informations anciennement présentes dans la mémoire immédiate ; la disponibilité de ces informations sera rarement immédiate et présentera fréquemment une structure adaptée à l'économie de stockage.
Ces deux mémoires sont cohérentes et compatibles, car elles proviennent toutes les deux des spécifications initiales du modèle conceptuel de données. Au moment de passer au modèle organisationnel de données, le concepteur doit se prononcer sur la « profondeur » de la mémoire immédiate du système d'information ; donc définir la durée de vie des informations.
II-G-3-g. Durée de vie des entités et des relations▲
L'ensemble de la mémoire immédiate est constitué d'occurrences d'entités et de relations décrites par des propriétés. La durée de vie concerne celle des occurrences. On distingue, suivant les règles de détermination de la durée de vie, deux catégories qui s'appliquent aux entités et relations :
- Les entités ou relations à durée de vie indéterminée (ou permanentes) : la durée de vie d'une occurrence n'est pas déterminée lors de sa création ; la suppression d'une occurrence dépend soit d'un événement, soit d'une règle indépendante de l'ancienneté de cette occurrence. Exemple : un compte clos depuis une année est à archiver.
- Les entités ou relations à durée de vie limitée : la durée de vie d'une occurrence est fixée lors de sa création, et généralement constante pour le concept. Exemple : les écritures sont archivées au bout de 6 mois.
Pour les concepts permanents, le nombre maximum d'occurrences présentes dans la mémoire immédiate tient compte de l'effectif au chargement initial et de la fréquence de création.
Pour les concepts à durée de vie limitée, le nombre maximum d'occurrences dans la mémoire immédiate est évalué par la fréquence de création de ce concept, multipliée par la durée de vie.
En fait, la détermination de la durée de vie des occurrences de concepts résulte d'un compromis entre :
- la profondeur de la mémoire immédiate ou la disponibilité des informations ;
- le volume occupé par ces mêmes informations.
II-G-3-h. Conséquences de la durée de vie sur l'élaboration du MOD▲
Le modèle conceptuel de données a été élaboré sans tenir compte de la durée de vie associée aux concepts. Certaines informations calculées apparaissant dans des résultats n'ont pas été considérées comme devant être directement prises en compte dans le modèle conceptuel (voir figure 10.2).
La règle de calcul, construite sur des propriétés conceptuelles, permettant d'obtenir cette information calculée sera spécifiée dans les traitements (MCT ou plus probablement MOT puis MLT).
Par exemple, pour l'entité CLIENT, le chiffre d'affaires depuis le début de l'année est égal à la somme, sur toutes ses commandes passées depuis le début de l'année, du montant total de la commande (propriété éventuellement calculée elle aussi).
Durées de vie :
- Client, article : permanents.
- Facture, passer, ligne : 3 mois.
Règles de calcul :
- Montant total commande = ∑ quantité livrée x prix vente.
- Chiffre d'affaires annuel client = ∑ montant total commande.
Ainsi exprimée, cette règle permet toujours, sémantiquement, de calculer ce chiffre d'affaires cumulé, sans en exiger la mémorisation.
Si la durée de vie des commandes est inférieure à un an (trois mois par exemple), il sera impossible de reconstituer ce cumul au-delà de la durée de vie des commandes.
Cette situation se reproduit chaque fois que des informations, termes d'une règle de calcul, ont une durée de vie inférieure à l'information résultante, non mémorisée.
On doit alors considérer cette information résultante comme une information primaire, et la modéliser comme une propriété d'une entité ou relation.
Pour accueillir cette nouvelle propriété, le concepteur peut être conduit à :
- affecter cette propriété à une entité ou à une relation existant déjà ;
- créer une nouvelle entité type ou une nouvelle relation type ;
- modifier la collection d'une relation déjà existante.
Ces modifications s'expriment sur le modèle organisationnel de données. Elles ne remettent cependant pas en cause la signification du modèle conceptuel initial.
En pratique, le concepteur élaborera son modèle organisationnel des données à partir du modèle conceptuel de données. Celui-ci est essentiellement sémantique ; le modèle organisationnel de données intègre les redondances d'informations dues à la prise en compte de la durée de vie différente des informations (voir figure 10.3).
À cette occasion, le concepteur pourra également élaborer un autre modèle organisationnel des données pour la mémoire à long terme, ne comprenant que les informations que l'on désire archiver.
Étant donné la nature du problème, sa prise en compte dans la construction d'un modèle organisationnel de données interviendra plus vraisemblablement en étude détaillée.
Il ne faut pas confondre la notion d'archivage, liée à la durée de vie des informations dans la mémoire immédiate, avec la notion d'historisation liée à la conservation des valeurs antérieures des propriétés d'une occurrence d'entité ou de relation (voir « HistorisationHistorisation » au chapitre 7).
Les procédures organisationnelles et informatiques d'archivage doivent être spécifiées lors de l'étude détaillée.
II-G-3-i. Quantification des cardinalités▲
Le nombre d'occurrences des entités est généralement assez aisé à estimer ; celui des relations est beaucoup plus difficile, compte tenu de la nature même des relations : des associations entre objets. Dans la plupart des cas, ce dénombrement s'effectuera à partir du nombre d'occurrences d'une entité de sa collection et de la quantification de la cardinalité de la « patte ».
Dans le modèle conceptuel de données, les cardinalités maximales multiples sont spécifiées jusqu'à présent par n. Il faut, au niveau du MOD, évaluer cette multiplicité. Prenons par exemple la modélisation de la figure 10.4.

La valeur de la cardinalité maximale n de Facture par rapport à ligne doit être précisée. La valorisation des cardinalités peut s'exprimer par :
- la cardinalité maximale ;
- la cardinalité maximale à 95 % ;
- la cardinalité modale ;
- la cardinalité moyenne.
Le choix de telle ou telle valeur se fera selon l'intérêt dans le processus d'optimisation ; dans tous les cas, au niveau du MOD, on définira la cardinalité moyenne, en particulier pour calculer le nombre d'occurrences des relations.
La quantification de la cardinalité mini s'exprime par le taux de participation. En effet, au niveau conceptuel, la cardinalité mini peut prendre les valeurs 0 (optionnelle) ou 1 (obligatoire). Le taux de participation ne se détermine que pour les cardinalités mini à 0 et mesure le pourcentage d'occurrences de l'entité qui participent aux occurrences de la relation. Il prend donc une valeur décimale comprise entre { ] 0, 1 [ .}
La quantification de la cardinalité moyenne n'est pas toujours facile. Soit on fixe arbitrairement cette cardinalité, soit à partir de statistiques sur les populations d'entités concernées par la relation, il est possible de la déterminer de façon plus précise. Par exemple, pour l'exemple précédent, on pourrait avoir la distribution des lignes de facture par facture illustrée par la figure 10.5.
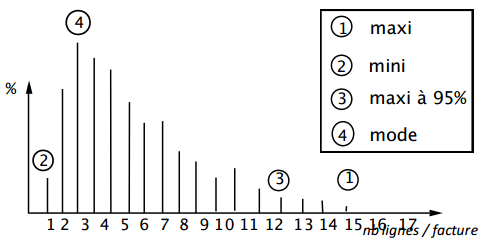
Pour notre exemple, on peut supposer que la loi de répartition des cardinalités est approximativement triangulaire, comme le montre la figure 10.6.
Étant donné une telle répartition triangulaire, on peut calculer la cardinalité moyenne par la formule suivante :
- cardinalité moyenne = [(m + 2M + N) / 4] x P
avec :
- m = valeur mini (0 exclu)
- M = valeur modale
- N = valeur maxi
- P = taux de participation
Par exemple, si M = 3 ; N = 17 ; m = 1 ; P = 1 ; on a :
- cardinalité moyenne = ((1 + 2 x 3 + 17) / 4) x 1 = 6
Cette loi de distribution triangulaire permet d'estimer les moyennes sur des répartitions dissymétriques (assez fréquentes dans la réalité) et donne d'assez bons résultats pratiques.
Notons que la cardinalité moyenne d'une cardinalité (1,1) est toujours 1 et que la cardinalité moyenne d'une cardinalité (0,1) est égale au taux de participation.
Dans le cas de plusieurs populations (voir figure 10.7), on recherche la moyenne de chaque population, puis on calcule la moyenne pondérée.
Par exemple :
- moyenne de la population A = VA, % de la population totale = a
- moyenne de la population B = VB, % de la population totale = b
- moyenne de la population C = VC, % de la population totale = c
- moyenne pondérée = a.VA + b.VB + c.VC
II-G-3-j. Évaluation du volume global du modèle organisationnel de données▲
Le chiffrage se fait de proche en proche dans le modèle organisationnel de données. En effet si le concepteur n'a pas de problèmes majeurs pour définir la taille des propriétés, il peut avoir plus de difficultés pour estimer la population des entités, des relations et la cardinalité moyenne des relations, n'ayant pas toute l'information nécessaire. Il est alors conduit à tirer parti au maximum des estimations dont il dispose pour chiffrer son modèle.
La quantification des propriétés, entités relations et cardinalités est généralement présentée sous forme de tableaux où figurent les différentes valeurs estimées (voir figure 10.8).
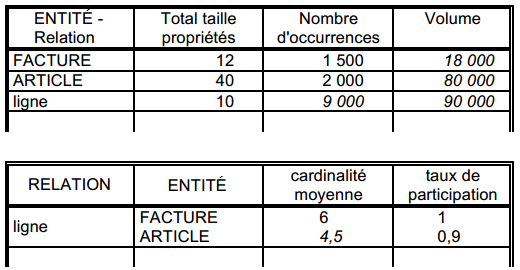
À partir des éléments quantifiés précédemment déterminés, le concepteur peut procéder à une évaluation brute du volume total des données à mémoriser, pour la mémoire immédiate.
Ce chiffrage en volume brut n'estime que l'occupation des données utiles. Il ne tient pas compte du volume résultant du mode de mémorisation des pattes entre entités et relations. Cet aspect dépendra du mode de mémorisation informatique et sera chiffré au niveau du modèle logique de données en tenant compte de l'optimisation et des caractéristiques techniques du système de gestion de base de données utilisé.
Il faut considérer cette estimation en volume brut comme une valeur minimum pour l'occupation ultérieure du volume informatique. Elle peut cependant, en introduisant un facteur multiplicatif (1,5 à 2,5 suivant les technologies), fournir une indication pour le volume de la base de données résultante.
II-G-4. Répartition organisationnelle des données▲
Jusqu'à présent, nous avons raisonné sur un MOD global, très proche dans son contenu du MCD. Il représente l'ensemble des données à mémoriser utilisables dans le domaine d'activité étudié.
La modélisation organisationnelle des données va également se préoccuper de la répartition d'utilisation de ces données suivant les différentes unités organisationnelles.
La connaissance de cette répartition organisationnelle des données présente un intérêt certain pour orienter ultérieurement la répartition informatique des données, en particulier dans des environnements clients / serveurs.
II-G-4-a. MOD local à une unité organisationnelle▲
L'unité organisationnelle recouvre généralement un ensemble de postes représentant par exemple un service ou un site géographique. Les utilisateurs d'une unité organisationnelle ont une vue commune et partagée d'un ensemble de données : le MOD local. Le MOD local et l'unité organisationnelle sont donc un moyen d'exprimer, du point de vue de l'utilisateur, les données accessibles par un ensemble de postes.
Le MOD local est un sous-ensemble du MOD global en termes :
- d'entités types, de relations types et de propriétés ;
- d'occurrences d'entités ou de relations ; par exemple une agence (unité organisationnelle) ne gère que les contrats de son secteur.
L'expression d'un MOD local se représente pour chaque unité organisationnelle :
- par un schéma des entités, relations et propriétés utilisées ;
- par un tableau précisant les éventuelles restrictions sur les occurrences disponibles.
Ce découpage du MOD global en MOD locaux permet d'apprécier le degré de partage ou de séparation des données d'un système d'information en fonction de l'organisation adoptée. On peut ainsi mettre en évidence :
- les données communes à l'ensemble du domaine ;
- les données partagées entre certaines unités ;
- les données privées à une unité.
Lorsqu'un partage existe entre plusieurs unités organisationnelles et en cas de répartition informatique envisagée, il peut être utile de préciser, si c'est possible, quelle unité organisationnelle ferait référence en cas de divergence entre le contenu des informations partagées.
II-G-4-b. Accessibilité des données d'un MOD local▲
L'accessibilité des données d'un MOD local s'exprime par les actions élémentaires que peuvent effectuer sur ce sous-ensemble de données les traitements réalisés dans le site organisationnel.
Ces différents types d'accès, en lecture (L), en modification (M), en création (C) et en suppression (S) sont précisés sur le MOD local généralement sur un tableau récapitulant les restrictions de disponibilités, les partages et les actions autorisées.
La notion d'accessibilité d'un MOD local peut s'assimiler à un macro sous-schéma (voir « Sous-schéma organisationnel de données » dans la modélisation organisationnelle des traitements) au niveau d'une unité organisationnelle.
II-G-5. Sécurité des données▲
La sécurité des données définit des restrictions d'accès aux données mémorisées pour certaines catégories d'utilisateurs. Ces restrictions peuvent concerner un type d'action limité (L, M, C, S) soit aux entités, relations ou propriétés du MOD global ou local, soit à une sous-population des occurrences d'entités ou des relations. La sécurité d'accès aux données comprend la limitation d'actions à certaines personnes (seul le responsable de la comptabilité peut modifier une écriture comptable) et intègre aussi les aspects de confidentialité (accès à certaines informations du dossier de personnes dites « sensibles »).
La sécurité d'accès s'exprime, selon les cas, au niveau du MOD global ou des MOD locaux, et passe par la définition de catégories ou profils d'utilisateurs. Pour chaque profil, on précise les éventuelles restrictions d'accès envisagées. En pratique, on présente ces restrictions sous forme de tableau faisant référence aux schémas MOD comme celui de la figure 10.10. Selon les cas, la sécurité d'accès aux données peut s'exprimer par une restriction par rapport à une autorisation générale, ou une autorisation par rapport à une restriction générale.
Bien que similaires et pouvant conduire à des modes d'implémentation informatiques proches, la notion d'accessibilité aux données des unités organisationnelles et la notion de sécurité d'accès ont cependant des finalités différentes. L'accessibilité vise apprécier la répartition et le partage de l'utilisation des données en vue d'une éventuelle répartition informatique. La sécurité concerne les conditions d'accès aux données par des profils d'utilisateurs, même en l'absence totale de préoccupation de répartition organisationnelle ou informatique.
II-H. Chapitre 11 Confrontation données / traitements▲
II-H-1. Rôle et nécessité▲
Bien que visant le même objectif global, assurer la cohérence et la qualité du futur système d'information, il convient au préalable de distinguer confrontation données / traitements et validation, et ceci d'autant plus que, par le passé, ces deux notions furent souvent confondues.
La confrontation cherche à vérifier la cohérence entre les modélisations des données et des traitements ; c'est une technique spécifique aux concepteurs et propre à la méthode Merise.
La validation cherche à vérifier que les solutions proposées sont conformes aux besoins ; c'est un travail entre l'équipe de projet et la maîtrise d'ouvrage (décideur ou futurs utilisateurs) représentée par le groupe de validation (voir « Groupe de validation » dans Structures et intervenants).
Dans le déroulement du cycle d'abstraction, le concepteur a alternativement élaboré les modèles de données et de traitements. On a alors constaté la relative indépendance entre données et traitements évoquée dans la première partie.
Le modèle conceptuel de données a été élaboré sans approfondir les conditions d'utilisation des informations modélisées.
Les modèles conceptuel et organisationnel de traitements ont pu être élaborés sans insister sur les informations utilisées.
Or, chaque opération ou tâche exprimée dans le modèle conceptuel ou organisationnel de traitements interagit avec les données mémorisées. Si, dans le processus d'élaboration d'un modèle conceptuel de données, la méthode Merise préconise une structuration des informations en fonction de leur signification, il est indispensable de s'assurer régulièrement que leur utilisation est compatible avec leur signification modélisée.
Enfin, la seule structuration des informations perceptible par l'utilisateur est celle exprimée dans les messages, structuration fortement conditionnée par les traitements associés à ces messages.
On doit donc confronter :
- Une perception globale, unitaire, abstraite, représentée par le modèle conceptuel de données, et maîtrisée essentiellement par les concepteurs.
- Une juxtaposition de perceptions partielles, redondantes, contingentes à des traitements, représentées par les messages et partagées entre tous les utilisateurs.
Cette confrontation consiste schématiquement à :
- Vérifier si les traitements disposent bien des données nécessaires.
- Contrôler si les données sont utilisées dans les traitements.
Dans les deux cas, on s'assurera que la signification de la structuration des données est cohérente avec leurs utilisations dans les traitements.
II-H-2. Différents modes de confrontation▲
Dans son principe, la confrontation données / traitements sera toujours une simulation du fonctionnement des futurs traitements utilisant les futures données.
En pratique, plusieurs techniques de confrontation sont utilisées qui dépendent du degré de détail significatif et de la couverture du domaine, liés à la démarche. Elles seront assez grossières en étude préalable pour s'affiner en étude détaillée.
En étude préalable :
- Relecture croisée MCD / MCT.
- Grille de cohérence globale MCD-MOD / MOT.
En conception générale (première phase de l'étude détaillée)
- Grille de cohérence globale MCD-MOD / MOT
En conception détaillée (deuxième phase de l'étude détaillée)
- Confrontation détaillée entre MCD-MOD et les modèles externes (expression formalisée du contenu des messages, règles de traitement et actions d'une tâche).
- Maquettage impliquant le MCD-MOD et les futures tâches à automatiser. Cette technique peut, selon l'outil de maquettage utilisé, contribuer très efficacement à la confrontation.
II-H-3. Relecture croisée MCD / MCT▲
En étude préalable, et particulièrement dans les premiers travaux de conception des modèles conceptuels futurs, on vérifiera qu'il y a une bonne concordance entre le sous-ensemble représentatif du domaine retenu pour le MCD et celui retenu pour le MCT.
En relisant le MCT, on vérifie si les objets et associations évoqués dans les opérations sont modélisés dans le MCD. Inversement, en relisant le MCD, on vérifie que les entités et relations représentées trouvent une utilité dans le MCT.
Bien que techniquement très sommaire, cette relecture croisée s'avère en pratique d'une bonne efficacité et permet fréquemment de recadrer les deux modélisations.
II-H-4. Grille de cohérence globale MCD-MOD / MOT▲
Ce raisonnement consiste à contrôler si les tâches du MOT disposent des données nécessaires à leur fonctionnement (du moins en termes d'entités et de relations), et que les entités et relations du MCD/MOD sont utilisées dans les tâches. On utilise la technique de la grille de cohérence globale. Nous présentons la technique manuelle dont les principes peuvent par ailleurs s'automatiser à travers des outils d'aide à la conception.
Sur un tableau, on indique (voir figure 11.3)
- en colonne, les différentes entités et relations du MCD-MOD, dans un ordre quelconque ;
- en ligne, les différentes tâches du MOT en respectant autant que possible la chronologie de ces traitements.
Sur chaque case du tableau, on indique les actions effectuées par chaque tâche du MOT sur toute entité ou relation du MCD-MOD.
Selon les traitements réalisés, la tâche peut comporter aucune, une ou plusieurs actions élémentaires sur les données. Si la tâche est entièrement manuelle, elle ne peut accéder à aucune donnée mémorisée ; les cellules correspondantes restent alors vides.
Pour illustrer cette grille de cohérence, prenons le cas assurance déjà abordé, dont les figures 11.1 et 11.2 rappellent le MCD-MOD et le MOT.
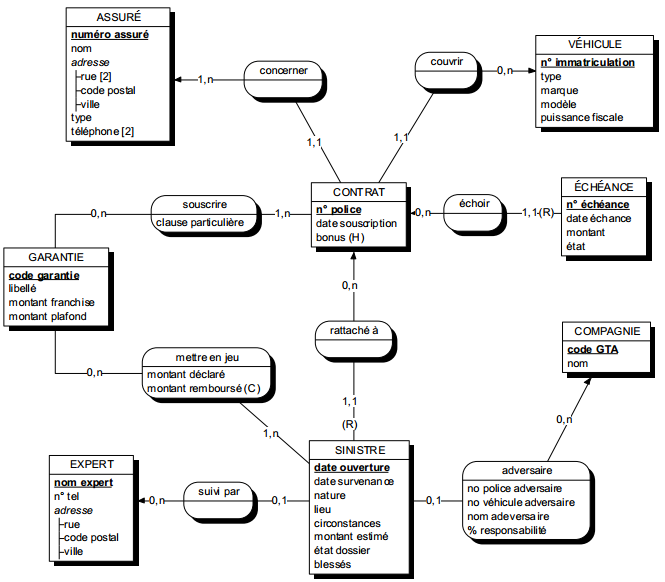
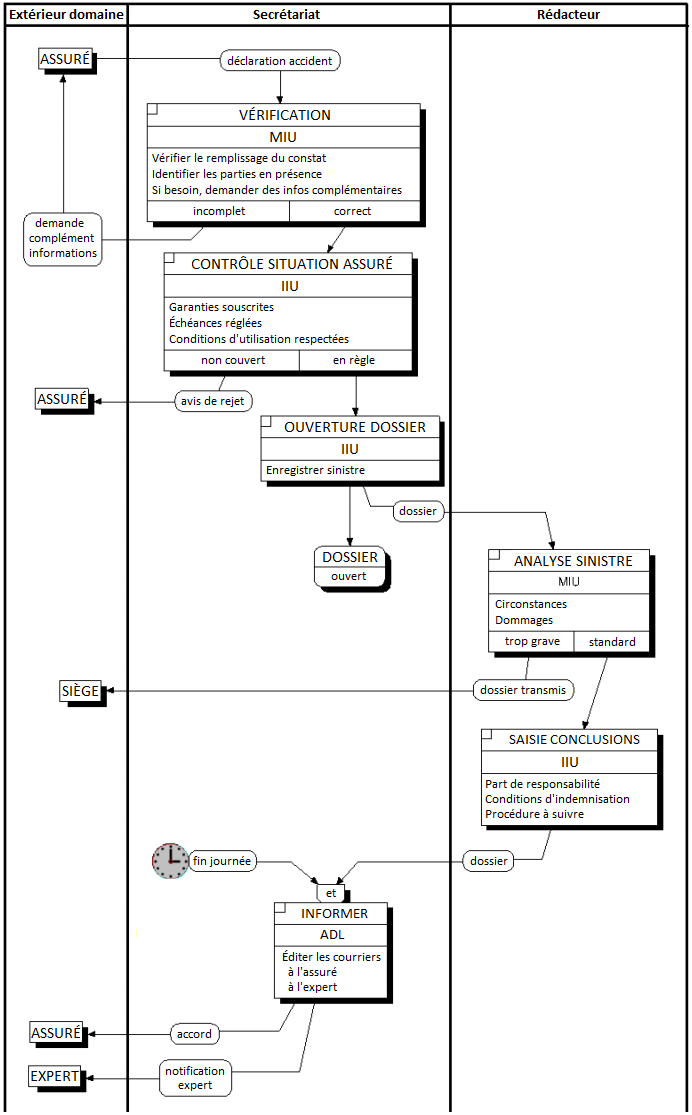
Pour chaque tâche de cette procédure, on précise la ou les actions sur les entités et relations du MCD (CREation, LECture, MODification, SUPpression), comme l'illustre la figure 11.3.
Entités et relations (liste partielle)
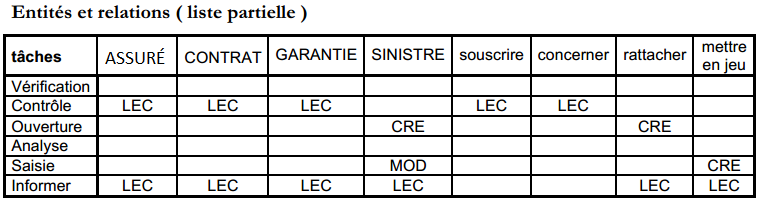
Lorsque le tableau est entièrement rempli, on procède alors à une double relecture :
- Pour chaque ligne, on s'assure que les actions élémentaires prévues sont bien cohérentes par rapport à la désignation de la tâche ; au besoin, on procède aux ajustements nécessaires dans la description de la tâche.
- Pour chaque colonne, on s'assure que, pour chaque entité ou relation, on retrouve au niveau d'une occurrence la séquence générale suivante :
Le concepteur doit prêter attention à certaines situations dont quelques-unes peuvent révéler une grave anomalie.
- Entité ou relation sans aucune action
Cette situation peut provenir de plusieurs cas :
- Les entités ou relations ne sont pas utilisées par des tâches du sous-ensemble représentatif ; il faut éventuellement réajuster la concordance du sous-ensemble représentatif (données ou traitement).
- Les entités ou relations avaient un intérêt pour des tâches qui sont manuelles ; il faudra en tenir compte au niveau du MOD.
- Entité ou relation jamais créées
Cette situation peut provenir des cas suivants :
- La tâche chargée de la création n'appartient pas au sous-ensemble représentatif.
- L'action de création a été « oubliée ».
- Entité ou relation créées par plusieurs opérations ou tâches
Bien que cette situation soit théoriquement normale, si elle met en jeu plusieurs postes, elle peut alors poser des problèmes organisationnels (responsabilité de création).
- Entité ou relation avec propriété(s) non modifiée(s)
Aucune action de modification n'a été recensée pour cette entité ou cette relation, ses propriétés ne peuvent donc changer de valeurs, cela peut être volontaire dans le cas de données sensibles, sinon il s'agit probablement d'un oubli.
- Entité ou relation jamais supprimées
Le concepteur doit vérifier que la fréquence des créations de cette entité ou relation ne va pas conduire à une saturation de la mémoire. Cette situation est assez fréquente ; on néglige trop souvent dans une étude le processus d'épuration de la mémoire courante (archivage, durée de vie des informations).
Cette technique simple permet de détecter rapidement un grand nombre d'incohérences entre données et traitements. En revanche, elle n'est pas adaptée à une présentation aux gestionnaires et utilisateurs du domaine. Il est recommandé de procéder au contrôle de cohérence global avant de présenter les modèles aux gestionnaires et utilisateurs du domaine.
Bien que cette technique puisse sembler lourde à appliquer manuellement, elle reste cependant réalisable sur des projets moyens. Le recours à des outils permet évidemment d'automatiser ces diagnostics.
II-H-5. Confrontation algorithmique détaillée▲
En conception détaillée, les techniques précédentes sont insuffisantes et l'on doit descendre au niveau des différentes propriétés. À ce stade, le MCD et le MOD sont complètement décrits (ou en voie d'achèvement), et les concepteurs peuvent spécifier plus précisément le contenu des tâches.
Cette analyse détaillée des tâches comprend :
- la description des messages en entrée et en sortie en précisant les informations contenues et leur structure, ainsi que leurs conditions de synchronisation ou d'émission ;
- les règles de traitement appliquées sur ces informations ;
- les actions de consultation et de mise à jour des données mémorisées.
Cette description exprime la vision des informations contingente aux traitements effectués par la tâche, seule perception connue des utilisateurs. Cette perception modélisée est appelée modèle externe.
Le processus de confrontation détaillée consiste à vérifier si, sous des apparences parfois très différentes, modèle organisationnel de données et modèle externe sont compatibles en signification et structure. Les principes de cette confrontation détaillée sont présentés sur la figure 11.4
II-H-5-a. Principes de la confrontation détaillée▲
Cette technique consiste à confronter le modèle organisationnel de données avec les modèles externes associés à chaque tâche du modèle organisationnel de traitements (voir figure 11.5).
Cette tâche, à laquelle est associé un modèle externe, est-elle cohérente par rapport à un modèle organisationnel de données défini par ailleurs ?
Une tâche peut comporter plusieurs modèles externes, en particulier si elle émet plusieurs résultats conditionnels de nature et de contenu différents. En général, un modèle externe se compose :
- d'un message dont le contenu est modélisé par une vue externe ;
- des règles de traitement ;
- des actions sur un sous-schéma de données.
II-H-5-b. Modélisation du contenu d'un message : vue externe▲
Chaque message est constitué d'un ensemble structuré d'informations représenté par une vue externe de données. La formalisation de cette structure peut s'effectuer soit en utilisant le formalisme entité - relation, soit en termes de groupes de données structurés ; dans les deux cas, seule la règle de vérification (non-répétitivité) est utilisée. Rappelons que dans l'expression formelle du contenu d'un message, il ne s'agit pas de reconstituer un « pseudomodèle » conceptuel de données, mais d'exprimer strictement ce que l'on voit. On constate généralement que les types de structures présents sont assez simples : unitaire, hiérarchique, arborescent.
Dans le cas où des messages en entrée d'une tâche seraient soumis à une synchronisation, il faut modéliser un message fictif résultant de la composition des messages, en fonction de l'expression logique de synchronisation. Par exemple :
- Deux messages A et B synchronisés par une expression OU donneront naissance à deux vues externes.
- Deux messages A et B synchronisés par une expression ET ne donneront naissance qu'à un message fictif résultant de la fusion des messages, donc à une vue externe.
- Trois messages A, B et C synchronisés par une expression (A ET B) OU C produiront deux vues externes ; l'une concernant (A ET B), l'autre concernant C.
La figure 11.6 illustre le contenu du message associé à la tâche Saisie conclusions, c'est-à-dire les conclusions issues de la tâche manuelle précédente d'Analyse du sinistre (voir figure 11.2)

En mettant en évidence les répétitions (règle de vérification), le message peut être modélisé comme sur les figures 11.7a et 11.7b.
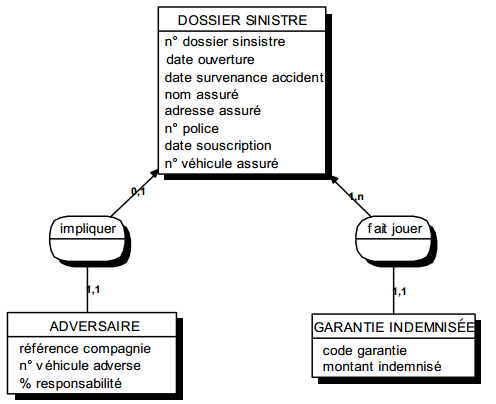

II-H-5-c. Expression des actions sur les données mémorisées▲
Les données mémorisées sont représentées par le modèle conceptuel ou organisationnel de données. L'accès à ces données ne peut se faire qu'à travers une tâche, données représentées par le sous-schéma conceptuel ou organisationnel de données.
Comme on l'a vu précédemment (dans « Sous-schéma de donnéesLe sous-schéma conceptuel/organisationnel de données » chapitre 8), on distingue quatre natures d'actions qui s'appliquent aux occurrences d'entité ou de relation. On obtient ainsi huit actions types :
- Créer entité ; créer une nouvelle occurrence d'une entité avec au minimum la valeur de son identifiant et souvent des valeurs de quelques propriétés.
- Modifier entité ; modifier des valeurs de propriétés d'une occurrence d'entité déjà existante, à l'exception de son identifiant. Cette action est également utilisée dans le cas où l'on affecte une première valeur à une propriété d'une occurrence déjà existante. Cette action intègre le fait que l'accès à l'occurrence à modifier doit être réalisé avant la modification.
- Supprimer entité ; supprimer de la mémoire une occurrence d'une entité existante. Par définition, l'ensemble des valeurs des propriétés associées disparaît de la mémoire. La suppression d'une occurrence d'une entité implique que les occurrences des relations liées à cette entité ont été supprimées auparavant. Cette action de suppression intègre le fait que l'accès à l'occurrence à supprimer doit être réalisé avant suppression.
- Consulter entité ; accéder à une occurrence d'une entité soit pour en consulter les valeurs des propriétés, soit pour y faire simplement référence, en particulier pour agir sur les relations.
- Créer relation ; créer une nouvelle occurrence d'une relation entre des occurrences d'entités existantes. Éventuellement des valeurs de propriétés peuvent être données. La création d'une nouvelle occurrence de relation exige qu'au préalable les occurrences d'entités composant sa collection aient été consultées ou créées.
- Modifier relation ; modifier des valeurs de propriétés d'une occurrence d'une relation déjà existante. Cette action est également utilisée dans le cas où l'on affecte une première valeur à une propriété d'une occurrence déjà existante. Cette action intègre le fait que l'accès à l'occurrence à modifier doit être préalablement réalisé avant la modification. Cette action ne s'applique pas dans le cas où l'on modifie la collection de l'occurrence de la relation. Il faut alors supprimer l'occurrence de l'ancienne relation pour créer l'occurrence de la nouvelle.
- Supprimer relation ; supprimer de la mémoire une occurrence d'une relation existante, ainsi que l'ensemble des valeurs de ses éventuelles propriétés.
- Consulter relation ; accéder à une occurrence de relation soit pour en consulter le contenu des propriétés, soit pour parcourir la relation afin d'atteindre une occurrence d'entité.
L'ensemble de ces actions types ne fait aucune hypothèse sur la technique utilisée ultérieurement pour réaliser ces accès. Ainsi, on supposera que l'accès à une occurrence d'une entité peut être réalisé à partir d'une valeur de son identifiant ou par le parcours de relations binaires fonctionnelles, et que l'on peut sélectionner en fonction d'une expression logique un sous-ensemble d'occurrences d'entité ou relation à partir de toute propriété de ces concepts.
II-H-5-d. Algorithme de confrontation détaillée▲
L'analyse complète de ces différents algorithmes a été faite dans le cadre des recherches [Tardieu, Nanci, Heckenroth 76] [Tardieu, Nanci, Pascot 79]. En outre, nous pensons que la technique de maquettage peut, sous certaines conditions, se substituer à cette procédure dont l'aspect fastidieux est indéniable.
Nous présentons ici les principes généraux de l'algorithme de confrontation détaillée en écartant les cas particuliers dont l'intérêt théorique est certain, mais dont la fréquence reste exceptionnelle. Pour dérouler l'algorithme, on dispose au préalable :
- de la vue externe de données ;
- du modèle conceptuel ou organisationnel de données ;
- de la tâche pour laquelle on connaît la fonction, même si les règles de calcul et les actions ne sont pas toujours formellement exprimées ;
Pour valider le modèle externe par rapport au modèle de données, on effectue les opérations décrites ci-après.
II-H-5-e. Équivalence propriété externe / propriété conceptuelle▲
À chaque propriété externe présente dans la vue externe, on recherche une correspondance dans le modèle conceptuel. Cette correspondance peut être :
- directe ; il y a équivalence stricte entre les deux informations ;
- via une relation ; la propriété externe est équivalente à une propriété conceptuelle vue à travers une relation (généralement une relation binaire fonctionnelle) ;
- via une règle de traitement ; on remplace alors la propriété externe par les propriétés conceptuelles évoquées dans la règle de traitement. Dans certains cas, surtout dans les restitutions, la règle génère une véritable structure complémentaire au modèle externe initial ; le concepteur a alors intérêt à expliciter cette structure de calcul (généralement des sommations) avant de poursuivre son algorithme de confrontation détaillée.
Certaines règles de traitement évoquent des propriétés conceptuelles sans se traduire par des propriétés externes ; il s'agit fréquemment de règles d'affectation de valeurs par défaut ou automatiques.
Pour chacune des propriétés conceptuelles ainsi évoquées, on relève l'entité ou la relation conceptuelles d'accueil. On note également s'il s'agit d'un identifiant et si la propriété externe était optionnelle dans le message.
Dans certains cas, des propriétés externes différentes correspondent aux mêmes propriétés conceptuelles, mais pour des occurrences distinctes. On prendra alors en compte ces deux occurrences du même concept en prenant soin de les distinguer par des indices. Par la suite, on les traitera comme des concepts différents.
Si l'on échoue dans cette première étape, la tâche représentée par son modèle externe est incompatible avec le modèle conceptuel. Il s'agit fréquemment de l'oubli d'une propriété dans le modèle conceptuel de données. C'est à cette étape que le modèle conceptuel de données s'enrichit progressivement en propriétés.
À l'issue de cette étape, pour chaque entité externe ou groupe de données composant le message, on dispose d'un ensemble d'entités et de relations conceptuelles évoquées par l'équivalence des propriétés. Ces entités et relations ne sont pas nécessairement interreliées. L'étape suivante va chercher à reconstituer des sous-ensembles connexes du modèle conceptuel correspondant à chaque entité externe.
II-H-5-f. Correspondance entité externe / sous-ensemble conceptuel▲
Cette opération s'applique à chaque entité externe ou groupe de données de la vue de données. Si parmi les entités et relations conceptuelles évoquées précédemment, on enregistre certains éléments isolés, le concepteur cherche à les relier à des éléments cités. On utilise des relations du modèle conceptuel non encore directement citées (simple ou par composition). Le concepteur devra s'assurer que la signification des relations utilisées correspond à celle du contexte de la tâche. Lors de cette opération, le concepteur peut mettre en évidence l'absence de certaines relations conceptuelles ou une divergence de signification.
Une fois le sous-ensemble reconstitué, il faut s'assurer que cette structure conceptuelle est équivalente à la structure d'entité externe. Cette vérification introduit la notion de pivot. Le pivot d'une entité externe est une entité ou relation conceptuelle du sous-ensemble correspondant, tel que, à partir de l'occurrence de ce pivot, l'on peut déterminer une seule occurrence de chacun des autres éléments du sous-ensemble. Dans ce cas, la règle d'unicité des propriétés de l'entité externe est complètement assurée par la structure conceptuelle correspondante. On peut dire également que les occurrences de l'entité externe sont de même distinguabilité que les occurrences du pivot.
La détermination du pivot s'appuie sur trois règles du formalisme entité- relation :
- une relation porteuse d'une dépendance fonctionnelle (généralement une relation binaire à cardinalité maxi = 1) permet, à partir d'une occurrence d'une entité, de faire référence à une seule occurrence d'une autre entité via cette relation ;
- une occurrence de relation fait référence à une occurrence de chacune des entités qui la compose ;
- à une occurrence de chacune des entités composant une relation, il n'y a au plus qu'une occurrence de cette relation.
La figure 11.8 illustre la correspondance entre les entités externes et le sous-ensemble conceptuel.
Les échecs rencontrés lors de cette étape concernent fréquemment l'unicité du pivot. Cela est souvent dû à une divergence de cardinalité dans les relations. Dans ce cas, sauf situations très particulières, il y a incohérence entre la structure de la vue externe et le modèle conceptuel de données. Le concepteur doit remédier à cette situation soit en modifiant la tâche, soit en remettant en cause le modèle conceptuel de données. Dans tous les cas, il s'agit d'un motif grave d'incohérence.
À l'issue de cette opération, le concepteur a réussi à reconstituer, pour chaque entité externe ou groupe de données, le sous-ensemble conceptuel correspondant. Il faut maintenant effectuer une opération semblable pour les éventuelles relations externes.
 |
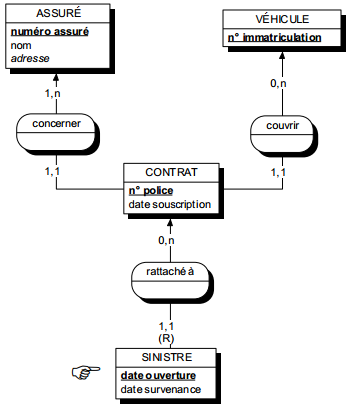 |
 |
 |
 |
 |
II-H-5-g. Correspondance relation externe / relation conceptuelle▲
Les relations externes sont généralement binaires fonctionnelles dues à la structure hiérarchique des vues externes. Il s'agit de retrouver quel élément du modèle conceptuel correspond à la relation externe. Il peut s'agir :
- d'une relation conceptuelle dont la collection doit être constituée des pivots des entités externes ;
- d'une patte d'une relation conceptuelle si l'un des pivots est constitué par une relation conceptuelle ;
- du partage d'entités conceptuelles communes aux deux structures correspondant aux entités externes reliées.
Dans tous les cas, il faut s'assurer que les cardinalités conceptuelles sont compatibles avec la cardinalité externe exprimée. Cette compatibilité concerne l'unicité opposée à la multiplicité.
Dans l'exemple de la figure 11.8, la relation externe Impliquer est équivalente au partage de Sinistre et la relation externe Fait jouer est équivalente à la patte Sinistre de relation conceptuelle Mettre en jeu.
À l'issue de cette opération, on a reconstitué d'une manière statique la correspondance entre le message et le modèle conceptuel de données. On retrouve là la notion de sous-schéma conceptuel de données associé à une tâche.
Cette séquence de confrontation est suffisante pour tous les modèles externes dits en consultation qui concernent généralement des restitutions d'informations. Pour les modèles externes en mise à jour, c'est-à-dire qui modifient le contenu de la mémoire, il faut maintenant s'assurer que les actions envisagées sont possibles.
II-H-5-h. Prise en compte des actions▲
À chaque entité ou relation conceptuelles évoquées, le concepteur va préciser les actions (créer, modifier, supprimer, consulter) correspondant aux intentions de la tâche. Ce choix peut être la source de discordances qui peuvent conduire jusqu'à la remise en cause du rôle de la tâche, voire de sa place dans le modèle organisationnel. Suivant les types d'actions retenus, plusieurs cas se présentent.
- Création, modification, suppression d'une occurrence d'entité ; il faut impérativement que l'identifiant de l'entité soit présent dans les propriétés invoquées par le message.
-
Consultation d'une occurrence d'une entité ; le concepteur doit systématiquement se poser les questions suivantes :
- S'agit-il d'une redondance voulue dans le message ?
- L'entité auquel il est fait référence est-elle utilisée pour créer une occurrence de relation ; surtout si l'identifiant de cette entité est explicitement citée dans le message ?
Cette dernière question permet de mettre parfois en évidence l'oubli d'une relation binaire fonctionnelle entre l'une des entités que l'on crée et l'entité que l'on consulte.
- Création, modification, suppression d'une occurrence de relation : il faut impérativement que les identifiants des entités composant la collection de cette relation soient présents dans les propriétés invoquées dans le message.
- Consultation ou parcours d'une occurrence de relation : s'il s'agit d'une relation binaire fonctionnelle, il suffit de connaître l'occurrence de l'entité origine (côté cardinalité maxi = 1) ; dans les autres cas, il faut connaître l'ensemble des identifiants des entités de sa collection.
Prenons l'exemple du sous-schéma conceptuel des données de la figure 11.9.
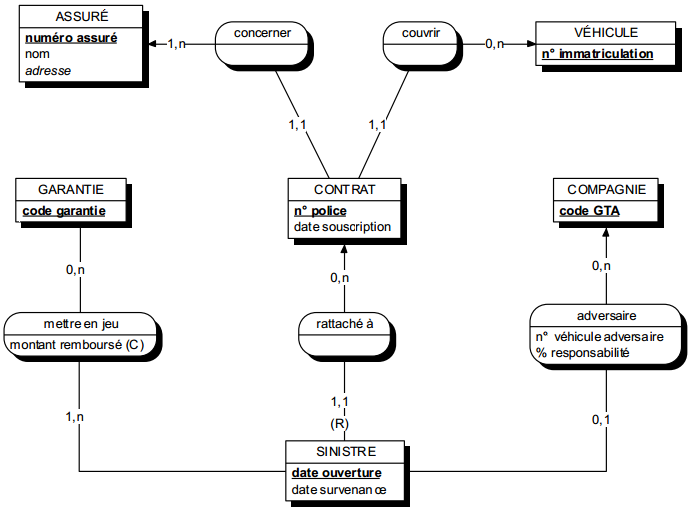 |
 |
On doit normalement retrouver les actions déjà envisagées dans la grille de cohérence.
À l'issue de cette opération, le concepteur a pratiquement vérifié que le traitement envisagé par la tâche est possible. Il reste toutefois à vérifier si certaines notions exprimées dans le modèle conceptuel de données sont intégralement prises en compte dans la tâche, du moins pour ce qui peut la concerner.
II-H-5-i. Actions induites▲
Pour chaque occurrence d'entité créée, le concepteur doit examiner toutes les relations conceptuelles auxquelles participe cette entité. Si la cardinalité minimum est 1, alors une occurrence de la relation concernée doit être également créée dans cette même tâche. Cela peut parfois conduire à une révision de la vue externe.
Pour chaque occurrence d'entité supprimée, le concepteur doit vérifier soit qu'il n'y a plus d'occurrence de relation reliée à cette entité, soit que les suppressions de ces occurrences interviendront dans cette tâche. Là encore, cela peut conduire à une révision de la vue externe, voire de l'objet de la tâche.
Rappelons également que, dans le cas de contraintes logiques interrelations, le concepteur doit vérifier que cette contrainte est respectée si l'une des relations concernées est mise à jour dans la tâche.
II-H-5-j. Redondance dans le message▲
Pour toutes les entités et relations conceptuelles consultées, dans un modèle externe en mise à jour, le concepteur doit s'interroger sur la présence, dans le message, de propriétés leur appartenant, autres que les identifiants. Théoriquement, ces informations n'apportent aucun élément nouveau pour la mémoire du système. On peut donc les considérer comme superflues, et l'on peut même proposer de fournir la valeur connue à l'utilisateur (pour des motifs de contrôle essentiellement). Techniquement, on pourra considérer ces informations comme des zones de sortie exclusives dans le futur écran associé à la tâche.
Cependant, des différends peuvent surgir sur la nécessité de ces informations dans le message, révélant parfois une distorsion sur le rôle de la tâche et de ses actions associées.
II-H-5-k. Propriétés externes absentes▲
À chaque entité ou relation conceptuelles créées, le concepteur doit consulter la liste des propriétés conceptuelles décrivant cette entité ou cette relation. Il constate alors que certaines de ces propriétés ne sont pas évoquées directement ou indirectement dans le modèle externe. Il doit s'interroger sur cette absence et s'assurer qu'elle est justifiée. Ce dernier contrôle ne peut pas conduire à une incohérence, tout au plus à l'enrichissement du message associé à la tâche.
L'ensemble de ces contrôles effectués sans échec permet de garantir la compatibilité entre le modèle conceptuel ou organisationnel de données et les vues externes associées aux tâches du modèle organisationnel de traitements. Il faut noter que cette confrontation détaillée permet d'obtenir :
- un enrichissement du modèle conceptuel ou organisationnel de données, en particulier de ses propriétés ;
- une formalisation précise du contenu des messages associés aux tâches ;
- une expression formalisée des règles de traitement ;
- une expression des actions conforme à leur formulation conceptuelle.
Dans la pratique, cette confrontation s'effectue simultanément à la description détaillée de chacune des tâches dont elle permet d'obtenir l'essentiel de leur spécification. Rappelons enfin que :
- La confrontation algorithmique n'intervient qu'en conception détaillée.
- Le processus de confrontation doit se faire à modèle conceptuel de données (ou organisationnel) « constant » ; à la suite d'une modification, on doit théoriquement revérifier tous les modèles externes précédemment validés.
- La confrontation détaillée peut remettre en cause indifféremment le modèle conceptuel ou organisationnel de données, les tâches et même le modèle organisationnel de traitements.
La confrontation détaillée est un préalable à la validation de la description détaillée des tâches.
II-H-6. Le maquettage, outil de confrontation▲
Le maquettage est d'abord une technique dont le rôle s'est développé pour présenter aux utilisateurs les interfaces détaillées du futur système et obtenir ainsi une meilleure validation. La maquette concrétise pour le gestionnaire ou l'utilisateur les spécifications externes de l'étude détaillée. Il peut donc vérifier directement si les solutions proposées sont conformes à ses besoins. Mais cela dépend du niveau de maquettage utilisé ; il ne faut pas confondre maquettage et prototypage.
La maquette est une représentation de la future application (ou seulement d'une partie) qui en possède la même apparence (ou proche). Elle facilite grandement la validation par les utilisateurs, des spécifications externes détaillées de l'interface (présentation et logique de dialogue), surtout dans son aspect ergonomique.
Le maquettage peut se présenter sous des degrés de sophistication variables :
- de simples descriptions graphiques d'écran avec une interaction minimale (maquette statique) ;
- des écrans interactifs comportant l'essentiel de la logique du dialogue ainsi que les enchaînements (maquette dynamique).
Le maquettage joue pleinement son rôle dans le processus de confrontation des données et des traitements lorsque sa spécification permet d'associer :
- les informations utilisées dans l'interface et les données modélisées, l'ensemble des données de l'interface correspond ainsi à une vue externe ;
- les règles de traitements mises en jeu et exprimées sur les données modélisées ;
- les actions exercées par la maquette sur les données mémorisées.
Un tel maquettage nécessite le recours à des outils adaptés. Même dans les cas les plus sophistiqués, la maquette ne peut être une application opérationnelle (ou une partie) utilisable même provisoirement par l'utilisateur. Elle doit rester un outil du concepteur pour représenter, illustrer et permettre de valider les spécifications de la future application.
Le prototype est une application, une partie d'application ou fonction particulière développée à titre expérimental. Il est destiné à vérifier la faisabilité d'une solution (ou d'un élément) dans des conditions d'utilisation les plus proches de la réalité (ou extrêmes). Le prototype peut porter sur l'évaluation d'un aspect fonctionnel, organisationnel ou technique. Le prototype, dans son champ d'expérience, comporte l'ensemble des fonctionnalités opérationnelles du futur système.
II-H-7. Conclusion▲
Dans le déroulement du cycle d'abstraction, nous avons jusqu'ici parcouru :
- la modélisation conceptuelle des traitements ;
- la modélisation conceptuelle des données ;
- la modélisation organisationnelle des données ;
- la modélisation organisationnelle des traitements ;
- la modélisation du cycle de vie des objets et des objets métiers ;
- la confrontation données / traitements.
Ces différents raisonnements permettent la conception du système d'information organisationnel (SIO) et constituent l'aspect métier. Nous avons pu constater que les notions utilisées n'impliquaient aucune connaissance informatique et que les problèmes abordés relevaient avant tout de la gestion du domaine : fonctionnement général, signification des informations, organisation des ressources.
Il importe donc qu'au sein de l'équipe de conception le rôle des utilisateurs gestionnaires soit prépondérant. Nous reviendrons sur ces rôles ultérieurement.
Le déroulement du cycle d'abstraction se poursuit par :
- la modélisation logique des données ;
- la modélisation logique des traitements ;
- la modélisation physique des données et des traitements.
Ces raisonnements permettent la conception du système d'information informatisé (SII) et constituent l'aspect informatique. Nous introduirons donc progressivement des notions techniques nécessaires à la résolution des problèmes abordés.