



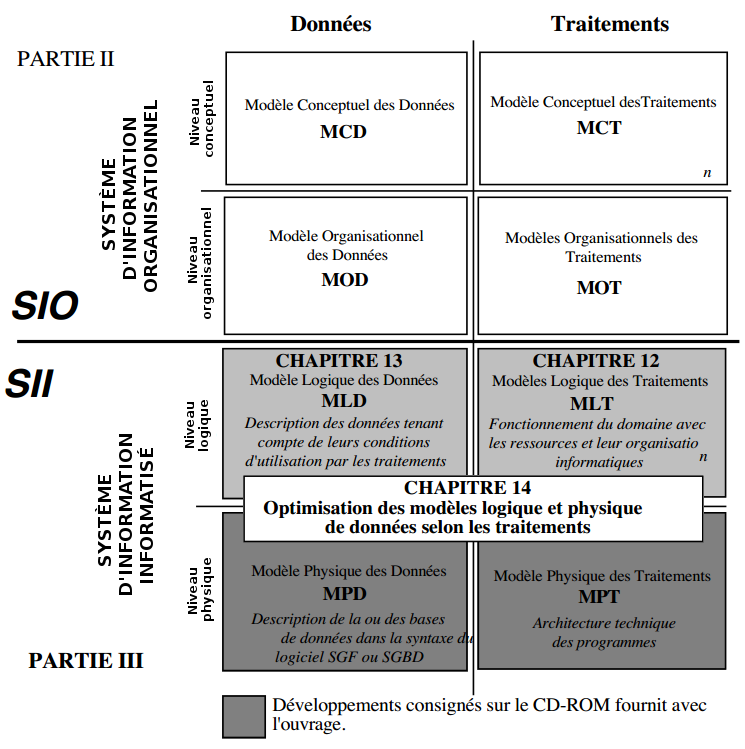
III. Partie 3 - Les raisonnements de la méthode Merise : conception du Système d'Information Informatisé (SII)▲
III-A. Préambule▲
La deuxième partie traitait de la conception du Système d'Information Organisationnel. Cette troisième partie est consacrée à l'étude du Système d'Information Informatisé (SII), plus précisément à l'articulation des modélisations et formalismes associés.
Cette partie précisera comment élaborer et exprimer les différents modèles, comment passer d'un niveau d'abstraction au suivant et transformer les différents modèles et enfin comment aborder toute optimisation :
- Chapitre 12 : modélisation logique des traitements.
- Chapitre 13 : modélisation logique des données.
- Chapitre 14 : optimisation des modèles logiques et physiques de données.
Comme pour la deuxième partie, la présentation est effectuée ici sans référence aux autres cycles.
Nous rappelons, encore une fois, qu'une telle démarche reste théorique, et n'a de justification que pédagogique.
Dans la pratique, comme nous l'avons vu à la fin de la partie précédente, le parcours du cycle d'abstraction devra toujours se situer par rapport à une étape du cycle de vie, en particulier l'étude préalable, étude détaillée ou étude technique.
C'est ce que nous traiterons en détail dans la quatrième partie de l'ouvrage.
III-B. Chapitre 12 Modélisation Logique des Traitements▲
III-B-1. Problématique de la modélisation logique des traitements (MLT)▲
La conception du système d'information organisationnel a conduit à l'élaboration des modèles conceptuels et organisationnels de traitements, MCT et MOT. Ces modèles ont permis de décrire le fonctionnement du SIO, en réponse aux stimuli en provenance de l'environnement du domaine d'activité étudié.
Le MCT a permis de décrire les fonctions majeures du domaine, sans référence aux ressources nécessaires pour assurer le fonctionnement ; on s'est concentré sur le quoi.
Le niveau d'abstraction suivant, appelé aux débuts de Merise « organisationnel - logique », se préoccupe du comment, c'est-à-dire des ressources (moyens techniques ou humains, espace, temps, données) et de leur mise en œuvre permettant d'assurer l'exécution des activités définies au niveau conceptuel.
Dix années de pratique ont révélé la nécessité de considérer deux perceptions et préoccupations différentes du comment, selon que l'on se situe du point de vue du gestionnaire (SIO) ou de l'informaticien (SII). Ainsi a progressivement émergé la distinction entre modèle organisationnel de traitements et modèle logique de traitements.
Le MOT se préoccupe d'une vision externe des moyens que l'entreprise va mettre en œuvre pour informatiser son système d'information. On s'intéressera à la répartition et à l'organisation des tâches entre l'homme et l'informatique, à la disponibilité des données. En résumé, le gestionnaire se pose la question : comment vais-je informatiser et organiser les activités de mon domaine ?
Le MLT se préoccupe d'une vision interne des moyens que l'informaticien va utiliser pour construire le logiciel correspondant aux activités informatisées définies dans le MOT. On parlera d'enchaînement de transactions, de découpage en modules, de répartition des données et traitements informatisés.
L'informaticien se pose la question : comment vais-je concevoir mon logiciel par rapport aux fonctions demandées ?
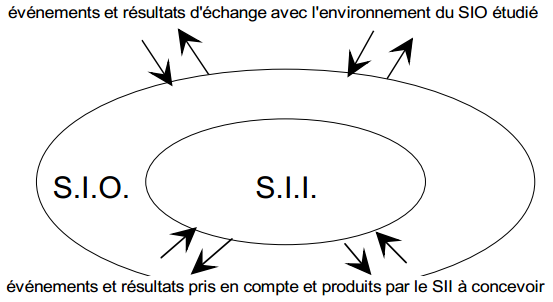
Le passage du système d'information organisationnel (SIO) au système d'information informatisé (SII), c'est le passage de solutions d'organisation à des solutions informatiques. Ces solutions informatiques spécifieront de façon fine et opératoire le SII.
Les modèles logiques de traitements (MLT) ont pour objectif de décrire le fonctionnement du SII en réponse aux stimuli des événements associés aux tâches informatisées précisées dans les MOT du SIO, comme l'illustre la figure 11.2
En résumé, la problématique de la modélisation logique des traitements, c'est comment informatiser les activités prescrites dans la modélisation organisationnelle des traitements (phases, tâches) compte tenu :
- des ressources et contraintes logiciel et matériel ;
- des principes généraux d'ergonomie.
Ces modèles logiques de traitements (MLT) doivent permettre la prise en compte de choix techniques liés soit à l'architecture, notamment la répartition des traitements et des données, soit au poste de travail lui-même. Pour l'architecture technique, c'est la mise en œuvre d'un système de gestion de bases de données (SGBD), de bases de données réparties, d'architectures client-serveur… Pour le poste de travail, c'est d'une façon plus générale la prise en compte de nouvelles tendances du génie logiciel, permettant une meilleure ergonomie du poste de travail en mettant à profit la richesse de nouvelles interfaces homme/machine ; c'est concevoir des applications respectant la séparation entre ces interfaces utilisateur et le noyau de l'application ; c'est la conception et la programmation par objets…
Ces MLT doivent spécifier avec rigueur et en détail le contenu des traitements informatisés associés à chaque tâche organisationnelle à informatiser afin de construire une ou plusieurs solutions informatiques.
La spécification des modèles logiques de traitements est fortement liée à l'architecture adoptée et surtout aux outils logiciels retenus pour la réalisation du SII. Ainsi sont apparus sur le marché, autour des systèmes de gestion de bases de données principalement relationnels, des environnements ou ateliers de quatrième génération permettant un développement rapide d'applications. Ces ateliers facilitent ce développement d'applications en proposant des objets logiciels de plus en plus complexes, véritables boîtes à outils.
L'usage de ces environnements de développement de quatrième génération conduira à la formulation de MLT d'un très haut niveau de spécification et dans un formalisme approprié aux fonctionnalités de l'environnement retenu. Si le langage SQL est maintenant une norme à laquelle la quasi-totalité des SGBD relationnels se réfèrent, les environnements de développement de quatrième génération proposés par ces SGBD ne sont pas encore normalisés. Tout au plus peut-on constater une certaine convergence au niveau de la définition des objets complexes sur lesquels ces environnements s'appuient. Cet état de fait pose d'ailleurs des problèmes de portabilité des applications d'un environnement à l'autre.
Citons pour exemple les ateliers de développement (AGL - ateliers de génie logiciel) proposés autour de SGBD relationnels du marché. La mise en œuvre de tels ateliers conduit généralement à spécifier des MLT dans un formalisme de type graphe, enchaînant des objets complexes parfois appelés «frames». Ces frames présentent un aspect statique, les «formes», sortes d'écrans présentant des données, et un aspect dynamique ou comportemental gérant des menus en fonction d'événements, permettant d'activer des procédures sur la base de données, assurant l'enchaînement de frames entre eux.
Aussi, il est assez difficile de proposer un formalisme universel pour l'élaboration de MLT. Néanmoins, un certain nombre de tendances du génie logiciel s'affirment, par exemple le multifenêtrage, la séparation dans un traitement de la partie dialogue (interface homme/machine, machine/machine…) de la partie purement applicative. Signalons les travaux menés au sein de SEMA Group sur cette modélisation logique des traitements [Panet, Letouche, Peugeot 91] [Panet, Letouche 94]. La prise en compte de ces tendances nous conduit à proposer le formalisme développé dans le paragraphe suivant.
III-B-2. Formalisme de modélisation des traitements au niveau logique▲
Comme pour l'expression des modèles organisationnels de traitements, le formalisme proposé pour l'expression de modèles logiques de traitements est fondé sur le formalisme général de modélisation des traitements de Merise. Il s'agit d'adapter les concepts types du formalisme général aux préoccupations de ce niveau logique.
Pour décrire le niveau logique, le formalisme des traitements utilise les concepts suivants :
- la machine logique ;
- l'événement/résultat - message ;
- l'état ;
- l'unité logique de traitements (ULT) ;
- la procédure logique.
III-B-2-a. La machine logique▲
Une machine logique type, ou machine logique, est définie comme un ensemble de ressources informatiques (matériel et logiciel) capables d'exécuter des traitements informatiques de façon autonome.
Bien que confondues dans la grande majorité des cas, il convient parfois de faire la distinction entre machine logique et machine physique. Une machine physique est un ensemble de matériels permettant d'assurer les fonctions de base de l'informatique (exécution de logiciel, mémorisation, entrées/sorties).
Ainsi une machine logique peut être :
-
équivalente à une machine physique :
- micro autonome ou en réseau,
- serveur,
- mainframe ou mini avec terminaux passifs ;
-
composée de plusieurs machines physiques :
- mini et micro en émulation terminal passif,
- mainframe et machine base de données ;
- une partie de machine physique : machine virtuelle sur un mainframe.
Précisons que l'architecture courante client / serveur est constituée de deux machines logiques basées sur deux machines physiques.
Une machine logique type est décrite par ses caractéristiques techniques : type, puissance, capacité…
Une machine logique type peut se matérialiser par plusieurs occurrences sur le terrain qui ont, par définition, le même comportement. Par exemple, la machine logique type micro client est en soixante exemplaires.
À l'instar des postes du modèle organisationnel de traitements, les machines logiques permettent d'exprimer la répartition des traitements informatisés. La représentation graphique des machines logiques reprend donc celle des postes, à savoir des colonnes dans lesquelles sont représentées les unités logiques de traitement exécutées par la machine logique.
Remarque : la représentation graphique des machines logiques peut être optionnelle dans les cas suivants :
- une seule machine logique ;
- répartition des traitements par nature d'ULT correspondant à des machines logiques dédiées (figure 12.1) ; exemple, d'une architecture client / serveur où les ULT d'accès aux données seraient toutes réalisées sur le serveur de données et les ULT de présentation, de dialogue et de calcul seraient toutes réalisées sur la machine cliente (voir MLT répartis).
III-B-2-b. Le site▲
Le site est le lieu où sont physiquement installées les machines physiques, support des machines logiques. Dans la modélisation logique des traitements, la prise en compte des sites n'interviendra qu'à travers la répartition des machines logiques.
Par exemple, dans le cas d'une machine logique constituée d'un mainframe et de terminaux répartis sur tout le territoire, le site sera la localisation du mainframe.
III-B-2-c. L'événement/résultat-message▲
Dans le formalisme général de modélisation des traitements proposé par la méthode Merise, événements et résultats représentent l'échange de stimuli et de réponses par rapport au système d'information. Cependant, la nature des événements et résultats est différente entre les niveaux conceptuel et organisationnel (SIO), et le niveau logique (SII). Pour le système d'information organisationnel (SIO), événements et résultats traduisent généralement les échanges du domaine avec son environnement ou entre les postes. Pour le système d'information informatisé (SII), événements et résultats expriment les échanges entre le SIO (c'est-à-dire les utilisateurs) et le SII (figure 12.2).
En conséquence, bien que reconduisant la symbolisation graphique précédemment utilisée, les événements et résultats du niveau logique pourront représenter :
- des apports ou productions d'informations entre le SIO et le SII, où l'on retrouvera certains événements ou résultats du SIO ;
- des échanges entre des machines logiques ou des unités logiques de traitements ;
- le lancement ou la fin des traitements informatisés déclenchés à l'initiative de l'utilisateur dans le cadre de ses tâches ; on utilise ainsi fréquemment l'événement « début procédure x » et le résultat « fin procédure x ».
Remarque : dans la modélisation logique des traitements, les événements et résultats n'ont pas d'acteurs émetteurs ou destinataires explicitement représentés. En fait, ce rôle d'acteur est joué par la ressource humaine impliquée dans les tâches interactives ; les tâches automatisées étant généralement déclenchées par des événements temporels ou décisionnels qui n'ont déjà pas d'acteur formalisé au niveau organisationnel (implicitement le système de pilotage).
III-B-2-d. L'état▲
La modélisation des états reste identique à celle utilisée aux niveaux conceptuel et organisationnel. Ils expriment des conditions préalables ou des résultats conditionnels d'une unité logique de traitement.
Dans la modélisation logique des traitements, il existe deux tendances pour l'expression des états :
- Certains choisissent de ne pas représenter les états dans les modèles. Ils considèrent que, les états étant mémorisés dans les données, la prise en compte des états préalables ou résultants relève de règles de traitement faisant partie intégrante de l'unité logique et qui sont associées à des actions sur le sous schéma de données (en lecture ou mise à jour). Ils argumentent que, lors de la réalisation, la gestion des états sera incluse dans la programmation associée à l'unité logique.
- D'autres optent pour une représentation explicite des états sur les modèles. Ils avancent qu'en particulier l'expression des états préalables permet de mieux formaliser la dynamique potentielle des enchaînements entre différentes ULT. Ils mettent en avant la possibilité ultérieure, dans les environnements orientés objet, de gérer les enchaînements extérieurement au noyau applicatif (figure 12.3).
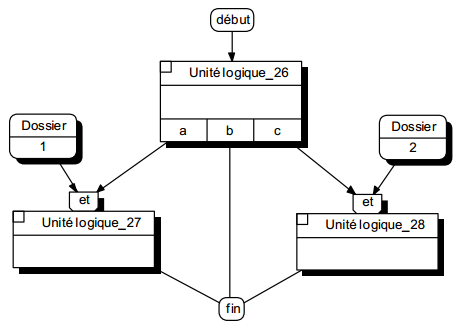 |
|
Dans l'ULT 26 le passage vers l'ULT 27 ne sera disponible que si le dossier est à 1 etc. |
III-B-2-e. L'unité logique de traitement▲
L'unité logique de traitement type, ou unité logique (ULT), modélise un ensemble de traitements informatiques perçus comme homogènes en termes de finalités.
L'unité logique de traitement se définit également par rapport à la cohérence des données du SII. Avant son démarrage, les données doivent être cohérentes (c'est-à-dire respecter l'ensemble des contraintes définies dans la base) ; durant son déroulement, les différentes actions sur les données envisagées peuvent provisoirement enfreindre cette cohérence ; à l'issue de son exécution, quelles que soient les conditions de sortie modélisées, l'ensemble des données mémorisées doivent retrouver une cohérence. Dans le cas où une ULT est interrompue ou suspendue, son contexte doit être conservé. Notons que cette notion de cohérence prépare les préoccupations de mécanismes de mises à jour concurrentielles et de verrouillages (COMMIT, Logical Unit of Work dans les SGBD relationnels).
Ce respect de la cohérence et l'homogénéité du traitement envisagé vont guider le concepteur dans le découpage en ULT.
Une unité logique de traitement peut modéliser par exemple :
- une transaction dans un système transactionnel classique ;
- une boite de dialogue ;
- une édition ;
- un module dans une chaîne batch.
La symbolisation graphique de l'ULT reprend celle du formalisme général des traitements de Merise déjà utilisée pour l'opération et la tâche avec les concepts secondaires associés : synchronisation, description et conditions d'émission.
III-B-2-e-i. Description et composition d'une unité logique de traitement▲
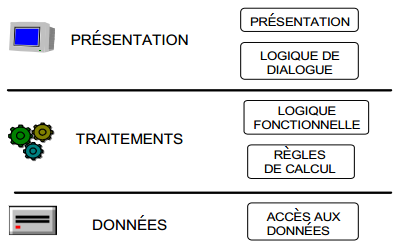
L'ULT est décrite par l'ensemble des traitements informatiques homogènes à réaliser qui peuvent être décomposés selon leur nature :
- interface ;
- traitements ;
- données.
Ces trois niveaux, aujourd'hui communément admis et particulièrement utilisés dans la répartition, peuvent également se décomposer en fonctions suivantes :
- présentation externe des données utilisées ;
- règles de gestion et de contrôle associées à la présentation ou logique de dialogue ;
- algorithmique générale de l'ULT ou logique fonctionnelle ;
- règles de calcul ou procédures à appliquer ;
- accès aux données mémorisées à travers un sous-schéma de données ;
- enchaînements conditionnels vers d'autres ULT ou résultats produits représentés par les conditions de sortie.
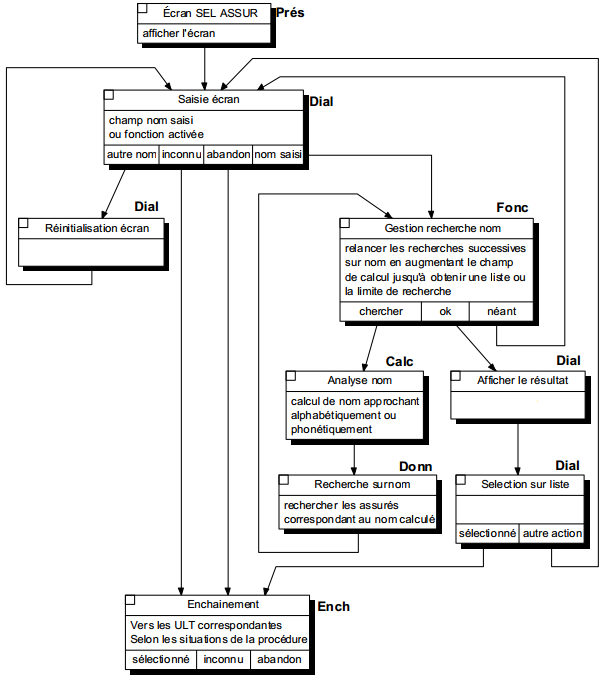
La figure 12.4 illustre l'articulation de ces différents composants :
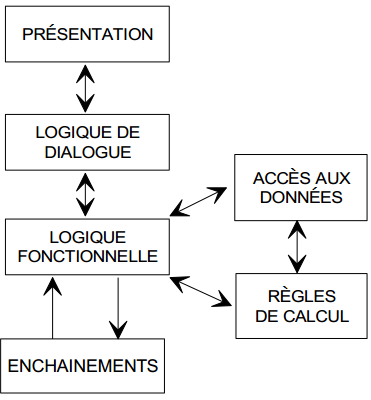
Suivant le degré de détail souhaité, le concepteur peut représenter une ULT soit au sein d'une procédure organisationnelle (figure 12.7) avec une description sommaire des traitements à réaliser, mais en privilégiant l'enchaînement, soit en « gros plan » avec l'expression détaillée de la présentation, de la logique de dialogue, de la logique fonctionnelle, des règles, du sous-schéma de données et des enchaînements. Dans ce dernier cas, la représentation graphique n'a certes qu'un intérêt limité et de nombreux concepteurs en font d'ailleurs l'économie ; il ne faut pas pour autant hâtivement en déduire que la modélisation logique des traitements n'a que peu d'intérêt dans la méthode Merise.
Remarque : toutes les ULT ne comprennent pas systématiquement tous les composants sus-cités. Dans certains cas (décomposition, répartition, nature de l'ULT), certains composants peuvent être absents.
III-B-2-f. La présentation▲
La présentation, associée à sa logique de dialogue, constitue l'interface homme - machine. Cette composante de l'unité logique de traitement est un aspect très important de la conception d'un système d'information informatisé. Elle est le point de contact privilégié entre l'utilisateur et la partie informatisée de son système d'information ; aussi son ergonomie, parfois négligée dans le passé, doit être particulièrement étudiée. Un paragraphe spécifique aborde plus loin les différents aspects de l'ergonomie des interfaces homme - machine.
La présentation est la partie externe visible (voire auditive) de l'interface. Selon les types d'environnement, elle se concrétise sous la forme :
- d'un écran utilisant des objets alphanumériques activables par l'intermédiaire d'un clavier ;
- d'une fenêtre utilisant des objets alphanumériques ou graphiques activables par l'intermédiaire d'un clavier ou d'une souris ;
- d'une édition sous forme d'état ou de formulaire.
La formalisation de la présentation s'effectue par un dessin d'écran, de fenêtre ou d'édition, auquel est joint un descriptif précisant le contenu et les caractéristiques de chaque objet.
Dans l'élaboration de la présentation, le concepteur doit également tenir compte :
- des normes et standards de la profession (AFNOR, CUA, OSF) ;
- des éventuels guides de style spécifique à son entreprise ;
- des possibilités et contraintes liées aux outils de réalisation.
La validation d'une présentation par les utilisateurs peut certes être réalisée sur papier. Toutefois, l'aspect démonstratif d'une maquette est un atout indéniable et est aujourd'hui la solution recommandée.
III-B-2-g. La logique de dialogue▲
La logique de dialogue comprend l'ensemble des règles de gestion et de contrôle associées à la présentation. En sont exclus les algorithmes et les accès aux données.
Les règles de gestion de l'interface expriment :
- des actions sur le clavier ;
- des actions sur des objets graphiques ;
- la dynamique de la présentation.
Les règles de contrôle de l'interface correspondent à :
- des contrôles sur les données de la présentation (sans faire d'accès aux données de la base) ;
- des calculs élémentaires sur les données de la présentation.
La formalisation de la logique de dialogue s'effectue sous une forme textuelle (formulaire ad hoc ou pseudocode proche d'un L4G).
Le maquettage dynamique (voir chapitre 18Chapitre 18 Outils pour la mise en œuvre de Merise de la partie 4) permet une validation simultanée de la présentation et du dialogue.
III-B-2-h. La logique fonctionnelle▲
La logique fonctionnelle représente l'algorithmique générale de l'ensemble des traitements à effectuer et constitue la « colonne vertébrale » de l'ULT. Son rôle central de coordination est illustré par sa position dans l'articulation des différentes fonctionnalités (figure 12.4).
Outre la gestion de l'enchaînement des traitements au sein de l'ULT, la logique fonctionnelle assure les échanges :
- avec la partie logique de dialogue (appel, transfert des données) ;
- avec la partie accès aux données (demande, récupération) ;
- avec la partie règles de calcul (lancement, récupération) ;
- avec la partie enchaînements (appel d'autres ULT, retour d'ULT appelée).
La formalisation de la logique fonctionnelle peut s'effectuer sous une forme graphique (type organigramme ou MLT analytique décomposé) ou sous une forme textuelle (langage naturel ou pseudocode proche d'un L4G).
III-B-2-i. Les règles de calcul▲
On reconduit, au niveau de l'ULT, la notion de règle de calcul telle qu'elle a déjà été formalisée dans la modélisation organisationnelle des traitements. Précisons que les règles de contrôle et de calcul élémentaires sont déjà exprimées dans la partie logique de dialogue. En conséquence, ne subsistent dans cette partie que les règles :
- présentant une algorithmique suffisante ;
- ne nécessitant pas d'interaction directe avec la présentation ;
- échangeant éventuellement des données avec la partie sous-schéma.
Ces règles de traitement ou procédures s'expriment par un algorithme, ensemble d'expressions arithmétiques et/ou logiques enchaînées suivant une structure de calcul.
Ces règles de traitement comportent :
- des variables représentées ici par des informations provenant du dialogue ou du sous-schéma de données ;
- des constantes dont les valeurs sont propres au contexte ;
- des opérateurs arithmétiques ou logiques ;
- des règles de traitements, permettant ainsi une construction arborescente ;
- des règles de traitement avec possibilité de réutilisation de règles élémentaires.
La méthode Merise ne propose pas à ce jour de formalisme propre pour la description des algorithmes. Nous conseillons d'utiliser les concepts et règles de la programmation structurée qui privilégie les trois structures de contrôle suivantes :
- le bloc ;
- l'alternative ;
- la répétitive.
Le contenu détaillé de la règle peut être exprimé sous la forme de langage structuré (naturel ou pseudocode proche d'un L4G).
Les règles spécifiques définies dans cette partie peuvent être « cataloguées » comme le proposent aujourd'hui les environnements client / serveur de 2e génération.
III-B-2-j. Le sous-schéma logique de données▲
L'accès aux données comprend :
- le sous-schéma logique de données ;
- les actions effectuées sur les données mémorisées ;
- les contrôles de cohérence et d'intégrité des données.
Un sous-schéma logique de données (voir figure 12.5) est un sous-ensemble de tables et d'attributs défini sur le modèle logique de données (MLD), et associé à une unité logique. Cette ULT effectue des actions (mise à jour ou lecture) sur les occurrences de ces tables, tout en respectant la cohérence et l'intégrité de la base. Le sous-schéma logique est également appelé vue logique.
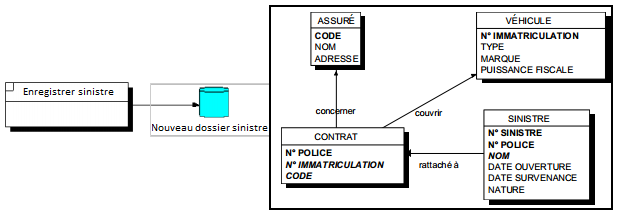
Sur le diagramme d'une procédure logique, le sous-schéma logique peut être représenté graphiquement par une icône associée à son nom (voir figure 12.5). Dans une description détaillée, on exprime le sous-schéma logique en associant le schéma de données à un tableau récapitulatif des actions types envisagées (voir figure 12.6).
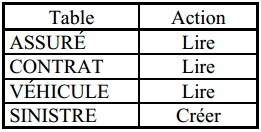
La cohérence et l'intégrité des données sont assurées, dans une proportion variable suivant les technologies utilisées :
- par le système de gestion de base de données ;
- par des règles spécifiques exprimées dans la partie accès aux données.
Remarque : bien qu'il soit théoriquement normal d'associer ULT et sous-schéma logique, de nombreux praticiens souhaitent conserver l'expression du sous-schéma dans le formalisme entité - relation, du moins dans l'étape d'étude détaillée au contact avec l'utilisateur.
III-B-2-k. Les enchaînements▲
Ils assurent les liaisons entre les différentes ULT d'un MLT. Ils représentent :
- les origines des appels de l'ULT (événements logiques) ;
- les liaisons conditionnelles vers d'autres ULT (résultats logiques).
Ces enchaînements peuvent s'appuyer soit sur les procédures logiques, soit sur la structure logique de l'application (voir ci-après).
L'enchaînement prend en charge le transfert d'informations éventuellement nécessaire entre les ULT. Ce rôle deviendra d'ailleurs important dans le cas de répartition des traitements qui conduira à une segmentation et une spécialisation des ULT.
Remarque : il ne faut pas confondre l'enchaînement des différents traitements au sein d'une ULT exprimé dans la logique fonctionnelle, et l'enchaînement entre des ULT distinctes exprimé ici.
III-B-2-l. La procédure logique▲
C'est un enchaînement d'ULT réalisant l'informatisation d'une tâche ou phase du modèle organisationnel.
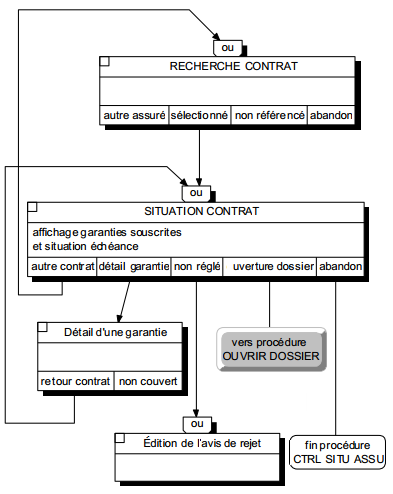
Le début de la procédure représente l'appel par l'utilisateur du menu ou de la fonction de l'application correspondant à la tâche. La fin de la procédure correspond au retour au menu de l'application permettant le lancement d'une autre procédure. Au sein de la procédure, les ULT disponibles et leurs enchaînements correspondent à la résolution de l'activité organisationnelle associée. La figure 12.7 illustre la procédure logique associée à la tâche Contrôle situation assuré présentée dans la procédure organisationnelle figure 8.9.
Remarque : au niveau logique, il convient de distinguer deux présentations d'enchaînement d'ULT :
- l'enchaînement désigné par procédure logique qui représente les traitements informatisés nécessaires à l'exécution d'une tâche ou phase organisationnelle ;
- l'ensemble des enchaînements possibles entre les ULT correspondant à la structure logique de l'application qui est une représentation descriptive informatique.
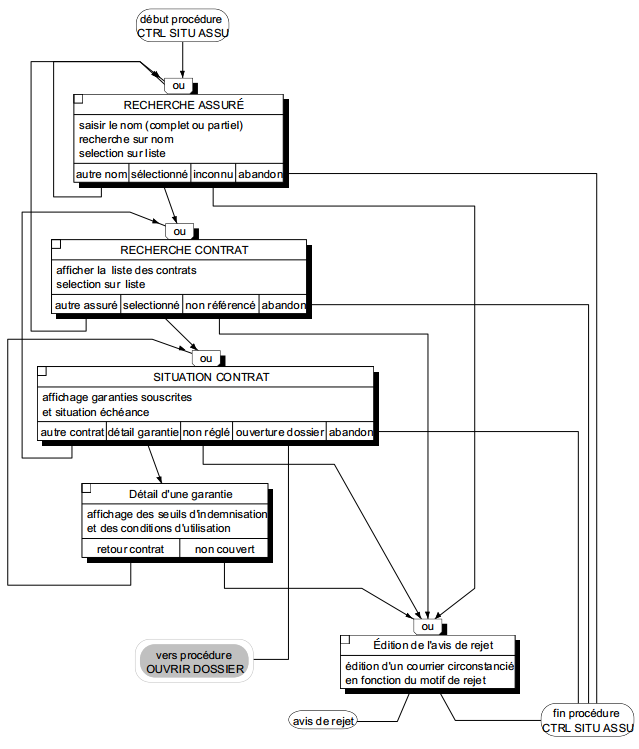
La présentation en procédure logique n'a pratiquement d'intérêt que dans le cas d'enchaînements suffisamment complexes d'ULT. Dans le cas où la procédure se réduit à une ou deux ULT, sa formalisation est superflue ; on se satisfait alors de la description du contenu de chaque ULT (présentation, dialogue, règles, actions sur les données, enchaînements). Cette simplification de la présentation des procédures logiques est particulièrement constatée en cas d'utilisation de maquettage dynamique.
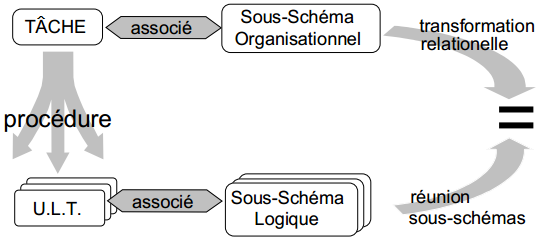
III-B-2-l-i. Cohérence sous-schéma organisationnel et sous-schémas logiques de données▲
Dans le cadre d'une procédure logique, associée à une tâche organisationnelle, il est nécessaire de contrôler la cohérence entre le sous-schéma de données organisationnel de la tâche et les sous-schémas logiques des ULT constituant la procédure logique.
On vérifie que la réunion des sous-schémas logiques des ULT de la procédure logique issue de la tâche est équivalente à la transformation logique du sous-schéma conceptuel/organisationnel de données associé à la tâche.
III-B-3. Conception des modèles logiques de traitements▲
Dans le processus de conception du SII, la méthode Merise présente une différence importante d'approche entre les données et les traitements. L'élaboration d'un modèle logique de données sera obtenue de façon algorithmique à partir de la modélisation conceptuelle et organisationnelle des données (voir chapitre 13Chapitre 13 Modélisation Logique des Données). Par contre, la construction d'un modèle logique de traitements exige dans tous les cas une réflexion, une création, une invention ; elle ne peut pas être directement et automatiquement déduite des modélisations effectuées dans le SIO ; tout au plus la modélisation organisationnelle des traitements pourra servir au concepteur de cadre contextuel de réflexion.
Pour élaborer des modèles logiques de traitements, nous proposons d'abord trois approches qui s'avèrent complémentaires dans une mise en œuvre pratique et possèdent chacune des avantages et des inconvénients :
- la décomposition des tâches du MOT ;
- la recherche de réutilisation d'ULT ;
- la conception d'ULT autour des données.
Par ailleurs, l'état de l'art des années 90 en génie logiciel propose de nouvelles architectures logiques d'application permettant une approche plus modulaire de la modélisation logique des traitements, facilitant ainsi leur répartition en fonction des technologies disponibles.
III-B-3-a. Décomposition des tâches organisationnelles▲
Le concepteur élabore les procédures logiques à partir des préoccupations exprimées dans les phases ou tâches informatisées du MOT ; il est essentiellement guidé par la description des tâches. Pour chaque tâche, il construit les enchaînements et contenus des ULT les plus appropriés à la tâche étudiée.
Dans cette approche, la procédure logique apparaît comme une décomposition de la tâche ; on reconduit ainsi globalement le processus utilisé pour passer du MCT au MOT.
On peut supposer que la procédure logique présentée à la figure 12.7 a été imaginée suivant cette approche à partir de la tâche correspondante présentée à la figure 8.9.
III-B-3-a-i. Avantages▲
On peut concevoir des ULT très proches des activités formulées dans la description de la tâche et bien adaptées aux conditions d'utilisation exprimées dans la procédure organisationnelle (tâches amont et aval, environnement du poste).
III-B-3-a-ii. Inconvénients▲
L'approche n'est praticable que dans des situations où sont établies des procédures organisationnelles, par exemple dans des systèmes d'information de production (voir chapitre 4 « Typologie des systèmes d'informationTypologie des systèmes d'information »).
Les ULT ainsi conçues peuvent également être trop spécifiques à une organisation et n'offrir que peu de souplesse organisationnelle.
On risque enfin une démultiplication d'ULT similaires qui compliquera ultérieurement la réalisation.
III-B-3-b. Réutilisation des ULT▲
Cette approche s'inspire de principes préconisés en génie logiciel visant à limiter la multiplication de fonctions applicatives similaires, voire identiques, afin d'améliorer l'économie du développement et la maintenance.
Dans cette approche, d'une part, le concepteur recherchera dans le MOT des tâches dont la description est similaire ou proche ; il pourra ainsi concevoir des ULT utilisables en commun par ces différentes tâches.
D'autre part, lors de la construction du MLT, éventuellement par procédure logique, il s'efforcera de réutiliser des ULT déjà existantes quitte à procéder éventuellement à leur amendement. Cette « banque d'ULT » s'enrichira progressivement au sein du même projet, voire au-delà d'un projet spécifique.
III-B-3-b-i. Avantages▲
Une diminution du nombre d'ULT spécifiées est normalement espérée, allégeant les charges de réalisation et de maintenance ultérieures.
III-B-3-b-ii. Inconvénients▲
La mise en commun de préoccupations certes proches, mais parfois légèrement différentes par leur contexte peut conduire à une moindre adaptation de l'ULT à la tâche associée.
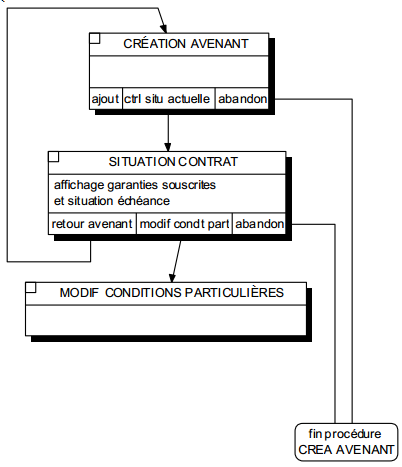
L'implication d'une même ULT dans différentes procédures logiques pose le problème illustré par la figure 12.9.
 |
 |
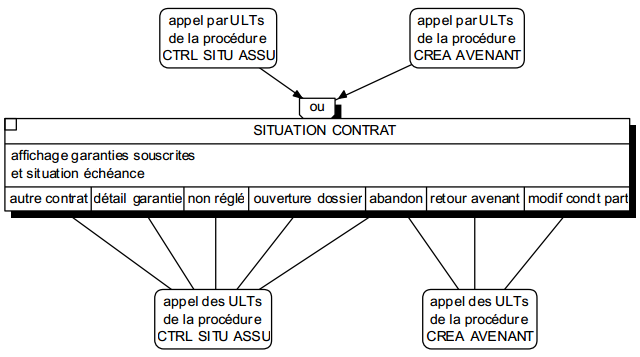 |
L'ULT Situation contrat est partagé par la procédure Contrôle situation assuré (présentée intégralement figure 12.7) et dans la procédure Avenant. Bien qu'ayant un contenu identique, cette ULT est soumise à des conditions contextuelles d'appel et d'enchaînement différentes. En fait, il faut définir une ULT Situation contrat de « fusion » avec l'ensemble des appels et enchaînements possibles.
Dans la pratique, pour pouvoir réaliser cette réutilisation d'ULT multiprocédures, les différences contextuelles entre les ULT doivent être faibles.
Nous suggérons les critères suivants :
- présentation identique ;
- même sous-schéma avec éventuellement des actions différentes ;
- règles partagées identiques, quelques règles spécifiques ;
- appels et enchaînements différents.
La trop grande multiplicité de contexte d'utilisation d'une même ULT peut cependant compliquer ultérieurement le travail du réalisateur.
III-B-3-c. Conception des ULT autour des données▲
Cette approche cherche à être la plus indépendante possible du contexte d'organisation en s'appuyant sur des ensembles de données perçus comme stables par l'utilisateur, référant à des objets utilisés dans ses activités courantes.
Ces objets utilisateurs correspondent généralement au concept d'entité externe (voir Chapitre 11 Confrontation données / traitementsChapitre 11 Confrontation données / traitements), c'est-à-dire une entité jouant le rôle de pivot liée à des entités par des relations binaires fonctionnelles. Des objets utilisateurs complexes constituant de véritables modèles externes, peuvent se composer d'une entité externe principale (désignant l'objet) et d'une entité externe dépendante formant une structure de composition. Cette notion d'objet utilisateur, également évoquée par dans Merise/2 [Panet, Letouche 94], s'apparente aussi à celle d' « objet naturel » [Bres 91].
Dans cette approche, le concepteur recherchera, dans le MCD ou le MOD, des entités dont l'appellation évoque des notions principales du domaine autour desquelles il construira ces modèles externes. Il associera à ce sous-schéma une ULT qui permettra d'effectuer les actions de base (création, modification, suppression, consultation).
La figure 12.10 présente quelques modèles externes correspondant à des objets utilisateurs définissables a priori sur le modèle conceptuel de données du cas Assurance (figure 10.3).
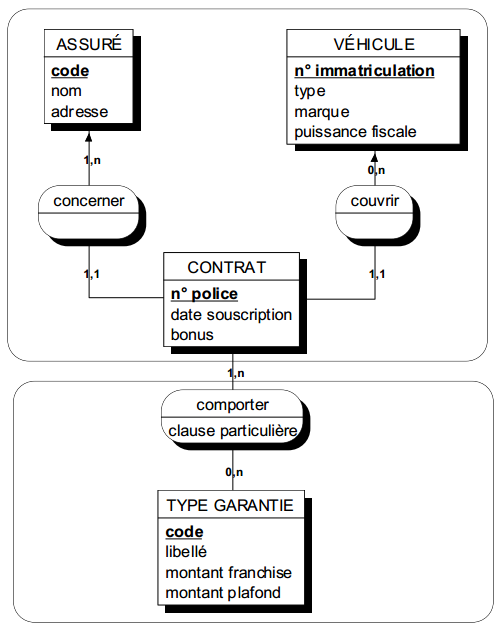 |
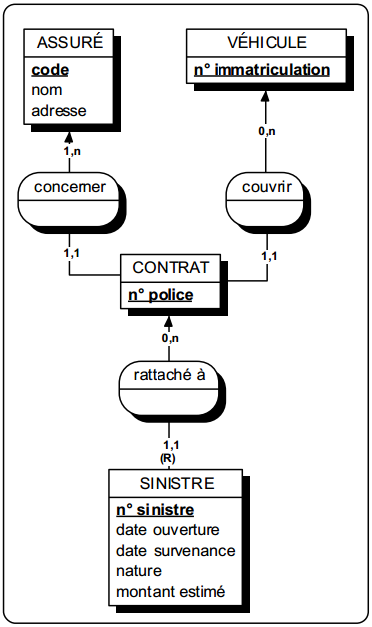 |
III-B-3-c-i. Avantages▲
Ces ULT peuvent servir d'éléments de base pour constituer une approche par réutilisation.
Les ULT ainsi définies peuvent être directement implémentées dans des environnements graphiques en dehors d'approche procédurale.
III-B-3-c-ii. Inconvénients▲
Cette approche laisse évidemment la construction des procédures logiques à l'initiative des utilisateurs qui doivent maîtriser les enchaînements adéquats au problème à résoudre.
III-B-4. Modularité du MLT▲
III-B-4-a. ULT et architecture logique d'application▲
Nous avons vu en introduction que les modèles logiques de traitements devaient pouvoir prendre en compte les nouvelles tendances informatiques tant en matière de répartition des données et des traitements qu'en matière d'interface homme/machine liée au poste de travail.
Il s'agit en conséquence de pouvoir concevoir des applications respectant la séparation de ces interfaces utilisatrices du noyau de l'application, afin d'avoir une indépendance entre le dialogue interactif (présentation, interaction) et le noyau de l'application. Cette indépendance est nécessaire pour :
- Développer plusieurs interfaces différentes pour un même noyau applicatif, permettant alors de travailler par exemple sur un parc matériel hétérogène au niveau des postes de travail.
- Maintenir le noyau applicatif sans avoir à toucher à l'interface et inversement.
L'approche que nous préconisons s'appuie sur un modèle d'architecture logique d'application proposé dans Merise/2 [Panet, Letouche 94] et repris de SAA d'IBM, qui distingue trois modules de base :
- l'interface homme - machine ;
- le noyau applicatif ;
- le guidage fonctionnel.
Dans une architecture classique transactionnelle (type CICS, TDS…), ces modules recouvrent les fonctionnalités de base de l'ULT précédemment décrites comme le présente la figure 12.11. Une architecture plus récente liée aux environnements graphiques est représentée par la figure 12.12.
La répartition des traitements entre plusieurs machines logiques permettra par ailleurs (voir MLT répartis) de nouvelles variantes d'architecture logique d'application.
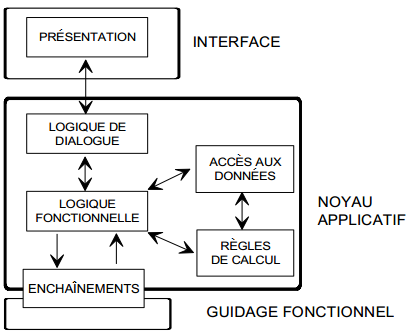
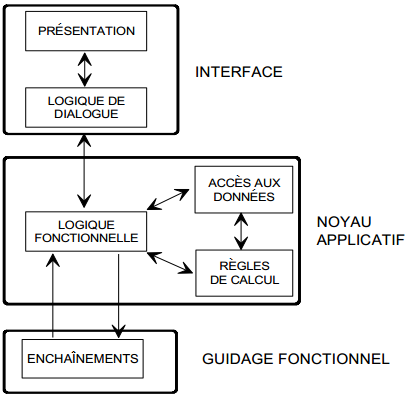
III-B-4-b. Décomposition des ULT par nature▲
Nous avons vu d'une part que la description d'une ULT pouvait s'analyser selon différents composants de natures différentes (voir figure 12.4), et d'autre part que l'architecture logique d'application se décomposait en trois modules. La réalisation de ces modules et de leurs communications, ainsi que la spécification détaillée de l'ULT, nécessite parfois de pouvoir formaliser plus finement la logique interne de l'ULT.
Ce détail est obtenu par la décomposition de l'ULT en ULT plus fines. Nous retrouvons ici le principe de décomposition hiérarchique (refinement) présenté dans la première partie (voir chapitre 6 « Modularité des modèles conceptuels de traitementsModularité des modèles conceptuels de traitements »), également appelé MLT analytique dans Merise/2.
Dans cette décomposition, les ULT élémentaires doivent respecter les règles suivantes :
- unité de nature (présentation, dialogue, logique fonctionnelle, accès aux données, règles, enchaînement) ;
- unité de machine logique en cas de répartition.
La formalisation est celle d'un enchaînement d'ULT, similaire à celui de la procédure logique où l'on précise la nature de chaque ULT élémentaire. Ce diagramme enchaînement des ULT élémentaires constitue déjà en lui-même une partie de la logique fonctionnelle de l'ULT.
Les ULT élémentaires sont éventuellement réutilisables et peuvent ainsi intervenir dans la composition de plusieurs ULT.
Ces ULT élémentaires sont également appelées par d'autres auteurs primitives (de dialogue, d'accès aux données, de calcul).
La figure 12.13 illustre la décomposition de l'ULT Recherche assuré présente dans la procédure logique Contrôle situation assuré (figure 12.7) ; la nature de chaque ULT élémentaire est indiquée en abrégé.
Ultérieurement, en fonction du type d'architecture logique d'application retenu, le concepteur rassemblera dans les différents modules, les ULT élémentaires selon leur nature. Ainsi, sur la base d'une architecture type présentée à la figure 12.12, le module d'interface comporterait les ULT élémentaires de présentation et de dialogue ; les autres ULT constituant le noyau applicatif. Les liens entre des ULT élémentaires appartenant à des modules différents se traduiraient par des échanges entre modules. On constatera qu'avec une architecture classique, l'ensemble des ULT (hormis la présentation) se retrouveraient dans le noyau applicatif.
Remarque : La décomposition d'une ULT est en pratique réservée à la formalisation
- d'ULT à contenu assez complexe ;
- d'architecture logique d'application nécessitant une distinction des modules ;
- de répartition liée à des traitements coopératifs.
III-B-5. Modèles logiques de traitements répartis▲
Nous avons vu dans la deuxième partie, relative à l'étude du SIO (système d'information organisationnel), un premier type de répartition des traitements exprimée dans les MOT. Cette répartition portant sur les tâches s'effectuait tout d'abord en répartissant les tâches dans des postes de travail, et ensuite en définissant pour chaque tâche un type d'automatisation, d'informatisation (voir début du chapitre 8Chapitre 8 Modélisation organisationnelle des traitements).
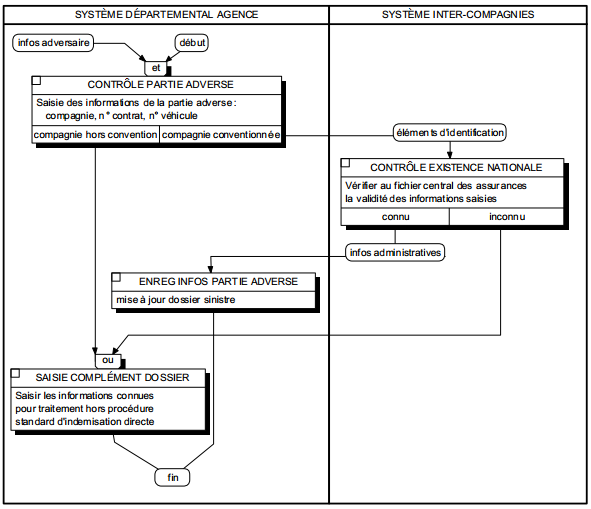
La répartition logique des traitements (voir figure 12.14) concerne le SII (système d'information informatisé) et porte sur les unités logiques de traitements associées aux tâches informatisées du MOT. Cette répartition logique est rendue possible par les possibilités de communications de plus en plus faciles entre matériels et logiciels hétérogènes, selon des protocoles normalisés.
Ces possibilités de communications font que des solutions de répartition des traitements permettent par exemple de mettre en commun des informations sur des serveurs dédiés, d'accéder à partir d'une machine à des données réparties ou de mettre à profit l'ergonomie des interfaces graphiques disponibles sur les environnements micro.
III-B-5-a. Démarche de répartition▲
Pour construire un MLT réparti, nous suggérons d'adopter la démarche suivante.
III-B-5-a-i. Élaborer un MLT non réparti▲
La construction de ce premier modèle s'effectue sans tenir compte de la future répartition ; elle est avant tout tournée vers l'utilisateur, d'une part dans la définition de l'interface et des fonctions à assurer, d'autre part dans la réponse donnée aux tâches organisationnelles.
Cette modélisation est commune à tout projet. Elle reprend tous les principes exposés dans les paragraphes précédents, avec en particulier l'analyse du contenu de chaque ULT selon ses différentes fonctionnalités. Cette distinction entre :
- la présentation ;
- la logique de dialogue ;
- la logique fonctionnelle ;
- les règles de traitement ;
- l'accès aux données ;
- les enchaînements,
permet d'abord, dans tous les cas, une meilleure structuration de la future application distinguant ses différents composants (interface, noyau applicatif, guidage). Elle prépare ensuite la future répartition lorsqu'elle s'effectuera par nature de fonction (cas d'une architecture client / serveur spécialisée par nature).
III-B-5-a-ii. Définir une architecture matérielle▲
La problématique de conception et de formalisation de l'architecture technologique des systèmes d'information ne figure pas dans la démarche et les raisonnements de la méthode Merise. D'ailleurs, des méthodes spécifiques sont venues ultérieurement s'adapter à Merise, en particulier la méthode TACT [Alalk, Lalanne 89].
Cette méthode permet, entre autres, de définir :
- les machines logiques et leurs caractéristiques techniques ;
- les sites logiques ;
- les ressources d'environnement (systèmes d'exploitation, logiciel de développement, communications).
Dans certains cas, les machines logiques peuvent être spécialisées autour d'une fonction particulière ou service : gestion des données, gestion de la présentation, gestion des impressions, gestion des communications. Ces machines logiques dédiées sont appelées serveurs logiques.
III-B-5-a-iii. Répartir les traitements▲
La répartition des traitements formalisés en MLT s'effectue en affectant les différentes ULT aux machines logiques qui les prennent en charge. La formalisation s'exprime à travers des procédures logiques dont les ULT sont distribuées suivant les machines logiques. La figure 12.1 illustre une présentation de MLT réparti.
Actuellement, les répartitions les plus couramment utilisées sont celles permises par les architectures client / serveur, en particulier celles de serveur de données. Dans le cas où un serveur dédié prend en charge la totalité des fonctionnalités de même nature au sein d'une application (par exemple la gestion des données), on pourra faire l'économie d'une représentation du MLT réparti.
III-B-5-b. Modalités de répartition▲
La répartition des traitements et des données d'une application entre différentes machines existe depuis le courant des années 80. Toutefois, les années 90 ont vu ces possibilités se développer grâce en particulier à la normalisation des protocoles de communication aux différents niveaux (middleware) et se concrétiser par l'expansion des architectures clients serveurs.
Répartir des traitements et les données accédées, c'est les installer sur des machines logiques distinctes. Selon les architectures technologiques, on disposera de différentes modalités de répartition.
III-B-5-b-i. Traitements coopératifs▲
Un traitement est coopératif lorsqu'une ULT primaire (non décomposée en ULT élémentaires, c'est-à-dire correspondant à une transaction utilisateur) est exécutée sur plusieurs machines logiques. Cela exige des mécanismes système de synchronisation entre les parties de traitements effectuées sur les différentes machines. Les applications client / serveur sont, par définition, des traitements coopératifs.
Une application pourra pourtant être répartie, mais sans traitement coopératif si des ULT primaires différentes sont exécutées sur des machines différentes (d'une façon transparente pour l'utilisateur) ; par exemple, la procédure d'immatriculation nationale d'un nouvel assuré est réalisée sur le système national dédié alors que le reste de l'application fonctionne sur un système départemental.
III-B-5-b-ii. Données synchronisées▲
La question de synchronisation des données ne concerne que la répartition d'informations identiques (au niveau organisationnel) sur des machines logiques différentes. Ces données seront synchronisées si l'identité des valeurs est maintenue en temps réel sur les différentes machines logiques. En règle générale, cette synchronisation nécessite des dispositifs systèmes sophistiqués (commit en deux phases).
Des données pourront toutefois être réparties sans être synchronisées. L'une des machines logiques sera la référence mise à jour en temps réel, les autres ne disposeront que de copies (clichés) dont la mise à jour pour synchronisation pourra être réalisée en différé (quotidiennement par exemple).
III-B-5-b-iii. Client - serveur▲
Nous avons évoqué à plusieurs reprises l'architecture client - serveur comme champ d'application privilégié de la répartition. Étant donné l'importance prise par ce type d'architecture technologique dans le développement des systèmes d'information, nous avons souhaité consacrer un chapitre spécial à l'utilisation de la méthode Merise dans le cadre du client - serveur.
Aujourd'hui, toutes les approches client - serveur sont basées sur la distinction de trois composants : la présentation, les données et les traitements. La figure 12.15 illustre une correspondance entre ces trois composantes et la décomposition analytique que nous avons proposée pour l'ULT.
III-C. Chapitre 13 Modélisation Logique des Données▲
III-C-1. Problématique de la modélisation logique des données▲
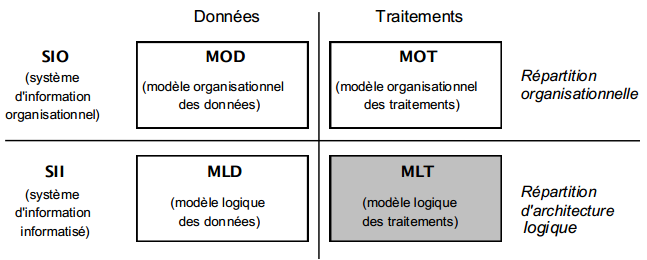
La méthode Merise propose une modélisation logique, puis physique des données. La modélisation logique des données est une représentation des données, issue de la modélisation conceptuelle puis organisationnelle des données. Elle est exprimée dans un formalisme général et compatible avec l'état de l'art technique, et tient compte des aspects coût/performance liés aux traitements.
La modélisation logique des données conduira aux opérations suivantes :
- transformation du MOD, exprimé en formalisme entité-relation, en un MLD (modèle logique de données) exprimé dans un formalisme logique adapté au SGBD (voire système de gestion de fichiers) envisagé ;
- quantification en volume du modèle logique ;
- valorisation de l'activité générée par les modèles externes associés aux traitements (tâches du MOT) ;
- optimisation générale.
Le modèle logique sera ensuite transformé et adapté en fonction des spécificités du langage de définition de données spécifique à l'outil (par exemple le SGBD) retenu, pour devenir modèle physique de données (voir figure 13.1).
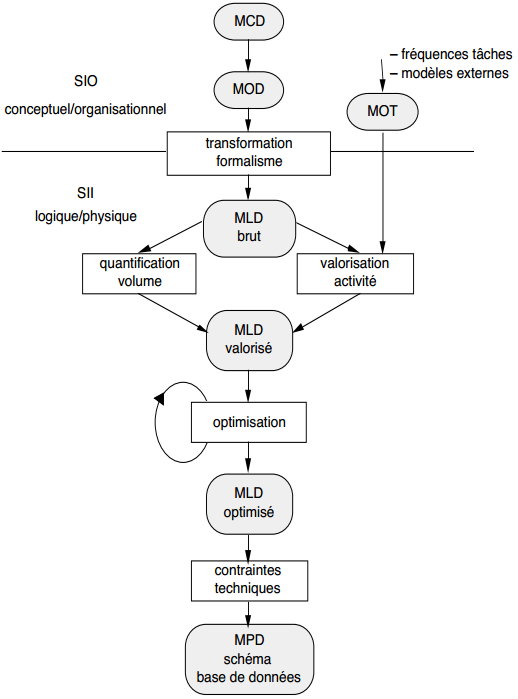
Notons que, si la frontière entre modèle conceptuel/organisationnel et modèle logique est nettement marquée, la frontière est plus floue entre modèle logique et modèle physique, à tel point que l'on nomme parfois modèle interne de données la réunion des modèles logique et physique.
Deux modèles (ou plutôt formalismes) théoriques de bases de données sont disponibles pour la représentation du modèle logique de données : le modèle relationnel et le modèle navigationnel (notamment Codasyl). À ces deux modèles sont associés, respectivement, les systèmes de gestion de bases de MOD données (SGBD) relationnels et navigationnels.
Les SGBD relationnels se sont progressivement imposés au point de constituer, en cette fin des années 90, la quasi-totalité de l'offre du marché (en particulier avec l'offre client/serveur). Aussi, nous ne traiterons dans cet ouvrage que du modèle et des SGBD relationnels, en mettant l'accent sur le passage de la modélisation conceptuelle/organisationnelle des données à la modélisation logique. Le chapitre suivant, le chapitre 14, traitera de l'optimisation tant au niveau logique qu'au niveau physique des modèles de données relationnels.
III-C-2. Modèle logique de données relationnel▲
Le modèle relationnel a été défini par E.F. Codd en 1970 [Codd 70]. Il a rapidement connu un engouement dans les milieux universitaires internationaux par la rigueur qu'il apportait dans la modélisation des données (théorie des ensembles, logique formelle), et l'ouverture qu'il offrait au travers des langages assertionnels. Actuellement, la plupart des systèmes de gestion de bases de données commercialisés sont de type relationnel.
Le modèle relationnel présente deux aspects fondamentaux : une algèbre permettant de manipuler des tables ou relations et ensuite une démarche de conception permettant de définir une collection de relations. Dans le cadre de cet ouvrage, nous ne présenterons de ce modèle que l'essentiel, nécessaire pour conduire l'informatisation d'un système d'information. De nombreux ouvrages ont été consacrés au modèle et aux systèmes relationnels, citons notamment [Date 85] [Delobel 82] [Gardarin 82] [Bouzeghoub, Jouve, Pucheral 90].
III-C-2-a. Concepts de base du modèle relationnel - Concepts structuraux▲
Le modèle relationnel s'appuie sur trois concepts structuraux de base : le domaine, la relation et l'attribut. Nous allons présenter simplement ce modèle ; pour une définition plus formelle, nous renvoyons le lecteur aux ouvrages précédemment indiqués.
La relation, concept central du modèle, peut être définie grossièrement comme un tableau de données. Les colonnes de ce tableau sont appelées les attributs de la relation. Chaque attribut peut prendre des valeurs dans un domaine. Par exemple, le domaine des entiers E = {0, ± 1, ± 2…} ; le domaine des booléens D1 = {0, 1} ; des couleurs D2 = {vert, bleu, blanc, rouge} ; le domaine des caractères… Les lignes de ce tableau, occurrences de la relation, seront appelées tuples ou n-uplets.
Notons que le concept de relation utilisé ici n'a pas la même signification que celui utilisé dans le formalisme entité-relation. Aussi préférerons-nous appeler ce concept table.
On définit aussi pour la table les notions suivantes :
- cardinalité (nombre de lignes ou tuples de la table) ;
- degré (n, nombre de colonnes ou d'attributs de la table).
III-C-2-a-i. Schéma d'une table▲
Le schéma d'une table permet de définir une table. Il est constitué du nom de la table, suivi de la liste de ses attributs avec leurs domaines de valeurs, ainsi que de l'ensemble des contraintes d'intégrité associées à la table (nous définirons plus loin ces contraintes).
Par exemple, une table Pièce décrivant des pièces aura comme schéma :
Pièce (n° : entier ; nom : car (10) ; couleur : couleur ; poids : réel ; ville : car (10)).III-C-2-a-ii. Extension d'une table▲
Étant donné une table, définie par son schéma, une extension de cette table sera un ensemble de lignes ou tuples (ou occurrences), défini par les valeurs prises par les attributs.
Par exemple, une extension de la table Pièce pourrait être :
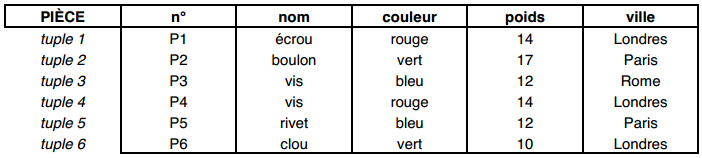
Notons que, pour une extension, l'ordre des tuples ou l'ordre des attributs ne sont pas significatifs.
III-C-2-a-iii. Base de données relationnelle▲
On définira une base de données relationnelle comme un ensemble de tables. Le schéma de la base de données sera l'ensemble des schémas des tables la composant.
Prenons l'exemple de cette base de données relationnelle :
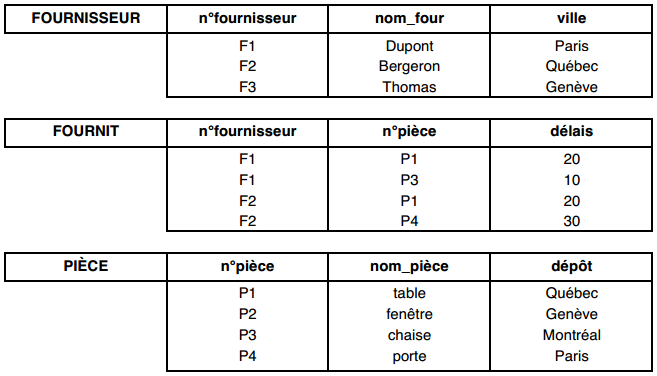
Sans préciser les domaines de chacun des attributs, les schémas relationnels des différentes tables sont :
- Table FOURNISSEUR (n°fournisseur, nom_four, ville) ;
- Table PIECE (n°pièce, nom_pièce, dépôt) ;
- Table FOURNIT (n°fournisseur, n°pièce, délai).
III-C-2-b. Les contraintes d'intégrité▲
Une contrainte d'intégrité est une assertion qui doit être vérifiée par les valeurs d'attributs de tables constituant une base de données. Les deux principaux types de contraintes d'intégrité sont la contrainte d'unicité de valeur, qui nous permettra de définir la clé primaire d'une table, et la contrainte référentielle permettant de relier deux tables. Nous aurons l'occasion de revenir plus précisément sur ces contraintes d'intégrité et d'en évoquer d'autres types.
III-C-2-b-i. Contrainte d'unicité de valeur, clé primaire d'une table▲
Les valeurs prises par un attribut ou une composition d'attributs d'une table peuvent être déclarées uniques pour toute extension de cette table. Ce ou ces attributs permettent alors d'identifier de façon unique chaque tuple de la table. On parle alors de clé primaire simple (un seul attribut) ou clé primaire composée (plusieurs attributs).
Par exemple, dans la base relationnelle précédente, les clés primaires des tables Fournisseur, Fournit et Pièce sont les suivantes (attributs soulignés) :
- table FOURNISSEUR (n°fournisseur, nom_four, ville) : n°fournisseur = clé primaire simple ;
- table PIECE (n°pièce, nom_pièce, dépôt) : n°pièce = clé primaire simple ;
- table FOURNIT (n°fournisseur, n°pièce, délai) : n°fournisseur = clé primaire composée.
Cette notion de clé primaire est équivalente à la notion d'identification définie dans le formalisme entité-relation.
III-C-2-b-ii. Contrainte référentielle▲
Une contrainte référentielle est un lien sémantique défini entre deux tables. Ce lien est réalisé par une duplication de la clé primaire d'une table dans une autre table. Cette clé dupliquée est appelée clé étrangère.
Par exemple, pour la base relationnelle précédente, dans la table FOURNIT (n°fournisseur, n°pièce, délai), n°fournisseur et n°pièce sont chacune des clés étrangères provenant des tables FOURNISSEUR et PIECE.
III-C-2-c. Problèmes liés à la conception de schémas relationnels▲
Considérons par exemple une table P concernant des propriétaires de véhicules et les attributs de cette table :
- nom : nom de la personne propriétaire ;
- date : date d'acquisition du véhicule ;
- tél : dernier téléphone du propriétaire ;
- n° immat : numéro d'immatriculation du véhicule ;
- marque : marque du véhicule ;
- type : type du véhicule ;
- cv : puissance fiscale du véhicule ;
- coul : couleur du véhicule.
Soit une extension de la table P :
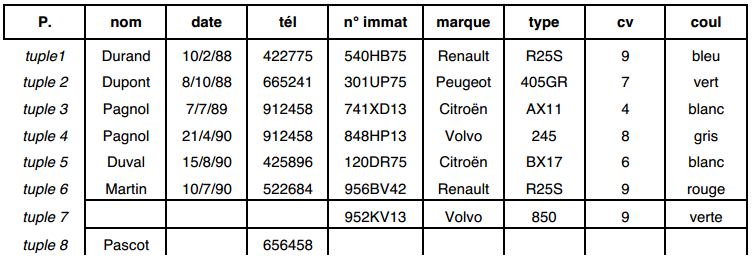
Cette table P pose, dans son utilisation, un certain nombre de problèmes liés à la redondance des données, ou liés à la nécessité d'avoir des attributs pour lesquels on accepte de ne pas avoir de valeurs (valeurs nulles).
III-C-2-c-i. Données redondantes▲
La table P fait apparaître une personne autant de fois que le nombre de voitures qu'elle possède. Aussi toutes les données caractérisant cette personne se retrouvent alors dans plusieurs tuples de la même table. Ce qui conduit à des risques d'incohérences ; par exemple, si M. Pagnol change de numéro de téléphone, il faudra s'assurer que ce changement sera effectué sur chacun des tuples concernant Pagnol, soit pour les tuples 3 et 4.
Une autre redondance est liée à la correspondance type-marque, par exemple Renault-R25S. En effet, par définition, un type donné de véhicule est associé à une seule marque, cette correspondance type-marque apparaît dans autant de tuples qu'il y a de propriétaires possédant ce type de véhicule, cas des tuples 1 et 6. Une autre redondance de même nature concerne la correspondance typecv.
III-C-2-c-ii. Les valeurs nulles▲
La table P concerne à la fois des personnes (propriétaires) et des véhicules. On pourrait, dans cette table, vouloir garder des tuples concernant des voitures sans propriétaire ou des propriétaires sans voiture. Pour les propriétaires sans voiture, les attributs date, n° immat, marque, type, cv, coul n'auront pas de valeur ; ils auront tous et simultanément la valeur nulle.
III-C-2-c-iii. Conception de schémas relationnels▲
Dans les systèmes relationnels, redondances et valeurs nulles (principalement sur clés) sont à éviter, car elles introduisent des incohérences potentielles et compliquent l'exploitation, la manipulation des tables. La présence de redondances et de valeurs nulles dans une table est principalement liée au fait que la table ne concerne pas de vraies entités ou de vraies associations entre entités représentant le réel.
Une première façon de constituer un ensemble de « bonnes » tables (canoniques), c'est-à-dire limitant la redondance et l'usage de valeurs nulles, est de partir d'une table « universelle » dont le schéma se composerait de la totalité des attributs, sur laquelle on applique un processus de normalisation proposé par Codd [Codd 71], mettant en œuvre des opérations de l'algèbre relationnelle (projection). On peut aussi partir d'un ensemble initial de tables quelconques.
Une autre façon de constituer un ensemble de bonnes tables est de les dériver d'un modèle conceptuel/organisationnel de données (MCD/MOD) exprimé en formalisme entité-relation, c'est l'approche privilégiée par la méthode Merise.
Avant d'aborder ces différentes démarches de conception de schémas relationnels, présentons quelques éléments d'algèbre relationnelle.
III-C-2-d. Éléments d'algèbre relationnelle▲
L'algèbre relationnelle proposée par Codd se présente comme un ensemble d'opérations formelles s'appliquant à une ou plusieurs tables pour donner une nouvelle table. Ces opérations permettent d'exprimer des manipulations ensemblistes sur les données de la base sans faire appel à un cheminement explicite. On distingue sept opérations : la sélection, la projection, l'union, l'intersection, la différence, la jointure et la division.
Notons que le langage normalisé SQL, proposé dans la plupart des SGBD relationnels, implémente ces opérations de l'algèbre relationnelle. Dans le cadre de cet ouvrage, nous ne traiterons pas du langage SQL. Le lecteur aura par exemple une présentation complète de ce langage dans [Date 89].
III-C-2-e. La sélection ou restriction▲
L'opération de sélection est une opération unaire qui consiste à sélectionner un ensemble de tuples d'une table, selon un critère de sélection pouvant porter sur un ou plusieurs attributs. Cette opération génère une autre table de même schéma que la table de départ.
Soit la table CLIENT (n°, nom, ville) composée des tuples suivants :

La sélection des clients où ville = PARIS est :

III-C-2-f. La projection▲
Cette opération unaire consiste à :
- ne retenir que certains attributs de la table, c'est-à-dire supprimer certaines colonnes ;
- éliminer les occurrences identiques, c'est-à-dire supprimer les lignes ayant le même ensemble de valeurs (tuples doubles).
On obtient ainsi une nouvelle table dans sa structure. Remarquons que l'opération de projection ne réduit le nombre d'occurrences que si un attribut de la clé primaire a été éliminé de la table projetée.
Soit la table : LIGNE_DE_COMMANDES (n°commande, n°article, date, quantité) composée des tuples suivants :
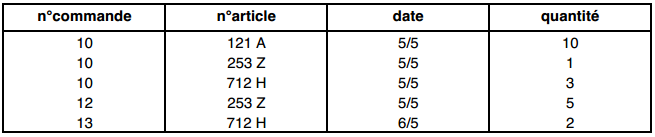
La projection de LIGNE_DE_COMMANDES sur (n°article, date) est :
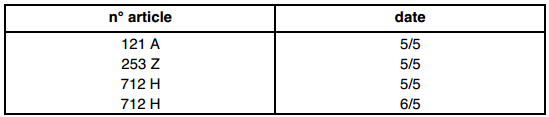
III-C-2-g. La jointure▲
La jointure permet d'obtenir une nouvelle table par la composition de deux tables. Elle consiste à :
- faire le produit cartésien des deux tables, c'est-à-dire concaténer chacune des lignes de la première table avec chacune des lignes de la seconde ;
- effectuer une opération de sélection ou qualification, généralement égalité entre un attribut de la première table et un attribut de la seconde (appelés attributs de jointure) ;
- effectuer ou non une opération de projection pour réduire le schéma de la table résultante.
En d'autres termes, l'opération de jointure réalise une concaténation de tables limitée à des occurrences de tables présentant des valeurs communes sur des attributs de jointure. Cette opération matérialise le lien entre plusieurs tables ou la fusion de plusieurs tables.
Si l'opérateur de jointure est généralement l'égalité, la jointure peut être étendue à des opérateurs logiques quelconques.
Les opérations de jointure peuvent s'effectuer sur tout attribut, sans préjuger de la pertinence sémantique du résultat obtenu. Toutefois, on démontrerait que seules les jointures en égalité construites sur les attributs clés primaires traduisent des relations (conceptuelles).
Notons que la jointure naturelle de deux tables S et R est une jointure telle que les attributs de jointure sont les attributs de R et de S qui ont mêmes noms, et qu'elle est suivie par une projection permettant de conserver un seul de ces attributs égaux de même nom. R et S peuvent être la même table, on a alors une jointure d'une table sur elle-même.
Soient les tables CLIENT et COMMANDE composées des tuples suivants :
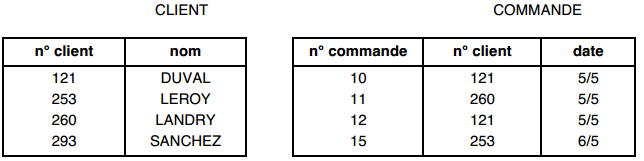
La jointure CLIENT et COMMANDE est telle que n°client de la table

III-C-2-h. Les opérations ensemblistes : union, intersection et différence▲
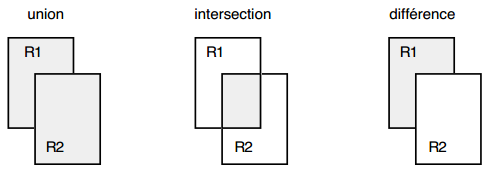
En considérant les tables comme des ensembles de tuples, ces opérations binaires — union, intersection et différence — correspondent aux opérations habituelles de la théorie des ensembles. Ces opérations ne peuvent être appliquées que sur des tables de même schéma et donnent une nouvelle table de même schéma (voir la figure 13.2).
III-C-2-i. La division▲
L'opération de division est une opération binaire. Le quotient de la division d'une table R de schéma R (A1, A2… An) par la sous-table S de schéma S (Ap… An) est la table Q définie ainsi :
- Le schéma de Q est constitué de tous les attributs de R n'appartenant pas à S, soit (A1, A2… Ap-1).
- Les tuples de Q sont tels que, concaténés à chacun des tuples de S, ils donnent toujours un tuple de R.
Cette opération de l'algèbre relationnelle présente en fait un intérêt limité.
Par exemple, la division de la table PIECE par la table NATURE donne la table PIECE_NATURE.
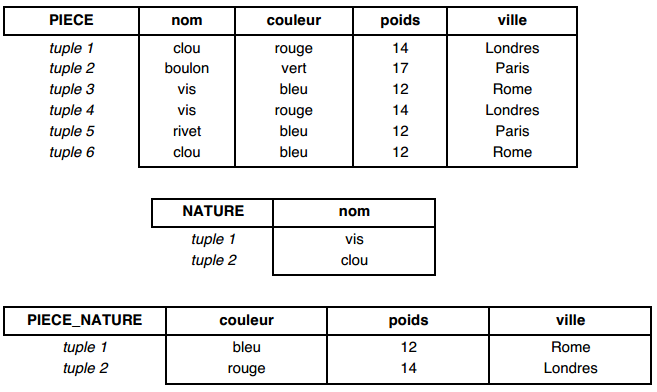
Les tuples de la table Pièce_Nature concaténés à chacun des tuples de la table Nature donnent un tuple de la table Pièce.
III-C-2-j. Processus de normalisation▲
Comme nous l'avons évoqué précédemment, une première façon de constituer un ensemble de bonnes tables limitant le risque d'incohérences potentielles (éviter les redondances et les valeurs nulles) est de partir d'une table universelle dont le schéma se compose de la totalité des attributs, sur laquelle on applique un algorithme de normalisation, ou théorie de la normalisation.
La normalisation nécessite de disposer de plus de sémantique sur les données. Cette sémantique complémentaire s'exprimera au travers des dépendances fonctionnelles (DF) entre attributs. La normalisation se présente alors comme un processus de décomposition de cette table de départ en plusieurs tables par des projections définies judicieusement en fonction de ces dépendances fonctionnelles entre attributs. Ce processus de normalisation, ou théorie de la normalisation, peut être illustré de la façon suivante (cf. figure 13.3) :
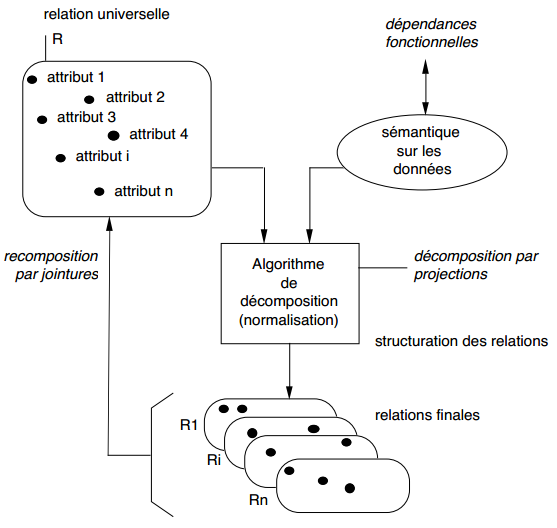
Notons que ce processus est absolument réversible et permet, à partir des tables normalisées, de retrouver les tables de départ, au moyen de jointures.
Codd a proposé trois formes normales, auxquelles ont ultérieurement été ajoutées d'autres formes normales comme les 4e, 5e formes normales ou la forme de Boyce-Codd. Ces autres formes normales peuvent être considérées comme des raffinements du modèle relationnel face à des problèmes très particuliers (optimisation).
Dans l'ensemble des tables pouvant être générées par décomposition, un sous-ensemble de tables est en 1re forme normale ; dans ce sous-ensemble, certaines tables sont en 2e forme normale, enfin, parmi ces dernières tables, certaines sont en 3e forme normale (voir figure 13.4).

III-C-2-k. Notion de dépendance fonctionnelle▲
Un attribut (ou groupe d'attributs) B d'une table R est fonctionnellement dépendant d'un autre attribut (ou groupe d'attributs) A de R si, à tout instant, chaque valeur de A n'a qu'une valeur associée de B : on note A -> B.
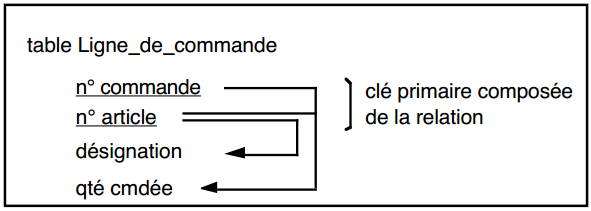
Soit la table Ligne_de_commande (n° commande, n° article, désignation, qté cmdée) dans laquelle il s'agit de la désignation de l'article et de la quantité commandée d'articles dans la commande. On a les dépendances fonctionnelles suivantes :
- n° article -> désignation (à une valeur de n° article ne correspond qu'une valeur de désignation) ;
- (n° commande, n° article) -> qté cmdée (à un couple de valeurs n° commande et n° article, ne correspond qu'une valeur de qté cmdée).
On peut représenter ces dépendances fonctionnelles ainsi :
III-C-2-k-i. Propriétés des dépendances fonctionnelles▲
Les dépendances fonctionnelles sont :
- réflexivité (A -> A) ;
- transitivité (A -> B et B -> C alors A -> C).
III-C-2-k-ii. Clé primaire d'une table▲
La clé primaire d'une table est un attribut (ou un ensemble d'attributs) tel que tous les autres attributs (non-clés) de la table sont en dépendance fonctionnelle avec la clé primaire.
Exemples :
Soit la Table Client (n° client, nom, adresse) ; on a les dépendances fonctionnelles :
- n° client -> nom ;
- n° client -> adresse.
n° client est clé primaire de la table Client.
Soit la Table Ligne (n° commande, n° article, désignation, qté cmdée) ; on a les dépendances fonctionnelles suivantes :
- n° commande, n° article -> désignation ;
- n° commande, n° article -> qté cmdée.
(n° commande, n° article) est clé primaire composée de la table Ligne.
Il faut d'autre part vérifier qu'aucun sous-ensemble des attributs composant la clé primaire ne pourrait également être une clé primaire de la table.
III-C-2-l. Première forme normale (1NF)▲
Cette normalisation s'applique sur des tables quelconques. La 1re forme normale a pour objet d'éliminer les groupes répétitifs dans une table. La démarche est la suivante :
- Sortir le groupe répétitif de la table initiale.
- Transformer le groupe répétitif en table, rajouter dans la clé de cette nouvelle table la clé primaire de la table initiale.
Ce processus de mise en première forme normale est récursif dans le cas où la table initiale comprend plusieurs niveaux de répétitivité.
On remarque que cette 1re forme normale s'apparente à la règle de vérification (ou non-répétitivité) utilisée dans le formalisme entité-relation.
Soit la table Commande (n° commande, date, n° client, nom, n° article, désignation, qté cmdée). L'attribut nom est le nom du client et désignation est la désignation de l'article. Cette table présente également un groupe répétitif :
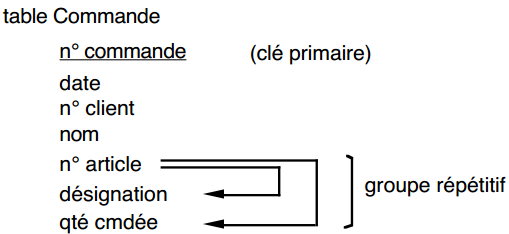
Tables en première forme normale obtenues après élimination des groupements répétitifs :

III-C-2-m. Deuxième forme normale (2NF)▲
Cette normalisation exige que la table soit déjà en 1re forme normale. Elle ne concerne que les tables à clé primaire composée (composée de plusieurs attributs).
La règle impose que les attributs non-clé primaire dépendent de la totalité de la clé primaire. Tout attribut qui ne dépendrait que d'une partie de la clé primaire doit être exclu de la table. Le processus est le suivant :
- regrouper dans une table les attributs dépendant de la totalité de la clé, et conserver cette clé pour cette table ;
- regrouper dans une autre table les attributs dépendant d'une partie de la clé, et faire de cette partie de clé la clé primaire de la nouvelle table.
On remarque que cette deuxième forme normale s'apparente à la règle de normalisation d'une relation utilisée dans le formalisme entité-relation.
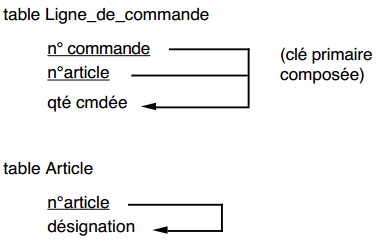
Dans notre exemple, la table Article_commande n'est pas en deuxième forme normale, car l'attribut non-clé désignation ne dépend pas totalement de la clé primaire composée :
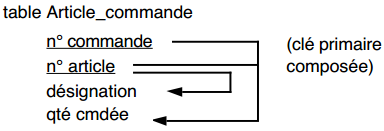
Le passage en deuxième forme normale nous conduira à remplacer cette table Article par les tables en deuxième forme normale suivantes :
III-C-2-n. Troisième forme normale (3NF)▲
La mise en troisième forme normale ne s'applique que sur des tables déjà en deuxième forme normale. La règle a pour objet l'élimination des dépendances transitives au sein d'une table. La démarche est la suivante :
- Conserver dans la table initiale les attributs dépendant directement de la clé.
- Regrouper dans une table les attributs dépendant transitivement ; l'attribut de transition reste dupliqué dans la table initiale, et devient la clé primaire de la nouvelle table.
Notons que Codd et de nombreux spécialistes ont démontré rigoureusement qu'un modèle de données en troisième forme normale était une forme « canonique » sur un ensemble de données, et qu'il minimisait ainsi la redondance de la future base de données.
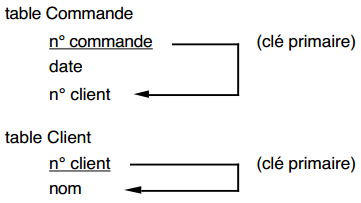
Dans notre exemple, la table Commande précédente n'est pas en troisième forme normale, car l'attribut non-clé nom dépend de la clé par transitivité :
Le passage en troisième forme normale nous conduira à remplacer cette table Commande par les tables suivantes :
III-C-2-o. Forme normale de Boyce-Codd (BCNF)▲
La mise en forme normale de Boyce-Codd permet d'éviter des redondances dues à l'existence de dépendances fonctionnelles autres que celles de la clé vers des attributs non-clés.
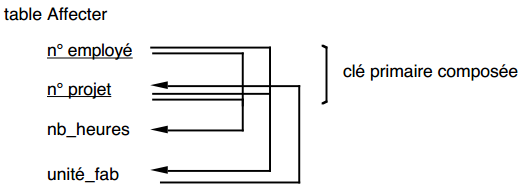
Soit un exemple dans lequel un employé est affecté (un certain nombre d'heures) à un certain nombre de projets effectués dans un certain nombre d'unités de fabrication (une unité de fabrication ne traite qu'un projet donné). Voici la table Affecter associée permettant de prendre en compte cette affectation :
Le passage en forme de Boyce-Codd nous conduira à remplacer cette table par les tables suivantes :
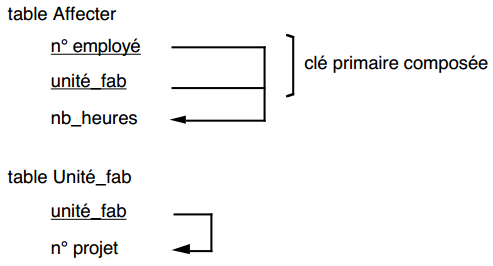
La décomposition en forme de Boyce-Codd est sans perte. On notera que la dépendance fonctionnelle n° employé -> unité_fab a disparu, mais qu'elle peut être recomposée par jointure des deux nouvelles tables sur l'attribut unité_fab.
III-C-2-p. Notion de vue relationnelle▲
La plupart des SGBD relationnels permettent la définition de vues. Une vue est une table virtuelle pouvant être composée à partir d'une ou plusieurs tables. Le contenu et le schéma d'une vue sont déduits des tables comme étant le résultat d'une requête d'interrogation mettant en œuvre des opérations d'algèbre relationnelle. Le langage normalisé SQL permet de définir de telles vues.
III-C-2-q. Formalisation graphique du modèle relationnel▲
Les représentations des tables en extension par des tableaux de tuples, ou en intention par les schémas, sont intéressantes, mais limitées pour expliciter les liens sémantiques entre les tables. Une représentation graphique aidera le concepteur à spécifier ces liens sémantiques et les contraintes d'intégrité référentielle associées. Plusieurs représentations graphiques du modèle relationnel ont été proposées [Senko 76, Everest 77, Ridjanovic 83…]. Dans le cadre de cet ouvrage, nous en avons retenu une que nous allons présenter.
III-C-2-r. La table, ses attributs et sa clé primaire▲
Soit une table Employé de schéma : Employé (matricule, nom , âge, adresse), matricule étant défini ici comme clé primaire. La figure 13.5 montre la représentation graphique associée à cette table.
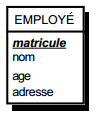
Notons que, dans cette représentation graphique, le ou les attributs composant la clé primaire de la table sont soulignés.
III-C-2-s. Contraintes d'intégrité référentielle▲
Rappelons qu'une telle contrainte reliera deux tables A et B de telle sorte qu'à une valeur de la clé primaire de B puissent correspondre plusieurs valeurs de clés primaires de A, et qu'à une valeur de clé primaire de A ne corresponde au plus qu'une valeur de clé primaire de B. On parlera de lien relationnel un vers plusieurs.
Cette liaison conduit à une duplication dans la table A de la clé primaire de la table B, qui devient ainsi dans la table A une clé étrangère. La figure 13.6 montre la représentation graphique associée.
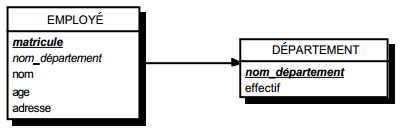
On notera que, dans cette représentation, l'attribut nom_departement de la table EMPLOYE est clé étrangère et pointe vers l'attribut nom_departement , clé primaire de la table DEPARTEMENT. La lecture de ce modèle graphique conduit ainsi aux schémas des tables suivantes :
- table DEPARTEMENT (nom_departement , effectif…) ;
- table EMPLOYE (matricule., nom_departement (clé étrangère), nom, âge, adresse).
III-C-2-t. Clé primaire composée référentielle ▲
Soit une table TACHE, reliée à une table PROJET par une contrainte d'intégrité référentielle. La table TACHE a une clé primaire composée faisant référence à la table PROJET : ainsi l'attribut n°projet de la table TACHE est clé étrangère et participe aussi à la clé primaire (voir figure 13.7).
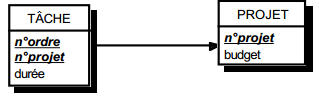
Ce qui donne par simple lecture les schémas suivants :
- table TACHE (n° projet, n° ordre (clé étrangère), durée) ;
- table PROJET (n° projet, budget).
III-C-2-u. Règles de transformation du formalisme entité-relation en formalisme relationnel▲
Une seconde façon de constituer une collection de bonnes tables est de la dériver d'un MOD (modèle organisationnel de données) ou d'un MCD (modèle conceptuel de données) exprimé en formalisme entité-relation (voir figure 13.8).
Cette transformation est entièrement algorithmique, mais n'est pas totalement réversible. Le modèle ainsi obtenu est obligatoirement en deuxième forme normale. Il n'est pas nécessairement en troisième forme, le choix des entités n'étant pas guidé sur la redondance minimale.
En toute rigueur, il conviendrait de vérifier si les tables issues des entités sont en troisième forme normale ; ce qui est fréquemment le cas.
Notons que le développement de la rétroconception (reverse engineering) a rendu nécessaire l'élaboration de règles permettant de construire un MCD/MOD exprimé en entité-relation à partir d'un MLD relationnel. Les règles utilisées reconstituent les modélisations en entité-relation les plus probables, mais n'offrent pas une certitude de rétroconception.
III-C-2-v. Entité▲
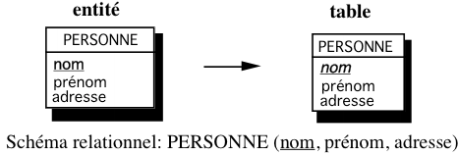
Toute entité type est transformée en table. Ses propriétés deviennent des attributs de la table. L'identifiant devient la clé primaire de la table (voir figure 13.9).
Remarquons que l'entité ne comportant que l'identifiant comme propriété présente un cas particulier. Il devient provisoirement une table avec sa clé primaire comme seul attribut. Il est fort probable que les optimisations ultérieures fassent disparaître cette table.
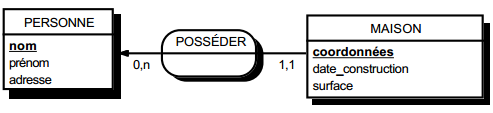
III-C-2-w. Relation binaire (0,n)-(1,1) ou (1,n)-(1,1)▲
On duplique la clé de la table issue de l'entité à cardinalité (0,n) ou (1,n) dans la table issue de l'entité à cardinalité (1,1) où elle devient une clé étrangère. On procède éventuellement à un changement d'appellation de l'attribut dupliqué qui conserve cependant son domaine de valeurs, comme l'illustre la clé étrangère nom_propriétaire de la table MAISON de la figure 13.10.
 |
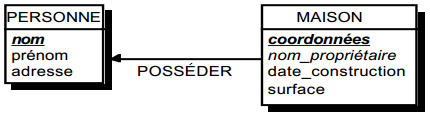 |
Schémas relationnels associés à la figure 13.10 :
- table PERSONNE (nom, prénom, adresse) ;
- table MAISON (coordonnées, nom_propriétaire, date_construction, surface).
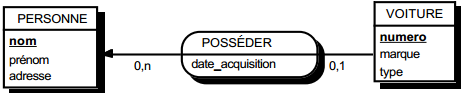
III-C-2-x. Relation binaire (0,n)-(0,1) ou (1,n)-(0,1)▲
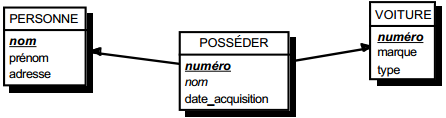
Deux solutions sont possibles.
La première solution (solution 1) consiste à créer une table avec comme clé primaire l'identifiant de l'entité à cardinalité (0,1) ; l'identifiant de l'autre entité devenant clé étrangère de cette table. Les éventuelles propriétés de la relation deviennent aussi attributs de la table issue de la relation.
 |
 |
 |
Schémas relationnels associés à la figure 13.11 :
Solution 1 :
- table PERSONNE (nom, prénom, adresse) ;
- table POSSEDER (numéro, nom, date_acquisition) ;
- table VOITURE (numéro, marque, type).
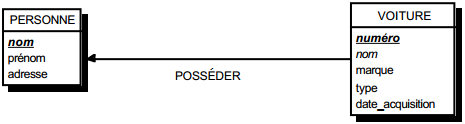
Solution 2 :
- table PERSONNE (nom, prénom, adresse) ;
- table VOITURE (numéro, nom, marque, type, date_acquisition).
Dans la seconde solution (solution 2), on duplique comme clé étrangère la clé de la table issue de l'entité à cardinalité (0,n) ou (1,n) dans la table issue de l'entité à cardinalité (0,1). On procède éventuellement à un changement d'appellation de l'attribut dupliqué qui conserve cependant son domaine de valeurs. Les éventuelles propriétés de la relation (conceptuelle) deviennent des attributs de la table issue de l'entité à cardinalité (0,1) (voir figure 13.11).
Remarque : dans la seconde solution, la cardinalité (0,1) posera le problème, pouvant être difficile à gérer selon le SGBD adopté, d'accepter des valeurs nulles sur la clé étrangère.
III-C-2-y. Relation binaire (0,1)-(1,1)▲
C'est en fait une particularisation des cas précédemment traités, correspondant souvent à exprimer des sous-types. On duplique la clé de la table issue de l'entité à cardinalité (0,1) dans la table issue de l'entité à cardinalité (1,1) (voir figure 13.12).
 |
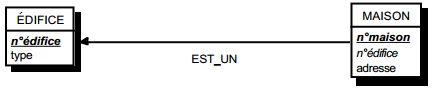 |
Schémas relationnels associés à la figure 13.12 :
- table EDIFICE (n°édifice, type) ;
- table MAISON (n°maison, n°édifice, adresse).
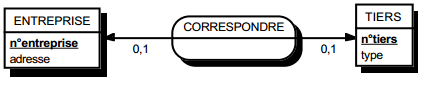
III-C-2-z. Relation binaire (0,1)-(0,1)▲
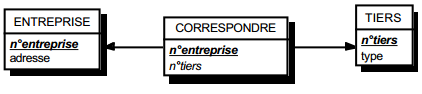
C'est en fait également une particularisation des cas précédemment traités. Deux types de solutions sont possibles. Le premier consiste à créer une table avec comme clé les identifiants des entités concernées par la relation considérée. Les éventuelles propriétés de cette relation deviennent des attributs de cette table issue de la relation. La clé de cette table de lien peut être la clé primaire de l'une des deux tables issues des entités (voir figure 13.13).
 |
 |
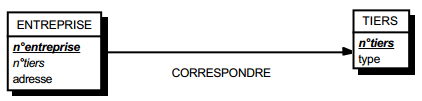
L'autre type de solutions consiste à dupliquer de la clé d'une table issue d'une entité dans l'autre table issue de l'autre entité. Les éventuelles propriétés de cette relation deviennent des attributs de la table dans laquelle a migré l'identifiant externe (voir figure 13.14).
Dans ces deux dernières solutions, la cardinalité (0,1) posera le problème, pouvant être difficile à gérer selon le SGBD adopté, d'accepter des valeurs nulles sur l'attribut migrant. Ce problème des valeurs nulles pourra, dans certains cas, fixer le sens de migration (par exemple, la taille des clés). On peut considérer cette seconde solution comme associée à un choix d'optimisation, comme nous le verrons dans le chapitre qui y est consacré.
 |
 |
Schémas relationnels associés :
Solution 1 :
- table ENTREPRISE (n°entreprise, adresse) ;
- table TIERS (n°tiers, type) ;
- table CORRESPOND (n°entreprise, n° tiers).
Solution 2 :
- table ENTREPRISE (n°entreprise, adresse) ;
- table TIERS (n° tiers, type) ;
- table CORRESPOND (n°entreprise, n° tiers ).
Solution 3 :
- table ENTREPRISE (n°entreprise, adresse) ;
- table TIERS (n° tiers, n°entreprise, adresse).
Solution 4 :
- table ENTREPRISE (n° entreprise, n° tiers, adresse) ;
- table TIERS (n° tiers, type).
III-C-2-aa. Relation binaire (0,n)-(0,n) ou (1,n)-(1,n) ou (1,n)-(0,n) ▲
La solution consiste à créer une table ayant comme clé une clé composée des identifiants des deux entités. Les éventuelles propriétés de cette relation deviennent des attributs de la table issue de la relation (voir figure 13.15).
 |
 |
Schémas relationnels associés à la figure 13.15 :
- table COMMANDE (n°commande, date, statut) ;
- table PORTER (n°article, n°commande, quantité_commandée) ;
- table ARTICLE (n°article, désignation, quantité_stock, prix).
III-C-2-ab. Relation ternaire ou supérieure▲
La transformée d'une relation ternaire ou supérieure, quelles que soient les cardinalités, consiste à créer une table ayant comme clé une clé composée des identifiants des diverses entités reliées par la relation considérée. Les éventuelles propriétés de cette relation deviennent des attributs de la table issue de la relation. Il s'agit en fait de la généralisation de la règle précédente (voir figure 13.16).
Remarque : rappelons qu'une relation n-aire munie de cardinalité (1,1) aura été au préalable décomposée, comme nous l'avons déjà indiqué dans la partie précédente.
 |
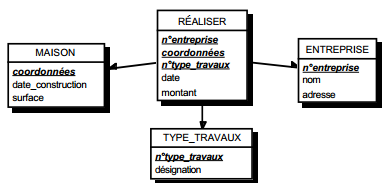 |
Schémas relationnels associés à la figure 13.16 :
- table MAISON (coordonnées, date_construction, surface) ;
- table TYPE_TRAVAUX (n°type_travaux, désignation) ;
- table RÉALISER (n°entreprise, coordonnées, date, montant) ;
- table ENTREPRISE (n°entreprise, nom, adresse).
III-C-2-ac. Relation réflexive (sur la même entité type)▲
Relation binaire réflexive (0,n)-(0,1)
C'est en fait une particularisation des cas précédemment traités. Dans une première solution, la relation conduit à la création d'une table dans laquelle la clé primaire de la table issue de l'entité se retrouve à la fois comme clé et comme simple attribut. On procède à un changement d'appellation de ces attributs dupliqués qui conservent cependant leur domaine de valeurs. Les éventuelles propriétés de cette relation deviennent des attributs de cette table associée.
Dans une seconde solution, on duplique la clé de la table issue de l'entité dans la table issue de l'entité à cardinalité (0,1). On procède à un changement d'appellation de l'attribut dupliqué qui conserve cependant son domaine de valeurs (n° tâche_précédente). Les éventuelles propriétés de cette relation deviennent des attributs de la table issue de l'entité (voir figure 13.17).
 |
 |
 |
Schémas relationnels associés à la figure 13.17 :
Solution 1 :
- table TACHE (n°tâche, désignation, durée) ;
- table PRÉCÉDER (n°tâche, n°tâche_suit ).
Solution 2 :
- table TACHE (n°tâche, n°tâche_précède, désignation, durée).
Dans cette seconde solution, la cardinalité (0,1) posera le problème d'accepter des valeurs nulles sur l'attribut migrant. On peut considérer cette seconde solution comme associée à un choix d'optimisation, comme nous le verrons dans le chapitre qui y est consacré.
Relation binaire réflexive (*,n)-(*,n)
La solution consiste à créer une table de lien ayant comme clé une clé composée de deux fois l'identifiant de l'entité. Les clés étrangères seront qualifiées par rapport aux rôles des pattes de la relation. Les éventuelles propriétés de cette relation deviennent des attributs de cette table issue de la relation (voir figure 13.18).
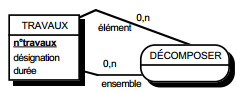 |
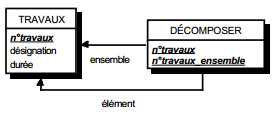 |
Schémas relationnels associés à la figure 13.18 :
- table TRAVAUX (n°travaux, désignation, durée) ;
- table DÉCOMPOSER (n°travaux, n°travaux_ensemble).
III-C-2-ad. Prise en compte des sous-types du MCD/MOD - Spécialisation▲
Plusieurs solutions possibles.
Solution 1 :
On exprime les sous-types par des tables spécifiques, correspondant en fait à des relations (0,1)-(1,1). Il y a ainsi migration de l'identifiant du surtype dans les sous-types (figure 13.19).
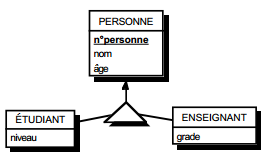 |
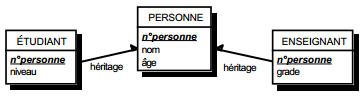 |
Schémas relationnels associés à la solution 1 (figure 13.19) :
- table PERSONNE (n°personne, nom, age) ;
- table ETUDIANT (n°personne, niveau) ;
- table ENSEIGNANT (n°personne, grade).
Solution 2 :
Comme dans la solution précédente, on exprime les sous-types par des tables spécifiques. Il y a duplication des attributs du surtype dans les sous-types associés, dont la mise à jour simultanée peut être réalisée à travers un mécanisme automatique implémentant l'héritage, par exemple par triggers (cf. figure 13.19.b).
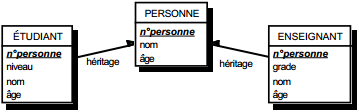 |
Solution 3 :
Dans cette solution, on duplique la totalité du contenu du surtype dans les sous-types associés et on supprime le surtype. Cette solution n'est pas conseillée dans le cas où il existe, dans le modèle conceptuel (entité-relation), des relations portant sur le surtype (cf. figure 13.19.c).
 |
Solution 4 :
On transfère la totalité des propriétés des sous-types dans la table correspondant au surtype. On exprime ensuite les sous-types par des vues relationnelles d'une table PERSONNE globale. Dans l'exemple, les sous-types ETUDIANT et ENSEIGNANT sont exprimés par des vues relationnelles de la table PERSONNE rassemblant l'ensemble des propriétés spécifiques aux sous-types (cf. figure 13.19.d).
 |
Pour faciliter l'expression de ces vues, on peut introduire un nouvel attribut « type_personne » dont le domaine est {étudiant, enseignant} :
- table PERSONNE (n°personne, nom, age, type_personne, niveau, grade…) ;
avec comme définition des vues :
- vue PERSONNE_ETUDIANT : vue de PERSONNE (sélection + projection) ;
- vue PERSONNE_ENSEIGNANT : vue de PERSONNE (sélection + projection).
Soit en SQL :
CREATE VIEW PERSONNE_ETUDIANT AS SELECT n° personne, nom, age, niveau… FROM PERSONNE WHERE PERSONNE.type_personne = 'étudiant';
CREATE VIEW PERSONNE_ENSEIGNANT AS SELECT n° personne, nom, age, grade… FROM PERSONNE WHERE PERSONNE.type_personne = 'enseignant';III-C-2-ae. Généralisation▲
Dans le cas d'une généralisation, les sous-types ont leurs propres identifiants. Ainsi, seules les transformations des solutions précédentes 1 et 2 sont possibles, comme l'illustre la figure 13.20.
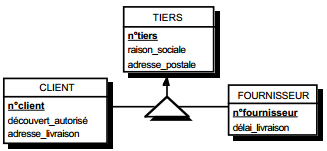 |
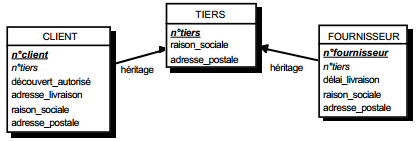 |
Schémas relationnels associés à la figure 13.20 :
- table TIERS (n°tiers, raison_sociale, adresse_postale) ;
- table CLIENT (n°client, n°tiers, découvert_autorisé, adresse_livraison, raison_sociale, adresse_postale) ;
- table FOURNISSEUR (n°fournisseur, n°tiers, délai_livraison, raison_sociale, adresse_postale).
Remarque : nous sommes strictement dans le cas d'une relation (0,1)-(1,1).
Dans les tables CLIENTS et FOURNISSEURS, l'attribut n°tiers sera déclaré comme une clé candidate ou clé alternative (cf. « Valeurs uniques » du paragraphe sur la prise en compte des contraintes de ce chapitre) et sera déclaré dans le schéma avec une clause UNIQUE.
III-C-2-af. Exclusion sur spécialisation et généralisation▲
Une exclusion sur spécialisation ou généralisation s'exprime dans un MCD/MOD par un « X » indiquant une contrainte d'exclusion dans le triangle du sous-typage. Cette contrainte sera prise en compte au niveau logique par l'écriture de triggers spécifiques comme l'illustre la figure 13.21 relative à une généralisation.
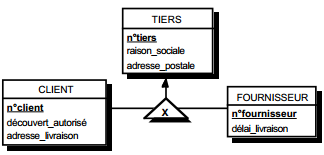 |
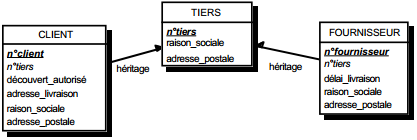 |
Schémas relationnels associés à la figure 13.21 :
- table TIERS (n° tiers, n° client, n° fournisseur, raison sociale, adresse…) ;
- table CLIENT (n° client, n° tiers, découvert autorisé, adresse de livraison) ;
- table FOURNISSEUR (n° fournisseur, n° tiers, délai de livraison).
La contrainte d'exclusion implémentée par triggers spécifiques.
III-C-2-ag. Identifiant relatif▲
Nous avons vu au chapitre 7Chapitre 7 Modélisation conceptuelle des données que toute entité type devait être dotée d'un identifiant et nous avons évoqué la difficulté d'inventer de telles propriétés. Certaines entités types ont par ailleurs une existence totalement dépendante d'autres entités types. On a alors recours à un identifiant relatif. L'identification relative est notée par (R) sur la patte servant de relativité. Dans l'exemple de la figure 13.22, l'identifiant de la tranche est n° d'ordre relatif à projet.
La transformée d'une identification relative revient à définir pour la table fille issue de l'entité identifiée relativement, une clé primaire composée constituée de la clé primaire transformée de l'identifiant de cette entité et de la clé étrangère implémentant la relation servant l'identification relative, comme l'illustre la figure 13.22.
 |
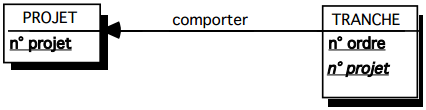 |
Schémas relationnels associés à la figure 13.22 :
- table PROJET (n°projet…) ;
- table TRANCHE (n°ordre, n°projet…).
III-C-2-ah. Prise en compte de l'historisation - Historisation de propriété▲
La conservation des valeurs antérieures (historisation) ne s'applique qu'à certaines propriétés d'une entité ou d'une relation. Graphiquement, on indique alors le caractère historisable par un (H) au niveau de la propriété, comme nous l'avons déjà vu dans le chapitre 7Chapitre 7 Modélisation conceptuelle des données. La transformation au niveau logique relationnel s'effectue de la façon suivante (voir figure 13.22) :
 |
 |
Notons que pour toutes les historisations, l'attribut de datation de l'historisation (DATE_HISTO) rentrant dans la clé primaire de la table d'historisation (ici H_adresse_PERSONNE) est déduit de la valeur de datation (jour, semaine, mois…).
III-C-2-ai. Historisation d'entité▲
Pour toute modification de valeur de l'une des propriétés d'une entité, on historise l'ensemble des valeurs des propriétés de l'entité. Graphiquement, on indique alors le caractère historisable par un (H) au niveau de l'entité, comme déjà vu dans le chapitre 7Chapitre 7 Modélisation conceptuelle des données. La transformation au niveau logique relationnel s'effectue ainsi (voir figure 13.23) :
 |
 |
III-C-2-aj. Historisation de relation▲
Pour toute modification de valeur de l'une des propriétés d'une relation, on historise l'ensemble des valeurs des propriétés de la relation ainsi que son identification. Graphiquement, on indique alors le caractère historisable par un (H) au niveau de la relation (voir chapitre 7Chapitre 7 Modélisation conceptuelle des données). La transformation au niveau logique relationnel s'effectue de la façon suivante (voir figure 13.24) :
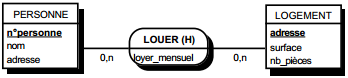 |
 |
III-C-2-ak. Historisation de patte de relation▲
Comme nous l'avons déjà indiqué dans le chapitre 7Chapitre 7 Modélisation conceptuelle des données, l'historisation d'une patte d'une relation se présente lorsque, lors de la modification d'une patte de relation, on souhaite historiser la patte précédente, c'est-à-dire conserver la valeur de l'identifiant de l'occurrence précédente de l'entité dans la patte. Graphiquement, on indique alors le caractère historisable par un (H) au niveau de la patte concernée de la relation.
Cas d'une relation binaire (*,n)-(*n), ternaire ou supérieure
La figure 13.25, déjà présentée au chapitre 7Chapitre 7 Modélisation conceptuelle des données, illustre un tel cas. Il s'agit ici d'historiser les changements de dossiers d'un contribuable.
La relation concernée par l'historisation est transformée en table (ici la table CONCERNER). On crée une nouvelle table d'historisation (la table H_CONCERNER_DOSSIER) avec une clé primaire composée des clés primaires des tables DOSSIER et CONTRIBUABLE et d'un attribut Date _Histo. Cette table d'historisation possède aussi un attribut clé étrangère (ici n°dossier_précédent) qui réfère au dossier antérieur concerné de la table DOSSIER assurant ainsi l'historisation.
 |
 |
Cas d'une relation binaire (*,n)-(1,1)
Deux cas se présentent selon que l'on souhaite, pour une telle relation, historiser la patte avec la cardinalité (*,n) ou la patte avec la cardinalité (1,1).
Historisation de la patte (*, n)
Un tel cas est illustré par la figure 13.26, concernant l'historisation des changements de secteurs d'un vendeur.
La relation est transformée en clé étrangère dans la table issue de l'entité côté (1,1). Pour historiser la patte (*,n) de la relation (ici la relation RATTACHER), on crée une nouvelle table d'historisation (la table H_RATTACHER_VENDEUR dans l'exemple) avec une clé primaire composée de la clé primaire de la table issue de l'entité côté cardinalité (1,1) et d'un attribut Date_Histo. Cette table d'historisation possède aussi un attribut clé étrangère qui réfère à la table issue de l'entité qui intervenait dans la patte à historiser (ici la table SECTEUR). Cet attribut accueille la valeur antérieure réalisant l'historisation.
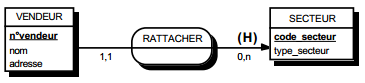 |
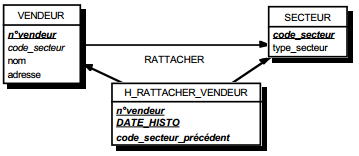 |
Historisation de la patte (1,1)
Un tel cas est illustré par la figure 13.27, concernant l'historisation de la composition d'une équipe.
La relation (ici la relation COMPOSER) est transformée en clé étrangère dans la table issue de l'entité côté (1,1) (table JOUEUR). Pour historiser la patte (1,1) de cette relation, on crée une nouvelle table d'historisation (ici la table H_COMPOSER_JOUEUR) avec une clé primaire composée de la clé primaire de la table issue de l'entité côté cardinalité (1,1) et d'un attribut Date_Histo. Cette table d'historisation possède aussi un attribut clé étrangère (ici ident_joueur_précédente) qui réfère encore à cette table issue de l'entité côté (1,1). Cet attribut accueille la valeur antérieure permettant ainsi l'historisation.
 |
 |
III-C-2-al. Triggers d'historisation automatique▲
Dans la transformation Entité-Relation (MCD/MOD) vers un modèle logique de données relationnel (MLD), il est possible de générer des triggers qui, selon les cas d'historisation, permettent, lors de la modification des propriétés (devenues des attributs non-clés) ou de la collection d'une relation (devenues des clés étrangères), de faire automatiquement la création de l'occurrence de la table d'historisation correspondante avec éventuellement le contrôle par rapport à la datation (simple modification ou historisation) et à la profondeur (suppression des valeurs les plus anciennes).
III-C-3. Intégrité dans les bases de données relationnelles▲
III-C-3-a. Intégrité et contraintes d'intégrité▲
L'intégrité d'une base de données consiste à assurer une constante concordance des données avec le monde réel que la base de données modélise. Le maintien de l'intégrité de la base de données est une fonction essentielle des SGBD relationnels. Les aspects liés à l'intégrité d'une base de données sont multiples :
- l'intégrité sémantique ;
- le contrôle de concurrence ;
- la protection des données ;
- la sécurité des données.
Dans le cadre de cet ouvrage, nous ne nous intéresserons qu'à l'intégrité sémantique. Nous renvoyons le lecteur à des ouvrages spécialisés sur les bases de données relationnelles pour les autres aspects.
L'intégrité sémantique concerne la qualité de l'information stockée dans la base de données. Elle consiste à s'assurer que les données stockées sont cohérentes par rapport à leur signification. L'intégrité sémantique sera assurée lorsqu'il y aura respect de règles de cohérence ou contraintes d'intégrité sémantique.
Une contrainte d'intégrité sera définie comme une assertion qui doit être vérifiée par des données à des instants déterminés. Une base de données sera dite sémantiquement intègre si l'ensemble des contraintes d'intégrité (implicites et explicites) est respecté par les données de la base.
Plusieurs typologies de contraintes d'intégrité sont possibles, selon que l'on s'intéresse à leur signification, leur complexité ou aux types d'opérations qui les déclenchent [Bouzeghoub et al. 91]. Nous distinguerons pour notre part quatre grands types de contraintes d'intégrités prises en compte dans les bases de données relationnelles : les contraintes syntaxiques, les contraintes structurelles, les contraintes temporelles et enfin les contraintes générales.
Pour illustrer ces types de contraintes ainsi que leur prise en compte dans le relationnel, nous prendrons un exemple, celui présenté par le modèle Entité- Relation (MCD/MOD) et le MLD relationnel dérivé de la figure 13.28. Notons qu'un changement de dénomination et un préfixage des attributs ont été effectués afin de pouvoir faciliter certaines expressions du langage SQL.
 |
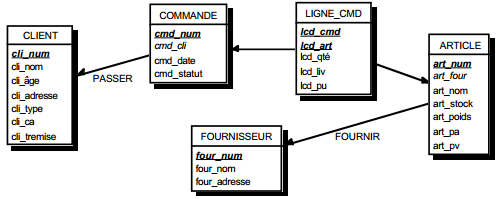 |
Schémas relationnels associés :
- table CLIENT (cli_num, cli_nom, cli_age, cli_adresse, cli_type, cli_ca, cli_tremise) ;
- table ARTICLE (art_num, art_nom, art_four, art_stock, art_poids, art_pa, art_pv) ;
- table COMMANDE (cmd_num, cmd_cli, cmd_date, cmd_statut) ;
- table LIGNE_CMD (lcd_cmd, lcd_art, lcd_qte, lcd_liv, lcd_pu) ;
- table FOURNISSEUR (four_num, four_nom, four_adresse).
Les attributs clés primaires sont représentés ici en gras et les attributs clés étrangères en italique.
Nous pouvons associer à cette base de données relationnelle les contraintes d'intégrité suivantes :
Des contraintes syntaxiques concernant le format des données (domaine de définition) :
- Définition d'un domaine de typage (exemple, dans la table CLIENT, l'attribut cli_num est de type CHAR(8)).
- Définition d'un domaine en plage de valeurs (exemple : dans la table CLIENT, l'attribut cli_age ne peut prendre que des valeurs comprises entre 0 et 120).
- Définition d'un domaine de variation défini en extension (exemple, dans la table CLIENT, cli_type peut prendre les valeurs Particulier, Administration, Entreprise ; dans la table Commande, cmd_statut peut prendre les valeurs Prévisionnelle, Validée, Urgente).
- Définition d'un domaine par défaut (exemple, dans la table COMMANDE, cmd_statut prend par défaut la valeur 'Prévisionnelle').
- Acceptation de la valeur nulle (exemple : dans la table CLIENT, cli_age accepte la valeur nulle — si le client est une personne morale, c'est-à-dire si l'attribut cli_type prend la valeur 'Administration' ou la valeur 'Entreprise').
Des contraintes structurelles concernant les règles de construction de :
- Clé de table, unicité de valeur pour une donnée (exemple, dans la table CLIENT, cli_num est clé primaire).
- Dépendances fonctionnelles (intrarelation, intratuple) (exemple, dans la table CLIENT, on a les dépendances cli_num -> cli_nom…).
- Contraintes référentielles (interrelation, intrarelation) (exemple, l'attribut cmd_cli de la table COMMANDE doit prendre comme valeur des valeurs de l'attribut cli_num de la table CLIENT…).
Des contraintes temporelles précisant des règles d'évolution des valeurs de certains attributs en fonction du temps ; par exemple, seulement vraies en fin de mois, seule une évolution croissante de la valeur d'une donnée est autorisée.
Dans notre exemple, considérons la table LIGNE_CMD. On doit avoir à tout instant pour tout tuple de cette table : lcd_qte >= lcd_liv signifiant que la quantité commandée est toujours supérieure ou égale à la quantité livrée.
Des contraintes d'intégrité générales spécifiant toujours la cohérence des données entre elles, mais n'entrant pas dans les catégories précédemment citées.
Dans notre exemple, on supposera que le prix unitaire de l'article cmd_pu de la table LIGNE_CMD ne peut être remisé à plus de 25 % du prix de vente de l'article (prix catalogue) art_pv défini dans la table ARTICLE.
III-C-3-b. Traitement des contraintes d'intégrité dans les SGBD Relationnels▲
Dans le développement d'applications autour d'une base de données relationnelle, les contraintes d'intégrité peuvent être prises en compte de différentes façons : soit de façon procédurale, soit de façon déclarative et ceci à différents niveaux soit au niveau du dictionnaire (ou schéma) ou au niveau de l'application (développé en langages de troisième (L3G) ou de quatrième génération (L4G)) comme l'illustre la figure 13.29.
 |
|
1 - Procédural au niveau des applications (L3G, L4G) |
Traitement procédural
On peut ainsi prendre en compte une contrainte d'intégrité de façon procédurale, c'est-à-dire en écrivant une procédure qui veillera au respect de celle-ci. Cette procédure sera définie dans les différents modules applications utilisant la base de données, que ces modules soient écrits en langages de troisième (L3G) ou de quatrième génération (L4G).
Traitement déclaratif au niveau des applications
Une autre façon de traiter ces contraintes est de les déclarer par des assertions. Ces assertions peuvent être définies, stockées, tout d'abord au niveau des applications, principalement au niveau des écrans, formes programmées en langages de troisième ou quatrième génération. Un intérêt par rapport à la solution précédente est qu'un écran, une forme, peut être utilisé par plusieurs modules applications ; la contrainte est alors partagée, ce qui limite les problèmes d'incohérences.
Traitement déclaratif au niveau du dictionnaire
Une dernière solution est de déclarer ces contraintes au niveau du dictionnaire, du schéma de la base de données relationnelle. Cette dernière solution est la plus puissante et ceci pour plusieurs raisons :
- Tout d'abord, la spécification des contraintes d'intégrité au niveau du dictionnaire permet d'alléger le travail de programmation. En effet, les contraintes ne sont définies qu'une seule fois et de façon centralisée. Le SGBD vérifie automatiquement chaque contrainte à chaque manipulation de données. Il envoie un éventuel message d'erreur à l'application que celle-ci peut alors gérer par un traitement spécifique. Plusieurs applications partageant les mêmes données partageront aussi les mêmes contraintes d'intégrité sur ces données.
- Ensuite, dans une architecture client-serveur, les contraintes spécifiées au niveau du dictionnaire de données conduiront à réduire le niveau du trafic sur le réseau, la prise en compte des contraintes étant réalisée au niveau du serveur et non au niveau de l'application s'exécutant sur le poste client.
Prendre en compte les contraintes d'intégrité au niveau du dictionnaire nécessite de disposer d'une part d'un langage déclaratif de spécification de ces contraintes et d'autre part que les SGBD soient effectivement capables de prendre en compte, de façon opérationnelle (performance), ces contraintes ainsi déclarées. Jusqu'à présent, très peu de contraintes d'intégrité pouvaient être « assimilées » de façon déclarative par les SGBD relationnels. La norme SQL-92 (ou SQL-2) [Marée & Ledant 94] comme nous le verrons plus loin, constitue une avancée significative dans la spécification déclarative des contraintes.
III-C-3-c. Vérification des contraintes d'intégrité▲
La plupart des contraintes d'intégrité déclarées sont vérifiées immédiatement et automatiquement. Ainsi, dès qu'une requête de mise à jour (exprimée en langage SQL) est exécutée par une application, les contraintes d'intégrité sont vérifiées par le système et si une contrainte n'est pas vérifiée, la requête est défaite.
La vérification de certaines contraintes peut être différée, par exemple à la fin d'une transaction. Rappelons qu'une transaction est un ensemble de requêtes SQL qui fait passer la base de données d'un état cohérent à un autre état cohérent. Entre ces états cohérents, il existe des états transitoires de la base de données qui sont incohérents. La vérification des contraintes est faite à la fin de la transaction en cours, pour vérifier que l'état dans laquelle celle-ci a laissé la base de données est effectivement cohérent.
Dans SQL-92, il est possible de spécifier pour chaque contrainte déclarée son mode de prise en compte : immédiat ou différé à la fin de la transaction en cours (NOT DEFERRABLE ou DEFERRABLE). Ce mode peut être fixé initialement et changer ensuite (INITIALLY DEFERRED\IMMEDIATE).
Certaines contraintes d'intégrité, assez complexes, traitées de façon procédurale ne sont pas déclenchées automatiquement par le SGBD, mais par le programmeur. Celui-ci peut programmer dans une application le déclenchement de la contrainte dès la survenance d'un événement donné. Le programmeur peut alors avoir recours à un mécanisme puissant disponible dans de nombreux SGBD, le « trigger ». Ainsi, pour chaque contrainte complexe à vérifier sur apparition d'un événement, on créera un trigger, consistant en une procédure compilée, cataloguée dans le dictionnaire, qui s'exécutera automatiquement chaque fois que l'événement déclenchant associé se produira. La norme SQL-92 ne normalise pas l'expression de ces triggers ; SQL-3, la prochaine norme dont la sortie est prévue pour 96, devrait la normaliser.
Enfin, notons qu'avant de prendre en compte une nouvelle contrainte d'intégrité, il faut s'assurer de sa conformité avec :
- le schéma de la base ; c'est-à-dire que tout attribut ou table cités dans la contrainte d'intégrité appartient bien au schéma ;
- les données de la base ; il faut s'assurer que toutes les données déjà existantes dans la base respectent la nouvelle contrainte d'intégrité ;
- les autres contraintes d'intégrité ; il faut s'assurer qu'il n'y a pas de contradiction, de redondances…
III-C-3-d. Représentation et expression des contraintes d'intégrité▲
Il est possible d'exprimer les contraintes d'intégrité en logique des prédicats du premier ordre. Très tôt, des langages plus adaptés ont aussi été proposés comme le langage LDC [Simon 84 - INRIA-Sabrina], le langage RAISIN [Stonebraker 85]. Comme nous l'avons déjà évoqué, l'expression des contraintes d'intégrité commence à être normalisée dans le langage SQL-2. Nous allons voir dans ce qui suit comment des contraintes, précisées de façon implicite ou explicite dans un modèle conceptuel de données en formalisme Entité-Relation, peuvent être traitées dans le modèle relationnel.
Nous illustrerons ceci au travers de l'exemple défini plus haut, auquel peut être associé le schéma relationnel suivant en SQL-92 (figure 12-30 - afin de mettre en valeur les termes du langage SQL, ils sont écrits en majuscules, alors que les désignations des tables et des attributs sont en minuscules) :
CREATE TABLE Client
(cli_num CHAR(8) PRIMARY KEY
CONSTRAINT PK_CLIENT,
cli_nom CHAR(25) UNIQUE,
CONSTRAINT UNIQUE_CLIENT,
cli_age INTEGER CHECK (cli_age > 0 AND cli_age < 120),
CONSTRAINT AGE_CLIENT,
cli_adresse VARCHAR(80),
cli_type VARCHAR(16) DEFAULT 'Particulier',
cli_ca INTEGER DEFAULT 0
cli_tremise INTEGER NOT NULL);
CHECK (cli_type IN ('Particulier', 'Administration', 'Entreprise'))
CONSTRAINT TYPE_CLIENT);
CREATE TABLE Article
(art_num CHAR(8) DEFAULT 0 PRIMARY KEY
CONSTRAINT PK_ARTICLE,
art_nom VARCHAR(25) NOT NULL,
art_four CHAR(8) REFERENCES Fournisseur
ON UPDATE CASCADE
ON DELETE SET NULL
CONSTRAINT FK_FOURNISSEUR
art_stock INTEGER DEFAULT 0 CHECK (art_stock > 0)
CONSTRAINT STOCK_ARTICLE,
art_poids NUMERIC (8,1),
art_pa INTEGER NOT NULL,
art_pv INTEGER NOT NULL,
CHECK (art_pv > art_pa / 0.8)
CONSTRAINT PVPA_ARTICLE);
CREATE TABLE Commande
(cmd_num CHAR(8) PRIMARY KEY
CONSTRAINT PK_COMMANDE,
cmd_cli CHAR(8) NOT NULL REFERENCES
Client
ON UPDATE CASCADE
ON DELETE NO ACTION
CONSTRAINT FK_CLIENT
cmd_date DATE NOT NULL,
cmd_statut VARCHAR(16) DEFAULT 'Prévisionelle'
CHECK (cmd_statut IN ('Prévisionnelle', 'Validée', 'Urgente')
CONSTRAINT STATUT_COMMANDE);
CREATE TABLE Ligne_cmd
(lcd_art CHAR(8) NOT NULL,
lcd_cmd INTEGER NOT NULL,
lcd_qte INTEGER NOT NULL,
lcd_liv INTEGER DEFAULT 0,
lcd_pu INTEGER NOT NULL,
PRIMARY KEY (lcd_cmd, lcd_art)
CONSTRAINT PK_LIGNCDE
FOREIGN KEY (lcd_cmd) REFERENCES Commande
ON UPDATE CASCADE
ON DELETE CASCADE
CONSTRAINT FK_COMMANDE
FOREIGN KEY (lcd_art) REFERENCES Article
ON UPDATE CASCADE
ON DELETE NO ACTION
CONSTRAINT FK_ARTICLE
CHECK (lcd_pu >=0.75 *
(SELECT art_pv FROM Article
WHERE art_num = lcd_art))
CONSTRAINT PU_LIGNCDE);
CREATE TABLE Fournisseur
(four_num CHAR(8) PRIMARY KEY
CONSTRAINT PK_FOURNISSEUR,
four_nom CHAR(25) UNIQUE,
CONSTRAINT UNIQUE_FOURNISSEUR,
four_adresseVARCHAR(80);Prise en compte des contraintes d'intégrité
Comme nous l'avons déjà vu au chapitre 7Chapitre 7 Modélisation conceptuelle des données, dans un modèle Entité-Relation (MCD/MOD) peuvent être spécifiés (explicitement ou implicitement) plusieurs types de contraintes : contraintes intraentité, contraintes intrarelation, contraintes d'intégrité générales, de stabilité, de transition, d'identifiant relatif et enfin contraintes portant sur la participation d'une entité à plusieurs relations. Il s'agit maintenant de prendre en compte ces contraintes au niveau logique, dans un MLD relationnel, c'est-à-dire de les spécifier dans le langage SQL.
III-C-3-e. Contraintes intraentité ▲
Dans SQL-92, on dispose d'un certain nombre de clauses permettant de déclarer ce type de contraintes.
III-C-3-f. Contraintes d'intégrité d'entité : clause PRIMARY KEY▲
Une entité du MCD se transforme en une table du MLD relationnel. L'identifiant de l'entité devient la clé primaire de la table logique associée. Ainsi, dans le MLD relationnel de l'exemple ci-dessus, cli_num (n° client), art_num (n° article) et cmd_num (n° commande) sont les clés primaires des tables Client, Article et Commande.
La contrainte d'intégrité d'entité traduit qu'une table possède une clé primaire. Lorsque la clé primaire est constituée d'un seul attribut, la clause PRIMARY KEY dans la définition de cet attribut le déclare comme clé primaire :
CREATE TABLE Article
(art_num CHAR(8) DEFAULT 0 PRIMARY KEY
CONSTRAINT PK_ARTICLE,
…Lorsque la clé primaire est constituée de plusieurs attributs (clé primaire composée), la clause est spécifiée après la définition des attributs de la table :
CREATE TABLE Ligne_cmd
(lcd_cmd INTEGER NOT NULL,
lcd_art CHAR(8) NOT NULL,
…
PRIMARY KEY (lcd_cmd, lcd_art)
CONSTRAINT PK_LIGNCDE
…III-C-3-g. Valeurs « obligatoires » : clause NOT NULL▲
En spécifiant la clause NOT NULL dans la définition d'un attribut, on impose que cet attribut possède une valeur autre que la valeur « nulle » (rappelons qu'un attribut à la valeur « nulle » s'il n'a pas de valeur). Par exemple dans la commande CREATE TABLE de la table article, la clause NOT NULL associée à l'attribut art_nom précise que cet attribut ne peut rester indéterminé :
CREATE TABLE Article …
art_nom VARCHAR(25) NOT NULL, …III-C-3-h. Valeurs par défaut : clause DEFAULT▲
La clause DEFAULT permet de spécifier, lors de la création d'une table, une valeur par défaut pour l'un des attributs de cette table. Par exemple, dans la commande CREATE TABLE de la table article, la clause DEFAULT associée à l'attribut cli_type précise que cet attribut aura comme valeur par défaut la valeur « Particulier » :
CREATE TABLE Client
…
cli_type VARCHAR(16) DEFAULT 'Particulier',
…III-C-3-i. Valeurs uniques : clause UNIQUE▲
Lors de la création d'une table, la clause UNIQUE permet de spécifier que, pour un attribut donné de cette table, deux tuples de la table ne peuvent prendre la même valeur. Ceci revient à spécifier les clés dites « candidates » ou encore clés « alternatives » de la table, clés qui n'ont pas été choisies comme clés primaires, mais qui auraient pu l'être. Par exemple, dans la commande CREATE CLIENT de la table client, la clause UNIQUE associée à l'attribut cli_nom précise que deux clients ne peuvent avoir un même nom (hypothèse arbitraire) :
CREATE TABLE Client
…
cli_nom CHAR(25) UNIQUE,
CONSTRAINT UNIQUE_CLIENT
…III-C-3-j. Domaine de valeurs défini en extension : clause CHECK▲
La clause CHECK permet de spécifier une contrainte qui doit être vérifiée à tout moment par les tuples de la table. Un nombre quelconque de telles clauses peuvent être placées dans la définition d'une table. L'exemple suivant indique que l'attribut cli_type de la table Client ne peut prendre qu'une des valeurs suivantes :
CREATE TABLE Client
…
CHECK (cli_type IN ('Particulier', 'Administration, 'Entreprise'))
CONSTRAINT TYPE_CLIENT);
…III-C-3-k. Contraintes intrarelation - contraintes d'intégrité référentielle : FOREIGN KEY▲
Nous avons vu qu'une relation conceptuelle conduisait dans le modèle relationnel à l'introduction de clés étrangères. Rappelons que, dans le modèle relationnel, une telle clé est un attribut ou une combinaison d'attributs d'une table dont les valeurs doivent correspondre à celles prises par une clé primaire d'une autre table. On appelle contrainte d'intégrité référentielle la contrainte garantissant que toute valeur d'une clé étrangère est bien égale à une valeur de clé primaire.
Lorsqu'une clé étrangère est constituée d'un seul attribut, elle est précisée directement lors de la définition de cet attribut. Ainsi, dans l'exemple précédent, on a à exprimer les contraintes d'intégrité référentielle suivantes : l'attribut cmd_cli, clé étrangère dans la table Commande (table qui référence), réfère à cli_num, clé primaire de la table Client (table référencée) :
CREATE TABLE Commande
…
cmd_cli CHAR(8) NOT NULL REFERENCES Client
CONSTRAINT FK_CLIENT
…Lorsqu'une clé étrangère est constituée de plusieurs attributs, elle doit être précisée par la clause FOREIGN KEY :
CREATE TABLE Ligne_cmd
lcd_art CHAR(8) NOT NULL,
(lcd_cmd INTEGER NOT NULL,
…
FOREIGN KEY (lcd_cmd) REFERENCES Commande
CONSTRAINT FK_COMMANDE
FOREIGN KEY (lcd_art) REFERENCES Article
CONSTRAINT FK_ARTICLE
…III-C-3-l. Contraintes de modification ou de suppression d'une clé étrangère▲
SQL-92 a recensé quatre actions possibles pouvant être précisées au niveau de la définition des clés étrangères au niveau des tables « enfant », en cas de modification (ON UPDATE) ou de suppression (ON DELETE) de la valeur de la clé primaire correspondante dans la table « parent ».

Ces options sont les suivantes : CASCADE, NO ACTION, SET DEFAULT et SET NULL. Voyons en détail chacune de ces options :
-
CASCADE :
- en cas de mise à jour - ON UPDATE -, les tuples correspondants de la table « enfant » sont aussi mis à jour,
- en cas de suppression - ON DELETE -, il y a aussi suppression des tuples correspondants de la table « enfant » ;
- NO ACTION : les changements effectués sur la clé primaire de la table « parent » sont refusés et le SGBD retourne une erreur. Cette clause correspond à l'ancienne clause RESTRICT. NO ACTION est une clause souvent utilisée, par laquelle on refuse la suppression ou la mise à jour d'une clé primaire d'une table « parent » possédant des « enfants » ;
- SET DEFAULT : la modification demandée est permise et la valeur de la clé étrangère de la table « enfant » est mise à la valeur par défaut spécifiée (cf. clause DEFAULT) dans tous les tuples concernés ;
- SET NULL : la modification demandée est permise et la valeur de la clé étrangère de la table « enfant » est mise à NULL dans tous les tuples concernés. Notons que pour utiliser cette option, NOT NULL ne peut avoir été spécifié pour chacun des composants de la clé étrangère.
Dans notre exemple, les actions précisées dans la table Commande relativement à la clé étrangère cmd_cli sont les suivantes :
CREATE TABLE Commande
…
cmd_cli CHAR(8) NOT NULL REFERENCES Client
ON UPDATE CASCADE
ON DELETE NO ACTION
CONSTRAINT FK_CLIENT
…Cette déclaration signifie que :
- ON UPDATE CASCADE : toute modification d'une valeur de la clé primaire de la table Client, c'est-à-dire l'attribut cli_num, conduira à une mise à jour automatique de la clé étrangère cmd_clt dans tous les tuples concernés de la table Commande ;
- ON DELETE NO ACTION : toute suppression d'une valeur de la clé primaire de la table Client, c'est-à-dire de l'attribut cli_num, sera refusée.
Toujours dans notre exemple, les actions précisées dans la table Article relativement à la clé étrangère art_four sont les suivantes :
CREATE TABLE Article
…
art_four CHAR(8) REFERENCES Fournisseur
ON UPDATE CASCADE
ON DELETE SET NULL
CONSTRAINT FK_FOURNISSEUR
…Cette déclaration signifie que :
- ON UPDATE CASCADE : toute modification d'une valeur de la clé primaire four_num de la table FOURNISSEUR, conduira à une mise à jour automatique de la clé étrangère art_four dans tous les tuples concernés de la table ARTICLE ;
- ON DELETE SET NULL : toute suppression d'une valeur de la clé primaire de la table FOURNISSEUR, et donc d'un fournisseur donné, impliquera la mise à NULL de la clé étrangère art_four dans tous les tuples de la table ARTICLE qui étaient fournis par ce fournisseur. Il n'y a ainsi plus de fournisseur pour ces articles.
Nous aurions pu définir une valeur par défaut de cette clé étrangère art_four, par exemple la valeur « inconnu », et nous aurions alors pu utiliser l'option SET DEFAULT :
CREATE TABLE Article
…
art_four CHAR(8) DEFAULT 'inconnu' REFERENCES Fournisseur
ON UPDATE CASCADE
ON DELETE SET DEFAULT
CONSTRAINT FK_FOURNISSEUR
…Toute suppression d'une valeur de la clé primaire de la table FOURNISSEUR, et donc d'un fournisseur donné, impliquera la mise à la valeur « inconnu » de la clé étrangère art_four dans tous les tuples de la table ARTICLE qui étaient fournis par ce fournisseur.
III-C-3-m. Contraintes référentielles dans la transformée de relation conceptuelle▲
Transformée d'une relation binaire fonctionnelle (cardinalité (1,1))
La transformée d'une relation binaire fonctionnelle présentant une cardinalité (1,1) conduira à spécifier dans la définition de la table associée à l'entité du côté de la cardinalité (1,1) et au niveau de la déclaration de la clé étrangère les options suivantes :
- NOT NULL ;
- ON UPDATE CASCADE ou NO ACTION (CASCADE étant le plus le plus probable) ;
- ON DELETE CASCADE ou NO ACTION (NO ACTION étant le plus le plus probable).
Ainsi, dans notre exemple (cf. figure 13.29), la relation PASSER entre les entités CLIENT et COMMANDE est du type considéré. Sa transformée en relationnel conduit à définir dans la table COMMANDE la clé étrangère cmd_cli de la façon suivante :
CREATE TABLE Commande
…
cmd_cli CHAR(8) NOT NULL REFERENCES Client
CONSTRAINT COMMANDE_CLIENT
…Transformée d'une relation binaire fonctionnelle (cardinalité (0,1))
La transformée d'une relation binaire fonctionnelle présentant une cardinalité (0,1) conduira à spécifier dans la définition de la table associée à l'entité du côté de la cardinalité (0,1) et au niveau de la déclaration de la clé étrangère des options suivantes :
- pas d'option NOT NULL ou une option DEFAULT ;
- ON UPDATE CASCADE ou NO ACTION (CASCADE étant le plus le plus probable) ;
- ON DELETE SET NULL ou SET DEFAULT (SET NULL étant le plus le plus probable).
Dans notre exemple (cf. figure 13.29), la relation FOURNIR entre les entités FOURNISSEUR et ARTICLE est du type considéré. Sa transformée en relationnel conduit à définir dans la table ARTICLE la clé étrangère art_four de la façon suivante :
CREATE TABLE Article
…
art_four CHAR(8) REFERENCES Fournisseur
ON UPDATE CASCADE
ON DELETE SET NULL
CONSTRAINT FK_FOURNISSEUR
…Transformée d'une relation binaire (*,n)-(*,n), ternaire ou supérieure
La transformée d'une relation binaire (*,n)-(*,n), ou de toute relation ternaire ou supérieure conduira à la création d'une table spécifique à la relation dont la clé primaire composée sera constituée des clés étrangères référant aux tables associées aux entités reliées par la relation. Dans la définition de cette table associée à la relation et au niveau de la déclaration de la clé primaire composée des clés étrangères, on aura les options suivantes :
- NOT NULL ;
- ON UPDATE CASCADE ou NO ACTION (CASCADE étant le plus le plus probable) ;
- ON DELETE CASCADE ou NO ACTION (CASCADE étant le plus le plus probable).
Dans notre exemple (cf. figure 13.29), la relation LIGNE_CMD (ligne de commande) entre les entités COMMANDE et ARTICLE est du type considéré. Sa transformée en relationnel est la table LIGNE_CMD dans laquelle les clés primaires et étrangères sont définies ainsi :
CREATE TABLE Ligne_cmd
(lcd_art CHAR(8) NOT NULL,
lcd_cmd INTEGER NOT NULL,
…
PRIMARY KEY (lcd_cmd, lcd_art) CONSTRAINT PK_LIGNCDE
FOREIGN KEY (lcd_cmd) REFERENCES Commande
ON UPDATE CASCADE
ON DELETE CASCADE
CONSTRAINT FK_COMMANDE
FOREIGN KEY (lcd_art) REFERENCES Article
ON UPDATE CASCADE
ON DELETE NO ACTION
CONSTRAINT FK_ARTICLE
…III-C-3-n. Dépendances fonctionnelles dans une relation n-aire▲
Dans le cas de dépendances fonctionnelles n'englobant pas la totalité de la collection, il est conseillé de décomposer la relation comme nous l'avons vu précédemment.
Dans le cas de dépendances fonctionnelles englobant la totalité de la collection, la contrainte conceptuelle se traduit par la spécification de clés primaires et étrangères dans la table associée à la relation conceptuelle. Soit à exprimer la contrainte suivante :
Un client ne s'approvisionne pour un article donné que dans un magasin donné.
Soit : Client X Article -> Magasin. On a alors les schémas de la figure 13.26.
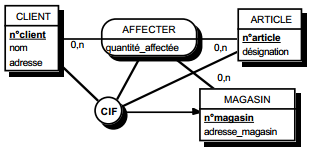 |
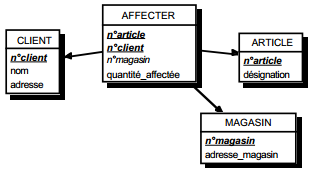 |
Schémas relationnels associés à la figure 13.31 :
- table CLIENT (n°client, nom, adresse) ;
- table ARTICLE (n°article, désignation) ;
- table MAGASIN (n°magasin, adresse_magasin) ;
- table AFFECTER (n°client, n°article, n°magasin, quantité_affectée)
Comme le précise le modèle relationnel, la dépendance fonctionnelle sera traduite ici par la définition, dans la table Affecter, des trois clés étrangères, cli_num, art_num, mag_num, et de la clé primaire composée (cli_num, art_num).
Lors de la création de la table Affecter, il s'agira, par les options FOREIGN KEY et NOT NULL, de préciser les clés primaires et étrangères de la table :
CREATE TABLE Affecter
(cli_num CHAR(5) NOT NULL,
(art_num CHAR(5) NOT NULL,
(mag_num CHAR(5) NOT NULL…)
PRIMARY KEY (cli_num, art_num)
CONSTRAINT PRIMARY_AFFECTER
FOREIGN KEY (cli_num) REFERENCES Client ;
CONSTRAINT AFFECTER_CLIENT
FOREIGN KEY (art_num) REFERENCES Article ;
CONSTRAINT AFFECTER_ARTICLE
FOREIGN KEY (mag_num) REFERENCES Magasin ;
CONSTRAINT AFFECTER_MAGASINIII-C-3-o. Contraintes d'intégrité générales▲
Il s'agit principalement d'exprimer des contraintes sur la prise de valeurs de propriétés en fonction de valeurs déjà prises par d'autres propriétés de la même ou d'autres entités ou relations. Ces contraintes se traduisent par des contraintes d'intégrité générales sur les attributs du MLD relationnel. On peut distinguer deux grands types de contraintes d'intégrité générales, selon que leur activation soit ou non associée à l'apparition d'un événement.
III-C-3-p. Contraintes non associées à un événement▲
Ces contraintes sont assez bien prises en compte au travers de la déclaration d'une clause CHECK avec ou sans création d'une ASSERTION. Ainsi, dans l'exemple ci-dessus, soit à exprimer la contrainte d'intégrité générale suivante :
- CI : le prix unitaire de l'article lcd_pu de la table LIGNE_CMD ne peut être remisé à plus de 25 % du prix de vente de l'article (prix catalogue) art_pv défini dans la table ARTICLE.
Cette contrainte peut être traitée par la clause CHECK suivante déclarée dans la table LIGNE_CMD :
CREATE TABLE Ligne_cmd
…
CHECK (lcd_pu >=0.75 *
(SELECT art_pv FROM Article
WHERE art_num = cmd_art))
CONSTRAINT PU_LIGNCDE);On peut aussi prendre en compte cette contrainte en déclarant une assertion spécifique. Une assertion est une contrainte non rattachée à une table en particulier, en conséquence souvent utilisée pour spécifier une contrainte d'intégrité définie sur plusieurs tables. La contrainte précédente est alors déclarée ainsi :
…
CREATE ASSERTION PU_PV
CHECK (NOT EXISTS
(SELECT * FROM Ligne_cmd
WHERE lcd_pu < 0.75 *
(SELECT art_pv FROM Article
WHERE art_num = lcd_art )));III-C-3-q. Contraintes associées à un événement : triggers▲
Certaines contraintes d'intégrité, souvent assez complexes, doivent être exécutées dès l'apparition d'un événement donné. Jusqu'à présent, ces contraintes étaient traitées de façon procédurale par le programmeur. Dans de nombreux SGBD relationnels commercialisés, le programmeur peut dans son application déclencher la contrainte dès la survenance d'un événement par la création d'un trigger.
Pour chaque contrainte complexe à vérifier sur l'apparition d'un événement, on créera ainsi un trigger, consistant en une procédure compilée, cataloguée dans le dictionnaire du SGBD, et qui s'exécutera automatiquement chaque fois que l'événement déclenchant associé se produira. Notons que certains SGBD du marché permettent de déclarer aussi des triggers au niveau de l'application et non du dictionnaire. Nous ne nous intéresserons ici qu'aux triggers déclarés au niveau du dictionnaire.
La norme SQL-2 ne normalise pas l'expression de ces triggers ; SQL-3 devrait le faire. Néanmoins, une syntaxe générale pourrait être :
CREATE TRIGGER nom_trigger
EVENEMENT ON nom_table
WHEN (condition à vérifier)
- INSTRUCTIONS -
FOR EACH ROW / STATEMENTLa clause EVENEMENT
Elle permet de préciser le contexte de déclenchement du trigger. Ce contexte précise tout d'abord le type d'événement concerné, soit une insertion (INSERT), une mise à jour (UPDATE) ou une suppression (DELETE). Il doit ensuite indiquer si le trigger doit être déclenché avant (BEFORE) cet événement, ou après (AFTER). La clause EVENEMENT peut en conséquence prendre une des six valeurs suivantes : BEFORE INSERT, AFTER INSERT, BEFORE UPDATE, AFTER UPDATE, BEFORE DELETE, AFTER DELETE.
La clause WHEN
Elle permet de restreindre encore les circonstances d'exécution du trigger en précisant une condition portant par exemple sur les valeurs de certains attributs de la table.
La clause FOR EACH ROW
Elle précise que le trigger devra être exécuté pour chaque insertion, mise à jour ou suppression d'un tuple de la table concernée. La clause FOR EACH STATEMENT, clause par défaut, spécifie au contraire que le trigger ne devra être déclenché qu'une seule fois pour tous les tuples concernés.
Le trigger peut, en partie action, spécifier un ensemble d'instructions INSTRUCTIONS. Certains SGBD ont défini un mini langage structuré (IF, THEN, ELSE…) permettant d'enchaîner des ordres SQL en consultation et en mise à jour sur les tables.
Pour illustrer l'utilisation de triggers, supposons que nous souhaitions, dans notre exemple, vérifier lors d'un ajout d'une nouvelle ligne de commande à une commande donnée, que le montant de cette commande, l'attribut cmd_montant de la table COMMANDE, soit bien égal à la somme des montants associés à chacune des lignes de commande de la commande, montant calculé comme le produit de la quantité commandée d'articles par un prix unitaire (lcd_qte * lcd_pu).
Dans le SGBD Oracle, un tel trigger s'exprimerait ainsi :
CREATE TRIGGER Calcul_montant_si_ajout
AFTER INSERT ON ligne_cmd
BEGIN
UPDATE Commande
SET cmd_montant = cmd_montant + :new.lcd_qte * :new.lcd_pu
WHERE cmd.num = :new.lcd_cmd;
END;Les instructions comprises entre le BEGIN et le END sont exprimées en PL/SQL, langage procédural proposé dans Oracle. On notera l'usage des variables : new et : old, la variable : new étant la variable associée à un nouveau tuple courant inséré (INSERT) ou mis à jour (UPDATE) et la variable : old étant associée à l'ancien tuple mis à jour (UPDATE) ou supprimé (DELETE).
III-C-3-r. Contraintes de stabilité▲
Les contraintes évoquées jusqu'ici sont de type statique. Comme nous l'avons vu précédemment, il est possible de spécifier sur un MCD des contraintes permettant d'exprimer la stabilité des états du modèle de données. Elles concernent principalement :
- les propriétés stables ;
- les pattes définitives et verrouillées.
Il est souvent difficile de traiter ce type de contraintes de façon déclarative.
III-C-3-s. Pattes définitives et verrouillées▲
Comme nous l'avons vu au chapitre 7Chapitre 7 Modélisation conceptuelle des données, une patte de relation est définitive (D) si une occurrence de la relation ne peut être supprimée que par et seulement par la suppression simultanée de l'occurrence correspondante de l'entité impliquée dans la patte de la relation.
De même, une patte de relation est verrouillée (V) si, étant donné une occurrence de l'entité reliée par cette patte, toutes les occurrences de la relation dans lesquelles cette occurrence de l'entité intervient, sont créées en même temps que l'occurrence de l'entité. Ultérieurement, on ne pourra ni ajouter ni supprimer une occurrence de la relation impliquant cette occurrence d'entité.
Notons que l'option Verrouillée correspond à l'option Définitive à laquelle, pour une même occurrence d'entité, on interdit la possibilité de rajouter une nouvelle occurrence de relation (soit V = D + interdiction (n+1)).
La prise en compte de pattes définitives et verrouillées au niveau relationnel pourra se faire en utilisant les options de déclaration des clés étrangères vues précédemment. Soit l'exemple suivant :
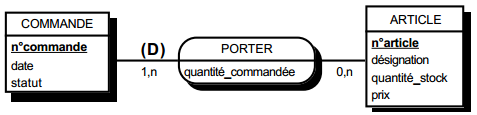 |
 |
Schémas relationnels associés à la figure 13.31b :
- table COMMANDE (n°commande, date, statut) ;
- table PORTER (n°article, n°commande, quantité_commandée) ;
- table ARTICLE (n°article, désignation, quantité_stock, prix).
La prise en compte au niveau relationnel de pattes définitives (D) et verrouillées (V) pourra être faite en affectant judicieusement les options de suppression/modification vues précédemment. Ainsi, pour notre exemple avec patte définitive, on choisira les options suivantes pour les clés étrangères de la table « enfant » PORTER :
Options relatives à la clé étrangère n°commande, référant à la table « parent » COMMANDE (patte définitive - D) :
- ON DELETE CASCADE
- ON UPDATE CASCADE
Options relatives à la clé étrangère n°article, référant à la table « parent » ARTICLE :
- ON DELETE NO ACTION
- ON UPDATE NO ACTION
III-C-3-t. Propriétés stables▲
Les triggers permettent aussi de traiter la plupart de ces contraintes de stabilité. On pourrait ainsi envisager un trigger assurant la stabilité de l'attribut cmd_date de la table COMMANDE (correspondant à la propriété stable date de l'entité COMMANDE).
Dans le SGBD Oracle, un tel trigger s'exprimerait ainsi :
CREATE TRIGGER Stable_cmd_date
AFTER INSERT ON cmd_date OF Commande
ON EACH ROW
BEGIN
IF :new.cmd_date != :old.cmd_date
raise_application_error (-20001, 'Date non modifiable ');
END IF;
END;Remarques :
- Dans le traitement par trigger de la contrainte de stabilité ci-dessus, « != » exprime la négation dans le PL-SQL d'Oracle et raise_application_error permet d'affecter un code d'erreur pouvant être ensuite traité, ainsi qu'un message à l'utilisateur.
- Dans la plupart des SGBD, il est possible d'interdire une mise à jour d'un attribut à un groupe d'utilisateurs. Un usage des commandes SQL « Grant » et « Revoke » permet de gérer de telles autorisations.
Enfin, certaines de ces contraintes ne pourront être prises en compte que de façon procédurale dans le développement des applications, en L3G ou L4G.
III-C-3-u. Identifiant relatif▲
Rappelons qu'au niveau conceptuel, l'identifiant relatif ne peut s'utiliser que pour une entité type qui est émetteur d'une dépendance fonctionnelle obligatoire vers l'entité type « maître », c'est-à-dire une cardinalité (1,1), et si la relation qui le rattache à l'entité maître est verrouillée (contrainte de stabilité (V)).
Dans l'exemple déjà rencontré dans le chapitre 7Chapitre 7 Modélisation conceptuelle des données, l'identifiant relatif identifie une tranche par son ordre (ou rang) dans le projet (cf. figure 13.32). Dans le passage au relationnel, lors de la création de la table TRANCHE, il s'agira, par les options FOREIGN KEY et NOT NULL, de préciser les clés primaires et externes de la table :
CREATE TABLE Tranche
(n°projet CHAR(5) NOT NULL,
n°ordre CHAR(5) NOT NULL…
PRIMARY KEY (n°projet, n°ordre) …
FOREIGN KEY (n°projet) REFERENCES Projet
ON UPDATE CASCADE
ON DELETE CASCADE
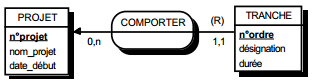 |
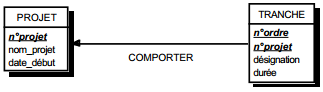 |
Schémas relationnels associés à la figure 13.32 :
- table PROJET (n°projet, nom_projet, date_début) ;
- table TRANCHE (n°projet, n°ordre, désignation, durée).
III-C-3-v. Propriétés à valeurs codées▲
Comme nous l'avons vu au chapitre 7Chapitre 7 Modélisation conceptuelle des données, il s'agit de propriétés d'entité dont la valeur s'exprime par un code (numérique ou alphanumérique, mnémonique ou non) associé à un libellé explicatif. Nous avons vu qu'en modélisation conceptuelle, il était préférable de modéliser ce type de propriété comme les autres propriétés classiques, c'est-à-dire de les rattacher à leur entité naturelle (sans tenir compte de l'aspect code + libellé).
Soit par exemple une entité PERSONNE caractérisée par une propriété à valeurs codées « civilité » telle que :
-
Civilité :
- 1 = Monsieur,
- 2 = Madame,
- 3 = Mademoiselle.
Cette propriété à valeurs codées doit être spécifiquement prise en compte lors du passage au niveau logique. Elle conduit à la création d'une table dite « table de références », comme l'illustre la figure suivante :
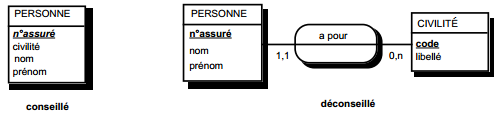 |
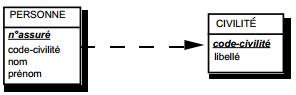 |
Les schémas relationnels associés à cette modélisation logique sont :
- table PERSONNE (n°assuré, code-civilité, nom, prénom) ;
- table CIVILITE (code-civilité, libellé).
Notons que l'implémentation réelle du lien relationnel n'est pas toujours nécessaire. Si celle-ci est implémentée, l'attribut code civilité de la table PERSONNE est déclaré clé étrangère et les options de mise à jour doivent être judicieusement choisies.
III-C-3-w. Contraintes sur la participation d'une entité à plusieurs relations - Exclusion de participation d'une entité à plusieurs relations▲
On l'exprime au niveau conceptuel par une contrainte X (voir « Contraintes intrarelationContraintes intrarelation » du chapitre 7). Dans l'exemple suivant, par rapport à l'entité article, les relations Acheter et Approvisionner sont mutuellement exclusives, c'est-à-dire qu'un article donné ne peut être à la fois acheté à un fournisseur et approvisionné auprès d'une unité de production (cf. figure 13.34) :
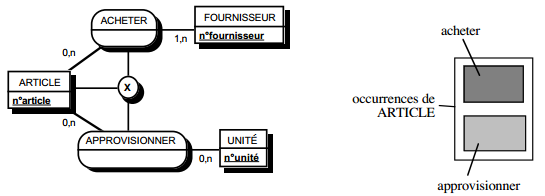 |
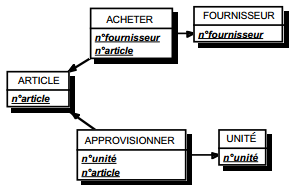 |
Schémas relationnels associés à la figure 13.34 :
- table ARTICLE (n°article…) ;
- table ACHETER (n°article, n°fournisseur…) ;
- table FOURNISSEUR (n°fournisseur…) ;
- table APPROVISIONNER (n°article, n°unité) ;
- table UNITÉ (n°unité…).
Pour exprimer la contrainte d'exclusion X en SQL-2, on déclarera l'assertion CX suivante :
CREATE TABLE Article
CREATE TABLE Acheter
CREATE TABLE Fournisseur
CREATE TABLE Approvisionner
CREATE TABLE Unité
…
CREATE ASSERTION CX
CHECK (NOT EXISTS
(SELECT * FROM Acheter WHERE n°article IN
(SELECT n°article FROM Approvisionner))
UNION
(SELECT * FROM Approvisionner WHERE n°article IN
(SELECT n°article FROM Acheter ));
…On pourra aussi pour exprimer la contrainte d'exclusion (X) par les deux triggers Oracle suivants :
CREATE TRIGGER Exclusion_acheter_approvisionner
BEFORE INSERT ON Acheter
ON EACH ROW
DECLARE
nb_article_approvisionner number;
BEGIN
SELECT COUNT(*) INTO nb_article_approvisionner FROM Approvisonner
WHERE n°article = :new.n°article;
IF nb_article_approvisionner > 0 THEN
raise_application_error (-20002, 'Article N° ', :new.n°article,
' est un article d approvisionnement' ));
END IF;
END;
…
CREATE TRIGGER Exclusion_approvisionner_acheter
BEFORE INSERT ON Approvisionner
ON EACH ROW
DECLARE
nb_article_acheter number;
BEGIN
SELECT COUNT(*) INTO nb_article_acheter FROM Acheter
WHERE n°article = :new.n°article;
IF nb_article_acheter > 0 THEN
raise_application_error (-20003, 'Article N° ', new.n°article,
' est un article à acheter' ));
END IF;
END;
…III-C-3-x. Simultanéité de participations d'une entité à plusieurs relations (ET LOGIQUE)▲
Toute occurrence de l'entité type participe de façon simultanée à deux (ou plusieurs) relations types. On l'exprime au niveau conceptuel par une contrainte S (voir chapitre 7 « Contraintes sur la participation d'une entité à plusieurs relations participation d'une entité à plusieurs relationsContraintes sur la participation d'une entité à plusieurs relations »).
Par exemple, une Commande portant sur des Articles est obligatoirement destinée à un Client (cf. figure 13.35).
 |
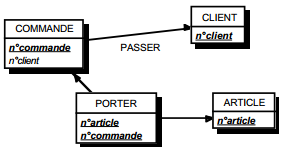 |
Avec les schémas relationnels suivants associés à la figure 13.35 :
- table COMMANDE (n°commande, n°client…) ;
- table CLIENT (n°client…) ;
- table ARTICLE (n°article…) ;
- table PORTER (n° article, n°commande).
Pour exprimer la contrainte d'exclusion S en SQL-2, on déclarera l'assertion CS suivante :
CREATE TABLE Commande
CREATE TABLE Client
CREATE TABLE Article
CREATE TABLE Porter
…
CREATE ASSERTION CS
CHECK (NOT EXISTS
(SELECT n°commande FROM Commande
WHERE n°commande NOT IN
(SELECT n°commande FROM Porter)
AND n°client IS NOT NULL
UNION
(SELECT n°commande FROM Porter
WHERE n°commande NOT IN
(SELECT n°commande FROM Commande)
WHERE n°client IS NOT NULLLa résolution d'une contrainte de simultanéité par trigger sera partielle au risque de blocage. Ainsi en Oracle, on pourra retenir l'un de ces deux triggers :
CREATE TRIGGER Simultaneité_Passer_Porter
BEFORE INSERT OR UPDATE n°client ON Commande
ON EACH ROW
WHEN new.n°client IS NOT NULL
DECLARE
nb_article_passer number;
BEGIN
SELECT COUNT(*) INTO nb_article_passer FROM Passer
WHERE n°commande = :new.n°commande;
IF nb_article_passer = 0
raise_application_error (-20004, 'La commande n'est pas porteuse d'articles' );
END IF;
END;ou bien :
CREATE TRIGGER Simultaneité_Porter_Passer
BEFORE INSERT ON Porter
ON EACH ROW
WHEN new.n°client IS NOT NULL
DECLARE
nb_article_porter number;
BEGIN
SELECT COUNT(*) INTO nb_article_porter FROM Commande
WHERE n°client IS NOT NULL;
IF nb_article_porter = 0
raise_application_error (-20005, "La commande n'est pas encore passée par un client" );
END IF;
END;III-C-3-y. Totalité de participations d'une entité à plusieurs relations (OU INCLUSIF)▲
On l'exprime au niveau conceptuel par une contrainte T (voir chapitre 7 « Contraintes sur la participation d'une entité à plusieurs relationsContraintes sur la participation d'une entité à plusieurs relations »). Exemple, tout Véhicule est relié soit à Contrat par la relation Couvrir, soit à Sinistre par la relation Impliquer, soit les deux (cf. figure 13.36).
 |
 |
Schémas relationnels associés à la figure 13.36 :
- table VEHICULE (n°véhicule, n° contrat…) ;
- table CONTRAT (n°contrat…) ;
- table SINISTRE (n°sinistre…) ;
- table IMPLIQUER (n° sinistre, n°véhicule).
Pour exprimer la contrainte d'exclusion (T) en SQL-2, on déclarera l'assertion CT suivante :
CREATE TABLE Véhicule
CREATE TABLE Contrat
CREATE TABLE Sinistre
CREATE TABLE Impliquer
…
CREATE ASSERTION CT
CHECK (NOT EXISTS
(SELECT n°véhicule FROM Véhicule
WHERE n°véhicule NOT IN
(SELECT n°véhicule FROM Véhicule
WHERE n°contrat IS NOT NULL)
UNION
SELECT n°véhicule FROM Impliquer));On ne peut traiter cette contrainte de totalité de participation T par triggers, car on doit d'abord insérer (INSERT) un tuple de véhicule avant de l'affecter soit par la relation « couvrir » ou la relation « impliquer » (Primary Key et Foreign Key). Un trigger sur la table Véhicule sur insertion ou mise à jour ne peut ainsi assurer aucun contrôle pertinent. Une telle contrainte sera donc traitée de façon traditionnelle dans l'application.
III-C-3-z. Partition de participations d'une entité à plusieurs relations (OU EXCLUSIF)▲
On l'exprime au niveau conceptuel par une contrainte XT. Reprenons l'exemple qui nous avait servi pour présenter au niveau conceptuel cette contrainte : une Commande est soit destinée à un Client, soit à un Service interne de l'entreprise, mais pas au deux à la fois. On a ici une contrainte d'exclusion de participation de l'entité Commande aux relations Concerne/1 et Concerne/2 (cf. figure 13.37).
 |
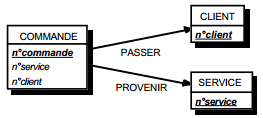 |
Schémas relationnels associés à la figure 13.37 :
- table COMMANDE (n°commande, n°service, n°client) ;
- table CLIENT (n°client…) ;
- table SERVICE (n°service…).
Pour exprimer la contrainte de partition XT en SQL-2, on déclarera l'assertion CXT suivante :
CREATE TABLE Commande
CREATE TABLE Client
CREATE TABLE Service
…
CREATE ASSERTION CXT
CHECK (NOT EXISTS
(SELECT n°commande FROM Commande
WHERE n°commande NOT IN
(SELECT n°commande FROM Commande
WHERE n°client IS NOT NULL)
UNION
SELECT n°commande FROM Commande));
WHERE n°service IS NOT NULL)
…On ne peut totalement traiter cette contrainte de partition de participation XT par triggers. Si la contrainte d'exclusion X peut être traitée par deux triggers sur le modèle déjà présenté, le traitement de la contrainte de totalité T n'est pas possible pour les raisons déjà évoquées précédemment.
III-C-3-aa. Inclusion de participations d'une entité à plusieurs relations (INCLUSION)▲
On l'exprime au niveau conceptuel par une contrainte I. Soit à exprimer que toute personne qui effectue un prêt doit avoir souscrit un abonnement. Par rapport à l'entité PERSONNE, la relation EFFECTUER est incluse dans la relation SOUSCRIRE (cf. figure 13.38).
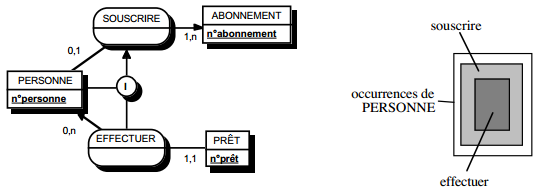 |
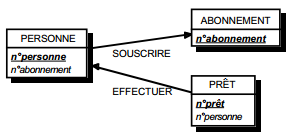 |
Schémas relationnels associés à la figure 13.38 :
- table PERSONNE (n°personne, n°abonnement…) ;
- table ABONNEMENT (n°abonnement…) ;
- table PRET (n°prêt, n°personne…).
Pour exprimer la contrainte d'inclusion I en SQL-2, on déclarera l'assertion CI suivante :
CREATE ASSERTION I
CHECK (NOT EXISTS
(SELECT DISTINCT n°personne FROM Personne A
WHERE NOT EXISTS
(SELECT DISTINCT n°personne FROM Prêt B
WHERE (A.n°personne= B.n°personne))
AND n°abonnement IS NOT NULL));On pourrait traiter aussi cette contrainte d'inclusion I par un trigger, comme celui-ci déclaré dans Oracle :
CREATE TRIGGER Inclusion_Effectuer_Souscrire
BEFORE INSERT ON Pret
ON EACH ROW
WHEN new.n°personne IS NOT NULL
DECLARE
nb_abonnement number;
BEGIN
SELECT COUNT(*) INTO nb_abonnement FROM Personne
WHERE n°personne = :new.n°personne;
IF nb_abonnement = 0 THEN
raise_application_error (-20006, 'Un abonnement n'a pas été souscrit' ));
END IF;
END;III-C-3-ab. Contraintes sur la participation de plusieurs entités à plusieurs relations▲
Rappelons que ces contraintes permettent d'exprimer des conditions d'existence d'occurrences de relations types selon la présence ou l'absence de participations à d'autres relations types. Nous allons étudier différentes situations pouvant se présenter (voir chapitre 7 « Contraintes sur la participation d'une entité à plusieurs relationsContraintes sur la participation d'une entité à plusieurs relations »).
III-C-3-ac. Contraintes d'inclusion de relations sur d'autres relations▲
Par exemple, pour qu'un professeur enseigne une matière à une classe donnée, il faut qu'il sache enseigner cette matière. On a ici une contrainte d'inclusion de la relation Enseigner dans la relation Qualifier, que l'on modélisera de la façon suivante (cf. figure 13.39) :
 |
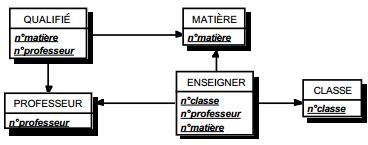 |
Avec les schémas relationnels suivants (figure 13.39) :
- table PROFESSEUR (n°professeur…) ;
- table MATIÈRE (n°matière…) ;
- table CLASSE (n°classe…) ;
- table QUALIFIE (n° matière, n°professeur) ;
- table ENSEIGNER (n°classe, n°professeur, n°matière ).
Dans Oracle, on pourrait traiter cette contrainte d'inclusion I par le trigger suivant :
CREATE TRIGGER Inclusion_Enseigner_Qualifier
BEFORE INSERT ON Enseigner
ON EACH ROW
DECLARE
est_qualifié number;
BEGIN
SELECT COUNT(*) INTO est_qualifié FROM Qualifier
WHERE n°professeur = :new.n°professeur
AND n°matière = :new.n°matière;
IF est_qualifié = 0 THEN
raise_application_error (-20007, "Ce professeur n'est pas qualifié pour cette matière" ));
END IF;
END;III-C-3-ad. Contraintes d'exclusion de relations sur d'autres relations▲
Par exemple, une personne ne peut pas être locataire et propriétaire d'un même logement, comme l'illustre la figure suivante (cf. figure 13.40) :
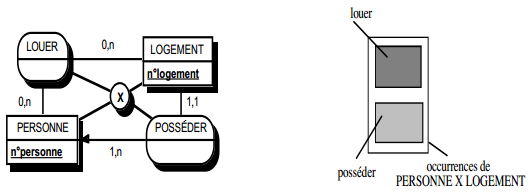 |
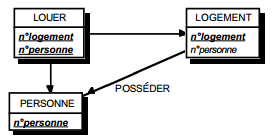 |
Schémas relationnels associés (figure 13.39) :
- table LOUER (n° logement, n° personne) ;
- table LOGEMENT (n°logement, n°personne…) ;
- table PERSONNE (n°personne…)
Dans Oracle, on pourrait exprimer cette contrainte d'exclusion X par les deux triggers suivants :
CREATE TRIGGER Exclusion_Louer_Logement
BEFORE INSERT ON Louer
ON EACH ROW
DECLARE
possède_déjà number;
BEGIN
SELECT COUNT(*) INTO possède_déjà FROM Louer
WHERE n°personne = :new.n°personne
AND n°logement = :new.n°logement ;
IF possède_déjà > 0 THEN
raise_application_error (-20008, 'Cette personne est déjà propriétaire de ce logement' ));
END IF;
END;et :
CREATE TRIGGER Exclusion_Logement_Louer
BEFORE INSERT ON Logement
ON EACH ROW
WHEN new.n°personne IS NOT NULL
DECLARE
nb_location number;
BEGIN
SELECT COUNT(*) INTO nb_location FROM Louer
WHERE n°personne =: new.n°personne
IF nb_location > 0 THEN
raise_application_error (-20009, 'La personne n° ',
new.n°personne, ' est déjà locataire' ));
END IF;
END;III-C-3-ae. Contraintes sur les occurrences de relations ayant des entités communes - Contrainte d'égalité▲
Soit une entité I1 reliée indirectement à une entité I2 par des relations binaires fonctionnelles formant des cheminements distincts. Pour toute occurrence de I1, l'occurrence de I2 obtenue par l'un des cheminements est identique à celle obtenue par l'autre cheminement. On l'exprime par une contrainte E dite « contrainte d'égalité ».
Reprenons l'exemple que nous avons déjà vu au chapitre 7Chapitre 7 Modélisation conceptuelle des données. Pour toute occurrence de commande, l'occurrence de client donneur d'ordre de la commande (relation passer) est toujours identique à l'occurrence de client propriétaire (relation posséder) du dépôt auquel doit être livrée (relation livrer à) la commande. La figure suivante illustre la modélisation conceptuelle associée spécifiant une identification relative de l'entité DEPOT par rapport à l'entité CLIENT et une contrainte d'égalité E. La dérivation au niveau logique est la suivante :
 |
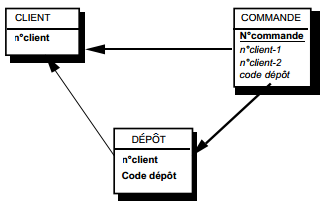 |
Les schémas relationnels associés sont :
- table CLIENT (n°client) ;
- table COMMANDE (n°commande, n°client-1, n°client-2, code dépôt) ;
- table DEPOT (n°client, code dépôt).
L'identifiant relatif conduit à la clé primaire composée n°client, code dépôt dans la table DEPOT. Dans la table COMMANDE, n°client-1 est la clé étrangère réalisant le lien avec la table CLIENT et n°client-2, code dépôt constitue la clé étrangère (composée) vers la table DEPOT. Compte tenu de la contrainte d'égalité et de l'identification relative, on déclare pour la table COMMANDE deux clés étrangères identiques (n°client-1 et n°client-2) ; aussi peut-on les fusionner, ce qui donne alors le nouveau schéma relationnel suivant :
- table CLIENT (n°client) ;
- table COMMANDE (n°commande, n°client, code dépôt) ;
- table DEPOT (n°client, code dépôt).
III-C-4. Quantification des modèles logiques de données▲
Une première quantification en volume du MOD (modèle organisationnel de données) a déjà été effectuée, elle a permis notamment de définir les cardinalités moyennes et le taux de participation des relations (voir figure 13.42).
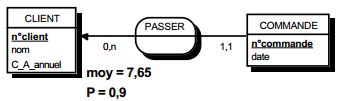
Au niveau logique, il s'agira simplement d'affiner cette première estimation en tenant compte de la structure logique des données correspondant à la modélisation conceptuelle. Ainsi pour un MLD relationnel :
- la cardinalité moyenne d'une patte de relation du MCD devient la cardinalité moyenne du lien relationnel associé. Elle est alors définie par le rapport : nb d'occurrences table enfant / nb d'occurrences table parent ;
- le taux de participation d'une table enfant à une table parente est défini par le rapport : nb d'occurrences de la table parente référées / nb total d'occurrences table parent.
Ce taux est de 100 % si la cardinalité mini est de 1. Dans notre exemple, on aura le schéma de la figure 13.43.
Le concepteur exprime ainsi l'ensemble des résultats du chiffrage :
-
pour chaque table/record :
- la taille totale, en caractères = somme de la taille des attributs composant la table,
- la durée de vie des occurrences de la table,
- le nombre maximum d'occurrences mémorisables dans la mémoire immédiate ;
-
Pour chaque lien relationnel :
- la cardinalité moyenne,
- le taux de participation,
- optionnellement la cardinalité maxi ou mini à 95 %.
III-C-4-a. Évaluation du volume global du modèle logique de données▲
À partir des éléments quantifiés précédemment déterminés, le concepteur peut procéder à une évaluation grossière du volume total des données à mémoriser, pour la mémoire immédiate. Cette évaluation sera affinée ultérieurement en tenant compte de l'optimisation (abordée ultérieurement) et des caractéristiques techniques du système de gestion de base de données utilisé.
Dans le cas d'un MLD relationnel, ce volume se décompose en deux parties :
- Le volume consacré aux données proprement dites contenues dans les tables « primaires », ou volume « utile ». Il peut être estimé par kitxmlcodeinlinelatexdvp\sum\limits_{toutes\ les\ tables} \mathrm{taille\ des\ tables} \times \mathrm{nombre\ d'occurrences\ maxi}finkitxmlcodeinlinelatexdvp.
- Le volume dû aux index secondaires qui seront installés sur ces tables (ces index sont, dans la plupart des SGBD relationnels commercialisés, des tables à part entière — « tables index » —, leur estimation en volume suit alors le mode précédent).
Ce volume total est une estimation de la taille nécessaire pour la mémorisation de la future base de données. En pratique, une bonne exploitation de la base de données nécessitera un volume utile bien plus important, on adoptera un coefficient de 2 à 3 ou plus selon les requêtes effectuées sur la base et les performances du SGBD adopté.
III-C-5. Modèles logiques de données répartis et client-serveur▲
III-C-5-a. Problématique générale▲
Nous avons vu dans la deuxième partie, relative à l'étude du SIO (système d'information organisationnel), un premier type de répartition des données exprimée dans les MOD (voir chapitre 1010Chapitre 10 Modélisation organisationnelle des données). Cette répartition organisationnelle des données consistait tout d'abord à choisir, à partir du MCD, les données à mémoriser informatiquement et celles qui ne le seraient pas (MOD Global), ensuite à répartir les données informatisées selon les unités organisationnelles (MOD locaux), en définissant pour chaque unité et pour chaque donnée, les droits d'accès autorisés ainsi que les modalités de partage des données entre ces unités organisationnelles.
Pour les données comme pour les traitements, les répartitions organisationnelles et logiques sont très différentes. La répartition organisationnelle des données est perceptible par l'utilisateur et concerne l'organisation de ses tâches à travers le besoin et la disponibilité des données que l'on peut spécifier au travers des MOD répartis (cf. chapitre 10Chapitre 10 Modélisation organisationnelle des données). La répartition logique de données est elle liée à l'implantation informatique des données sur des machines logiques différentes. Notons que la répartition logique est transparente à l'utilisateur, et n'a aucun impact sur son organisation, mais concerne exclusivement l'informatique. La figure suivante illustre cette problématique :
III-C-5-b. Critères de répartition▲
Les critères de répartition reposent souvent sur des considérations techniques (volume des échanges, capacité des systèmes). Aussi la quantification des modèles logique de données que nous venons de traiter a ici tout son intérêt. De même on peut tirer parti de la répartition organisationnelle, donc des MOD, pour tenter de rapprocher le plus possible les données de leur lieu d'utilisation, en distinguant entre autres la mise à jour et la lecture comme nous le verrons par la suite.
La répartition des données au niveau logique doit être perçue comme un arbitrage entre des considérations techniques (caractéristiques des matériels) et l'utilisation des données mémorisées (localisation, fréquence et nature des accès) qui provient du niveau organisationnel. Nous l'illustrons dans la solution du cas X que nous proposons.
Dans la répartition logique des données, un point nous semble important à évoquer, c'est la mise en cohérence de données dupliquées. Il y a duplication de données lorsque des occurrences identiques de tables sont mémorisées sur des sites différents. Il est alors nécessaire de préciser les mécanismes qui permettront d'assurer la cohérence des valeurs ; leur choix dépend des utilisations de ces données (fréquence, action).
III-C-5-c. Répartition et architectures client - serveur▲
La répartition informatique (logique et physique) des données est particulièrement concernée dans la mise en œuvre des architectures client-serveur.
La méthode Merise se positionne essentiellement sur le terrain de l'ingénierie des systèmes d'information, avec un accent particulier sur le système d'information organisationnel (SIO), pour lequel les considérations technologiques ne sont pas la préoccupation centrale. Toutefois, l'évolution technologique apportée par le client-serveur est suffisamment importante pour s'interroger sur son impact sur les raisonnements à mettre en œuvre pour la conception d'un système d'information dans un tel environnement. Ainsi, la mise en œuvre d'architecture client-serveur est grandement facilitée dans Merise deuxième génération du fait que :
- les modélisations des données et des traitements proposées sont tout à fait adaptées aux nouvelles possibilités apportées par le client-serveur ;
- la répartition organisationnelle des données et des traitements (MOD MOT) s'avère un élément décisif dans le choix de la répartition informatique dans une solution client-serveur.
Aussi développerons-nous en détail ces deux points dans les paragraphes suivants.
III-C-5-d. Modélisations conceptuelle et organisationnelle des données pour le client-serveur▲
Le client-serveur a incontestablement consacré la place centrale des données dans la conception d'un système d'information. Par sa puissance d'expression sémantique et sa facilité de transformation en formalisme relationnel, la modélisation conceptuelle et organisationnelle des données en Entité-Relation proposée par Merise confirme incidemment son importance.
III-C-5-d-i. Modélisation des données et serveur de données relationnel▲
La répartition des données et des traitements sur des systèmes distincts a rendu encore plus nécessaire une analyse des données indépendante des traitements. Cette situation privilégie une démarche de conception et de structuration des données à partir de leur sémantique. Rappelons qu'il s'agit d'un des principes fondamentaux de la méthode Merise.
Les raisonnements proposés par la méthode Merise pour la conception d'une base de données relationnelle restent donc toujours pertinents pour la définition de serveurs de données relationnels, comme l'illustre la figure suivante :

La nécessité d'une modélisation conceptuelle/organisationnelle des données pour concevoir un serveur de données relationnel se confirme d'ailleurs par la présence de tels outils dans la grande majorité des AGL. Notons que les formalismes utilisés pour cette modélisation dans ces AGL peuvent être différents (surtout pour les outils d'inspiration anglo-saxonne) et leur puissance d'expression plus ou moins importante, comme nous l'avons déjà évoquée dans la présentation du formalisme Entité-Relation de Merise.
III-C-5-d-ii. Modélisation des données et systèmes ouverts▲
La possibilité de développer des systèmes ouverts conduit progressivement à concevoir un serveur de données sur un domaine d'activité avant de connaître et de spécifier les différents traitements qui pourront ultérieurement utiliser ce serveur. Un tel contexte rend indispensable une conception de la base de données centrée sur la sémantique. L'approche préconisée depuis plusieurs années par Merise trouve ici toute sa justification. Dans le contexte actuel des serveurs relationnels, même de deuxième génération, nous restons persuadés qu'une modélisation conceptuelle/organisationnelle de données avec le formalisme Entité-Relation de Merise reste encore la démarche la plus efficace pour concevoir un serveur de données relationnel dans un système ouvert.
III-C-5-d-iii. Modélisation des données et systèmes d'information d'aide à la décision▲
Dans un système d'information d'aide à la décision, l'utilisateur recherche une vision globale de l'entreprise, puisant ses informations dans divers systèmes d'information de production déjà existants, répartis sur différents serveurs de données. Les traitements consistent fréquemment en des analyses de données (tableaux, graphiques, analyses statistiques) et des simulations ; les logiciels « classiques » de la micro offrent de multiples possibilités à l'ergonomie adaptée et appréciée.
Dans le développement de tels systèmes d'information, le problème principal est la connaissance du contenu des différents systèmes d'information de production. Les modélisations conceptuelle/organisationnelle des données prennent ainsi une importance capitale. Les concepteurs doivent très tôt vérifier si la perception globale de l'utilisateur du futur SI d'aide à la décision correspond aux perceptions modélisées dans les MCD/MOD des SI de production. En particulier, ils doivent s'assurer de la présence d'entités partagées (elles permettent de faire le lien entre les systèmes) et à leur concordance de signification (le produit vendu, l'item fabriqué, la fourniture achetée peuvent-ils être considérés comme un sous-type d'article ?).
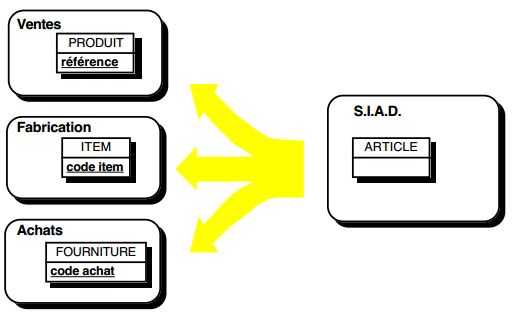
Là encore, le synthétisme et la puissance d'expression d'un MCD/MOD tel que le préconise Merise est un atout pour représenter et connaître le contenu des différents serveurs de données. Ce rôle ne fait que se confirmer avec le développement du « data warehousing ».
III-C-5-d-iv. Modélisation des données et serveurs deuxième génération▲
Cette nouvelle génération se caractérise par la prise en charge de traitements par le serveur ; la plupart de ces traitements étant déclarés sous forme de « triggers », « règles » ou « procédures » gérées par le même logiciel que les données. En général, ces traitements sont décrits dans le dictionnaire commun de données et de traitements.
Cette migration des traitements vers le serveur a une double justification :
- des préoccupations techniques de performance qui ont été justifiées dans la première partie de ce chapitre ;
- la nécessité, dans des systèmes ouverts, d'associer plus intimement les données et les règles de traitement qui préservent sa cohérence sémantique ; ces règles et contraintes ont une permanence et un champ d'application indépendant du contexte d'utilisation par tel ou tel traitement.
L'expression de ces règles et contraintes peut s'effectuer sur le modèle conceptuel de données. C'est dans cet objectif que nous avons introduit les contraintes inter relations, les contraintes de stabilité et le concept de règle dans le formalisme Entité - Relation (cf. chapitre 7Chapitre 7 Modélisation conceptuelle des données). Ces différents concepts sont traduits au niveau logique (cf. chapitre 12Chapitre 12 Modélisation Logique des Traitements) et implémentables pour la plupart par des « triggers ».
III-C-5-e. Modélisations logiques des données et traitements répartis▲
L'une des caractéristiques principales de l'architecture client-serveur est la possibilité de répartir les données et les traitements sur des systèmes différents. Comme nous l'avons vu dans la première partie du chapitre, cette répartition est le critère d'une typologie de clients-serveurs.
Fréquemment cette répartition est globale et ne nécessite pas une modélisation spécifique. Ainsi, dans le cas d'une application où l'ensemble de la présentation et des traitements est sur les postes clients, et l'ensemble des données concernées est implanté sur un serveur unique, il est superflu d'utiliser une quelconque modélisation pour représenter une telle répartition.
Par contre, dans le cas d'architectures client-serveur distribuées, les traitements et les données d'une application peuvent être répartis entre les postes clients et plusieurs serveurs. Il est alors utile de représenter la répartition des différents traitements et données entre les différents systèmes.
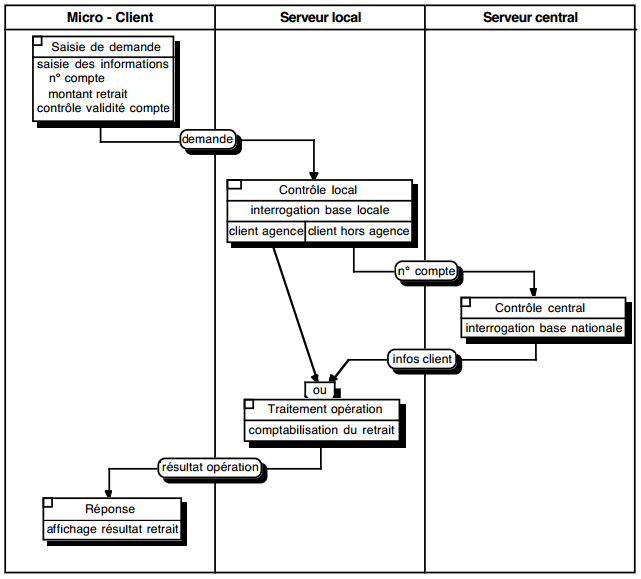
Dans Merise deuxième génération, la modélisation logique des traitements (voir chapitre 12Chapitre 12 Modélisation Logique des Traitements) permet d'exprimer complètement cette répartition au moyen :
- des machines logiques ;
- de la décomposition des unités logiques de traitement (ULT) globales en ULT par nature.
La figure 13.47 présente un MLT spécifiant une répartition logique de traitements client-serveur.
Les modèles organisationnels de données locaux (voir MOD - chapitre 10Chapitre 10 Modélisation organisationnelle des données) ont été spécialement introduits dans Merise pour prendre en compte la répartition des données d'une application sur plusieurs systèmes, en précisant également les notions d'accès aux données et de références. Le cas société X traité au chapitre 10 illustre cette problématique de la répartition entre plusieurs serveurs.
III-C-5-f. De la répartition organisationnelle à la répartition informatique - B.P.R., répartition organisationnelle et client-serveur▲
Les tendances actuelles de la conception des systèmes d'informations, tirant profit des principes de réorganisation des activités proposés par le B.P.R., préconisent une organisation des entreprises en petites unités organisationnelles relativement autonomes, chacune disposant des moyens nécessaires pour assurer ses missions avec le maximum de flexibilité et d'efficacité. Dans cette optique, les systèmes clients-serveurs, en facilitant la répartition des données et des traitements, permettent de se libérer progressivement des architectures hiérarchiques (techniques et organisationnelles) induites par les systèmes centralisés, tout en préservant l'accessibilité des données nécessaire à la cohérence globale de l'entreprise. La répartition informatique des données et des traitements est alors au service d'une répartition organisationnelle.
Cependant, il nous semble aujourd'hui que de nombreuses applications développées ou transposées en client-serveur n'ont opéré qu'un simple changement de technologie, en concentrant sur le même serveur l'ensemble des données antérieurement implantées sur un système centralisé. La répartition informatique se réduit alors à celle techniquement induite par la nouvelle technologie. Pourtant, les capacités d'ouverture et d'interopérabilité du client-serveur, le « down-sizing » accompagnant sa diffusion, rendent accessible techniquement et économiquement une meilleure répartition des systèmes d'information informatisés.
Pour bénéficier pleinement des possibilités offertes par le client-serveur pour concevoir de nouveaux systèmes d'information plus modulaires, la plupart des spécialistes en la matière préconisent de rapprocher les données et les traitements de leur site d'utilisation. La répartition informatique est alors au service de la répartition organisationnelle.
La méthode Merise dispose, avec les différents modèles dédiés à la description du système d'information organisationnel, d'un ensemble de raisonnements permettant d'exprimer cette répartition des données et des traitements. Elle peut ainsi fournir une aide méthodologique pour la conception d'un système d'information informatisé distribué, dans un environnement client-serveur.
III-C-5-g. Répartition organisationnelle des traitements▲
La répartition des activités s'exprime essentiellement autour de la notion d'unité organisationnelle qui recouvre généralement un ensemble de postes représentant par exemple un service ou un site géographique.
La représentation de cette répartition des activités s'effectue fréquemment sous la forme de macro-MOT ou MCT réparti, une modélisation assez proche du degré de détail d'un MCT courant sur lequel on exprime la répartition entre les unités organisationnelles. La figure 13.48 illustre la répartition des opérations entre les unités organisationnelles dans le cas société X (cf. MOT - fin du chapitre 8Modularité dans un modèle organisationnel de traitements).
La mise en évidence de cette répartition doit s'effectuer assez tôt dans l'étude, généralement en étude préalable. Cette répartition peut être soit décidée a priori, soit déduite d'une analyse plus fine des MOT et obtenue ensuite par un regroupement de postes.
III-C-5-h. Répartition organisationnelle des données▲
Cette répartition se formalise par les MOD locaux qui expriment l'ensemble des données communes et partagées par les utilisateurs d'une même unité organisationnelle (voir chapitre 10Chapitre 10 Modélisation organisationnelle des données). Rappelons qu'un MOD local se représente pour chaque unité organisationnelle par :
- un schéma des entités, des relations et propriétés utilisées ;
- un tableau précisant l'accessibilité des données (actions autorisées, restriction d'occurrences).
On peut adopter deux démarches complémentaires pour l'élaboration des MOD locaux :
- définir a priori, à partir du MOD global et connaissant les activités des différentes unités organisationnelles, la répartition et l'utilisation des entités et des relations ;
- déduire les MOD locaux en cumulant les sous-schémas de données associés aux phases ou tâches prises en charge par chaque unité organisationnelle.
III-C-5-i. Des indicateurs pour la répartition logique des données▲
Dans le cas d'une implémentation sur un serveur de données unique, nous avons vu que le passage du MCD/MOD au MLD puis à la base de données relationnelle était quasiment automatique, en appliquant des règles formelles.
Dans le cas d'une répartition des données sur plusieurs serveurs, les critères influents sur le choix de répartition sont multiples et ne peuvent aujourd'hui être automatisés. S'il est certain que les aspects techniques ont une part indéniable, la répartition de l'utilisation des données exprimée dans les MOD locaux fournit, comme nous allons le présenter, de très utiles indications pour orienter une répartition informatique.
III-C-5-i-i. Degré de partage▲
Il y a partage lorsque des entités ou des relations figurent dans plusieurs MOD locaux. L'intérêt d'une répartition logique dépend d'une part de l'étendue du partage, d'autre part des différents accès envisagés. Une première règle de répartition, relevant du « bon sens », (cf. figure 13.49) peut s'exprimer ainsi :
- si peu de données sont partagées, alors une répartition informatique quasi naturelle s'ébauchera ;
- si les données partagées sont importantes, en type et en occurrences, la répartition informatique est assez déconseillée.
 |
|
Forte intersection |
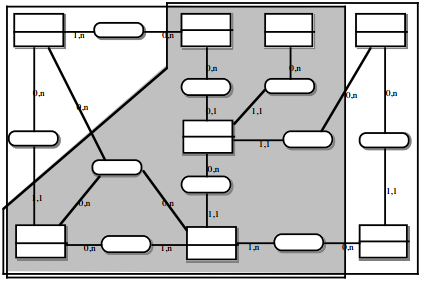 |
III-C-5-i-ii. Accessibilité▲
Pour les données partagées, une seconde règle, basée sur le type d'accès, peut être appliquée :
- des données en lecture seule peuvent être implantées sur un serveur distant sans trop de contraintes ;
- des données en mise à jour (création, modification, suppression) doivent être de préférence implantée sur un serveur plus proche.
Le type d'accès doit également être pondéré par la fréquence d'accès. Ce qui nous donne le tableau synthétique suivant :

Situation pour un accès distant
Le caractère de proximité peut être physique et/ou technique (puissance de débit du réseau, capacité d'accès du serveur).
III-C-5-i-iii. Duplication▲
Les règles précédentes cherchaient à privilégier une localisation informatique unique des différentes données, même en cas d'utilisation partagée. Cette unicité de mémorisation est, encore actuellement, une bonne garantie pour le maintien de la cohérence ; bien que les systèmes clients - serveurs annoncent des possibilités de réplication de plus en plus fiables et efficaces.
Dans le cas où des données sont partagées avec des actions de mise à jour relativement importantes, il peut être nécessaire de dupliquer ces informations sur des serveurs différents. Se pose alors le problème du maintien de la cohérence entre les serveurs. Deux grandes catégories de solutions peuvent alors être utilisées :
- une mise à jour différée ;
- la « réplication » des données sur les serveurs avec la technique de « commit en deux phases ».
Le choix de la solution dépend certes des possibilités techniques, mais s'apprécie également à travers les conditions d'utilisation des données exprimées au niveau du système d'information organisationnel par les MOT et MOD.
Les solutions du cas de la Sté X proposées (cf. CD-ROM) illustrent différents exemples de répartition, duplication et synchronisation.
III-C-5-j. En conclusion…▲
La technologie client-serveur a apporté directement ou indirectement deux grandes avancées : d'une part la généralisation des interfaces graphiques pour les systèmes d'information informatisés et d'autre part la possibilité de répartir des données et des traitements sur des systèmes distincts et autonomes.
La première est, à notre avis, la plus visible et appréciée des utilisateurs, mais a confronté les informaticiens à de nouvelles logiques de construction d'interfaces (ergonomie et dialogue). Reconnaissons que, sur ce point, la méthode Merise n'apporte pas vraiment d'aide méthodologique, pas plus qu'elle ne l'apportait précédemment pour la conception des interfaces transactionnelles. Les modèles logiques de traitement intègrent certes la présentation comme composant de la modélisation logique des traitements, mais sans donner de conseil sur sa construction.
La seconde, plus discrète, ouvre des possibilités encore peu exploitées. Nous avons voulu montrer que la méthode Merise non seulement restait d'actualité pour concevoir des serveurs de données de deuxième génération, mais proposait également, avec son approche du système d'information organisationnel, un cadre méthodologique opérationnel pour maîtriser la mise en place de systèmes distribués au service de l'organisation.
III-D. Chapitre 14 Optimisation des Modèles de Données▲
III-D-1. Introduction▲
III-D-1-a. Problématique de l'optimisation▲
Les modèles logiques de données (MLD) dérivés directement des modèles conceptuels/organisationnels de données (MCD/MOD) ont jusqu'à présent ignoré les problèmes d'accès, de performance, de volume et de coût, pour se concentrer exclusivement, par la prise en compte sur des structures informatisables, de la signification des informations.
La définition des traitements, au travers des modèles organisationnels de traitements (MOT) et des modèles logiques de traitements (MLT), précise la nature et la fréquence de ces accès aux données. Ces accès influencent de façon déterminante les performances des traitements. Une amélioration des performances de ces derniers pourra être obtenue en optimisant l'organisation logique et l'implémentation physique des données, en agissant donc sur le modèle logique de données (MLD) et le modèle physique des données (MPD).
L'optimisation des modèles logique et physique de données nécessite ainsi une très bonne connaissance des traitements qui y seront effectués. Il est certain que des traitements n'effectuant que des accès aux données en consultation ne conduiront pas aux mêmes optimisations que celles qui seraient conduites pour des traitements effectuant des accès en mises à jour nombreuses à ces mêmes données. De même, la nature des traitements, conversationnelle ou différée, unitaire ou par lots, conduira à des optimisations différentes.
En conséquence, l'optimisation des modèles de données du système d'information informatisé sera toujours un compromis global, consistant à définir une organisation et une implémentation des données conduisant à des performances globalement satisfaisantes pour l'ensemble des traitements. Ce compromis portera principalement sur :
- le volume global occupé par les données mémorisées ;
- le temps nécessaire pour accéder à ces données mémorisées ;
- la contrainte de transfert entre les données stockées et l'unité centrale ;
- des contraintes diverses et particulières à certains systèmes.
Nous allons, dans ce chapitre, présenter cette optimisation spécifiquement à l'environnement relationnel déjà étudié dans le cadre de la modélisation.
III-D-1-b. Optimisation en relationnel▲
Les bases de données relationnelles présentent beaucoup d'intérêt, résultant principalement de la puissance du modèle relationnel auquel elles se réfèrent. Bien que ce modèle soit apparu pratiquement au même moment que le modèle navigationnel, il a fallu attendre de nombreuses années pour que les systèmes de gestion de bases de données (SGBD) relationnels présentent, pour des développements d'une certaine taille, des performances suffisantes, comparables à celles des SGBD navigationnels, et pour leur être préférés.
Les performances des SGBD relationnels continuent à s'améliorer, d'une part, grâce à l'usage d'un module intégré au cœur du système, appelé « optimiseur de requêtes », de plus en plus sophistiqué et, d'autre part, grâce à une parallélisation de plus en plus importante des traitements des requêtes, conduisant aux machines bases de données. Cependant, l'optimisation du modèle logique relationnel n'en reste pas moins une étape à la fois incontournable et délicate.
L'optimisation des modèles de données dans les systèmes relationnels se situe à la fois au niveau logique et au niveau physique. Nous précisons ici un ensemble d'optimisations possibles. Il est certain que cette optimisation est étroitement liée au SGBD retenu ; aussi pour un SGBD donné, certaines des optimisations proposées dans cet ouvrage ne seront pas possibles, d'autres optimisations, non évoquées, pourront alors être possibles. Notons qu'à notre connaissance, très peu d'ouvrages, spécialisés en bases de données, traitent cette optimisation de façon approfondie. Nous recommanderons cependant la lecture du travail de recherche réalisé par Daniel Richard [Richard 89].
Dans cet ouvrage, nous distinguerons deux grands types d'optimisations :
- L'optimisation physique qui consiste à tirer parti des possibilités du SGBD relationnel utilisé pour implanter au mieux les différentes tables de la base de données, ceci sans remettre en cause les modèles logiques de données déjà définis.
- L'optimisation logique ou dénormalisation qui consiste à effectuer différentes adaptations du modèle logique de données relationnel brut (dérivé du MCD/MOD) qui est normalisé. Ces adaptations reviennent à dénormaliser ce modèle. Cette dénormalisation devra être conduite avec une extrême prudence.
III-D-2. Optimisation physique▲
Comme nous venons de le dire, l'optimisation physique consiste à tirer parti des possibilités du SGBD relationnel utilisé pour implanter au mieux les différentes tables de la base de données, ceci.
Cette optimisation consiste d'une façon générale à exploiter judicieusement les possibilités du SGBD liées au stockage des données sur disque. Elle nécessite en conséquence une très bonne connaissance du SGBD, de ses possibilités liées à l'implantation des données sur disque, mais aussi du fonctionnement de son optimiseur de requête notamment en ce qui concerne l'exploitation qu'il fait de ces structures de stockage. En ne remettant pas en cause les modèles logiques de données, elle doit être abordée en premier lieu, avant l'optimisation logique associée à une dénormalisation des modèles logiques. L'optimisation physique porte notamment sur les points suivants :
- le choix des structures de stockage physique selon lesquelles seront implantées les tables du modèle logique relationnel ;
- la définition des chemins d'accès primaires liés aux organisations indexées (index - clé de placement) ;
- la mise en place de chemin d'accès secondaires ou index secondaire ;
- le partitionnement horizontal ou vertical des tables ;
- le regroupement (clustering) des tables, etc.
Nous allons aborder en détail ces différents points, en sachant que chaque SGBD présente ses propres spécificités qu'il est nécessaire de maîtriser pour aborder cette optimisation, optimisation relevant souvent de l'administrateur de bases de données.
III-D-2-a. Choix d'une organisation des tables (chemins d'accès primaires) - Performance et structures de données▲
Sollicité par une requête, un SGBD relationnel peut toujours trouver une donnée, mais un choix judicieux de structures de stockage supportant les tables de la base de données ou choix de l'organisation des tables permettra de réduire ce temps de recherche.
Un tel choix peut être judicieux pour certaines requêtes alors que pour d'autres il peut être pénalisant. Ce choix peut aussi affecter l'espace disque nécessaire (plus d'espace nécessaire) et avoir des conséquences gênantes, par exemple, sur la gestion de la concurrence (encore plus délicate).
La plupart des SGBD relationnels commercialisés proposent plusieurs organisations ou méthodes d'accès possibles pour stocker les tables de la base de données. Notons que ce choix d'organisations possibles est fortement lié au système d'exploitation pour lequel le SGBD relationnel est proposé. En effet, le système d'exploitation gère des organisations spécifiques mises à la disposition du SGBD. Parfois, ce dernier peut proposer des organisations nouvelles se rajoutant à celles déjà offertes par le système d'exploitation.
Le système d'exploitation Unix propose ainsi de nombreuses organisations de fichiers possibles et en conséquence, les SGBD relationnels sous Unix proposent généralement plusieurs organisations possibles pour les tables de la base. Par exemple, avec un SGBD sous Unix, une table pourra être organisée tout d'abord en :
- HEAP (fichier séquentiel) : c'est généralement l'organisation par défaut.
Sont ensuite proposées diverses organisations indexées (index principal, clé primaire de placement), par exemple les organisations suivantes :
- HASH (clé calculée) : une organisation aléatoire caractérisée par un accès sur une valeur exacte de la clé et une fonction de randomisation ne pouvant en général pas être modifiée par l'utilisateur.
- ISAM : une organisation indexée caractérisée par un tri selon une clé des données stockées, permettant un accès rapide sur valeur exacte ou partie de clé et reposant sur un index statique nécessitant une réorganisation quand la table augmente.
- BTREE : une organisation indexée caractérisée par un tri des données selon une clé, un accès rapide sur valeur exacte ou partie de clé et reposant sur un index dynamique (arbre balancé - Btree).
Il est en général possible par une commande (Modify) de changer l'organisation d'une table :
ModifyemployeToheap : réalisera une réorganisation de la table Employé en fichier séquentiel ;ModifyemployeTohashOnnom : fera une réorganisation de la table Employé en organisation aléatoire selon l'attribut nom ;ModifyemployeTobtreeOnnom, âge : conduira à une réorganisation de la table Employé en organisation indexée Btree selon les attributs nom et âge.
III-D-2-b. Choix de l'organisation d'une table▲
Disposant de plusieurs organisations possibles pour stocker les différentes tables de la base de données, l'administrateur de base de données pourra choisir pour chaque table l'organisation la plus adaptée. Par exemple :
L'organisation séquentielle (HEAP) sera préférée :
- pour le chargement de données dans la base ;
- lorsque la table est petite (occupation de peu de pages) ;
- lorsque les requêtes manipulent des tables entières ;
- pour récupérer de l'espace dû à des DELETE, la commande MODIFY employé TO heap permettra cette récupération. On pourra ensuite réorganiser la table dans l'organisation préférée par un autre MODIFY.
Cette organisation sera évitée lorsque :
- on a des accès à un ou plusieurs tuples ;
- les tables sont grosses.
L'organisation aléatoire HASH sera préférée pour toute recherche sur valeur exacte de clé (la plus rapide). Elle est à éviter lorsque :
- les requêtes nécessitent des recherches sur partie de clé ;
- on a des traitements de table entière ;
- on a des joints naturels (systématiques sans restriction) ;
- on a des débordements dès le départ (on ne peut ajuster la fonction de randomisation dans Ingres).
L'organisation indexée ISAM sera recommandée lorsque :
- les requêtes nécessitent des recherches sur une partie de clé ;
- la table grossit lentement (peu de réorganisations nécessaires) ;
- la clé est de taille importante.
Cette organisation n'est pas recommandée si :
- la recherche est sur clé complète (on lui préférera l'organisation HASH) ;
- la table est grosse et à croissance rapide.
L'organisation indexée BTREE sera préférée lorsque :
- les requêtes nécessitent des recherches sur une partie de clé ;
- la table grossit vite ;
- la table est trop grosse pour être souvent réorganisée (MODIFY) ;
- les requêtes conduisent à des joints de tables entières.
Elle sera évitée lorsque :
- la table est statique ou à croissance faible ;
- la clé est de taille importante ;
- il y a beaucoup d'ajouts de nouveaux tuples seulement en fin de table entraînant un plus grand risque de verrous mortels (dead-locks) par utilisateurs (problèmes de concurrence).
Le tableau de la figure 14.1 synthétise, pour un SGBD donné, la pertinence de chacune de ces organisations possibles, en fonction de la nature de la table ou d'opérations types majeures qui y sont réalisées par les traitements.
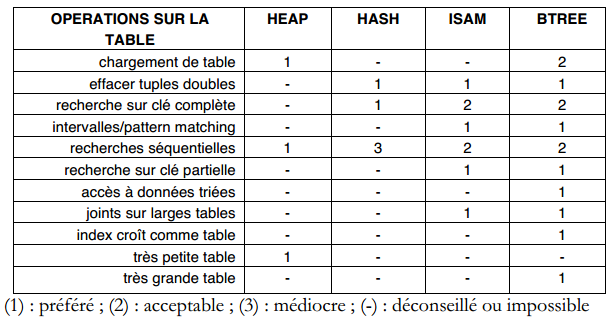
III-D-2-c. Optimisation par ajout d'index secondaires (chemins d'accès secondaires) - Index primaire et secondaire, clés plaçante et secondaire▲
Le critère de recherche le plus fréquemment utilisé sur une table relationnelle concerne la clé primaire. Elle peut être constituée d'un attribut (clé primaire simple) ou de plusieurs attributs (clé primaire composée). Placer les tuples de cette table sur disque selon la valeur de cette clé primaire facilitera grandement l'accès à la table selon ce critère. Cela sera possible en adoptant pour la table une organisation indexée, dans laquelle la clé primaire de la table sera aussi clé plaçante. On parle alors d'index primaire. Comme nous venons de le voir, le choix judicieux, pour chaque table de la base d'une d'organisation parmi différentes organisations proposées par le SGBD adopté (principalement indexées), est un choix d'optimisation important.
Les applications sur la base de données effectuent aussi des accès aux données selon de multiples critères de recherche. L'installation d'index secondaires permet d'éviter un coûteux balayage séquentiel de la table. Un index secondaire constitue un réordonnancement logique des tuples de la table en fonction d'une clé d'accès, pouvant être discriminante ou non, simple ou composée, différente de la clé plaçante sur laquelle est basée l'organisation de la table. Cette clé est dite clé secondaire (voir figure 14.2).
Lors d'une recherche sur index secondaire, le balayage de l'index secondaire donne les identifiants de tous les tuples, appelés aussi « tuples identifiants », satisfaisant le critère de recherche. Les tuples sont ensuite accessibles directement (à raison d'une entrée/sortie par page) via l'identifiant et selon l'organisation de la table.
Dans beaucoup de SGBD relationnels, un index secondaire installé sur une table A selon un attribut a est tout simplement une table organisée selon une organisation indexée particulière, dont les attributs sont la clé a et l'identifiant de tuple associé ou TIDP = pointeur sur le tuple de la table A. La figure 14.2 présente l'exemple d'index secondaire index_salaire dans un SGBD sur une table Emp d'employés, selon l'attribut salaire.
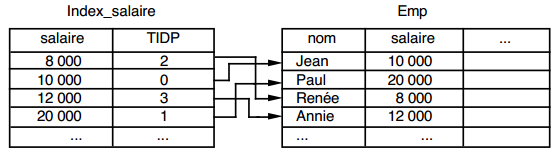
Le TIDP est un pointeur sur le tuple (adresse de page et offset sur la page) de la table emp. L'index secondaire index_salaire est une table de la base de données, qui a autant de tuples que la table emp (index dense) et qui est organisée par défaut par exemple en ISAM.
La création d'un index secondaire facilite ainsi grandement certains accès, mais introduit aussi des coûts de stockage et de mise à jour pouvant être importants. Pour le coût de stockage, plus la taille de la clé à indexer sera grande, plus l'encombrement de l'index secondaire sera important. Pour le coût de mise à jour, il est clair que toute mise à jour de la table indexée entraînera la mise à jour de tous les index secondaires portant sur cette table. Aussi, la mise en place d'index secondaires ne se fera que si elle est justifiée, restreinte à des critères de recherche les plus fréquents.
Il peut être intéressant de spécifier sur un MLD graphique l'installation d'index secondaires, on peut le faire comme sur la figure 14.3.
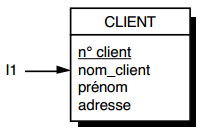 |
|
I1 est un index secondaire installé sur l'attribut nom_client de la table CLIENT |
Enfin les index secondaires sont généralement exploités par les optimiseurs de requêtes pour faciliter l'exécution de requêtes sur la base, notamment des jointures.
III-D-2-d. Installation d'index secondaires sur attributs non-clés▲
On peut installer des index secondaires sur des attributs non-clé plaçante sur des tables relationnelles issues d'entités. Il convient d'étudier l'intérêt d'une telle décision d'optimisation en fonction des fréquences prévisibles des accès sur ces attributs.
D'une façon générale, l'installation sur une table d'un index secondaire sur un attribut non-clé est justifiée par de nombreux accès à la table selon cet attribut. L'index réduira le coût de ces accès. La contrepartie est un coût de stockage lié à l'augmentation du volume à mémoriser de la base et qui dépend de la taille de l'attribut à indexer, de la ou des organisations indexées proposées par le SGBD adopté pour les index secondaires. Signalons aussi un coût supplémentaire associé aux mises à jour de la table (créations, modifications, suppressions) nécessitant aussi à des mises à jour de l'index.
III-D-2-e. Installation d'index secondaires sur attributs clés étrangères▲
On peut installer des index secondaires sur des attributs clés étrangères participant ou non à une clé primaire composée :
Index sur la clé primaire composée : la clé primaire étant une clé composée, elle peut avoir une taille importante. Aussi, ce type d'index ne sera utile que lorsqu'il existe des requêtes fréquentes portant sur les tuples de la table désignés par des valeurs complètes de la clé.
Index sur un ou plusieurs attributs composant la clé primaire : ce type d'index permet de réduire de façon considérable (principalement au niveau de l'optimiseur) les accès lors de requêtes dans lesquelles on ne connaît la valeur que d'une partie des attributs de la clé, cas très fréquent.
Index sur un attribut hors clé primaire : il ne sera utile que lorsqu'il existe des requêtes fréquentes portant sur les tuples de la table désignés par des valeurs de cet attribut.
D'une façon générale, l'installation sur une table d'un index secondaire sur un attribut clé étrangère est justifiée par de nombreux accès à la table selon cet attribut, ainsi que de nombreuses jointures de cette table avec la table vers laquelle la clé étrangère pointe. La contrepartie est aussi un coût de stockage qui dépend de la taille de l'attribut à indexer, ainsi qu'un coût de mise à jour à évaluer.
III-D-2-f. L'encodage et la compression des données▲
La réduction de l'espace nécessaire au stockage des données peut être déterminante. Une solution est alors l'encodage et la compression des données.
Les trois techniques principales sont :
- La suppression des blancs et des zéros dans les valeurs : elle est faite à chaque accès, ce qui entraîne des mises à jour plus coûteuses. Elle peut s'appliquer sur les structures SEQ, HASH, ISAM, BTREE et conduire à un gain en espace disque important. La compression de données est à éviter lorsque les données sont peu compressibles (exemple : l'attribut adresse plus compressible que l'attribut nom) ou qu'il y a de nombreux index secondaires à mettre à jour.
- La substitution de séquences : elle consiste à associer un code aux séquences de caractères les plus fréquentes et à le substituer à chaque occurrence de ces séquences.
- L'encodage statistique : il tient compte de la fréquence d'apparition des caractères (un caractère qui apparaît fréquemment aura une représentation plus courte que celle d'un caractère rare).
III-D-2-g. Partition de tables relationnelles (segmentation)▲
Cette optimisation a pour objet de réduire les coûts d'accès aux données en éliminant des informations inutilement transférées de la mémoire secondaire à la mémoire centrale (entrées/sorties). En effet, les attributs et tuples des tables d'une base de données relationnelle sont rarement tous utilisés dans les requêtes ; Knuth [Knuth 73 dans Richard 89] a montré que seulement 20 % des données effectivement stockées dans la base sont concernées par 80 % des requêtes lancées sur la base.
Aussi, il peut être judicieux de partitionner des tables afin de réduire le flux des informations en entrée/sortie. Le partitionnement (voir figure 14.4) consiste à éclater soit verticalement en paquets d'attributs, soit horizontalement en paquets de tuples, certaines tables de la base de données. Le paquet qui sera identifié comme le paquet le plus sollicité pourra, par exemple, être stocké sur le support mémoire secondaire le plus performant.
Tout se passe comme si une table du MLD était découpée en projections ou restrictions arbitraires (non soumises aux règles de la normalisation) et stockée dans des sous-tables implantées physiquement dans des zones mémoires différentes.
Le partitionnement vertical consiste à éclater une table en sous-tables regroupant les attributs les plus souvent invoqués ensemble. Le partitionnement doit être totalement transparent aux utilisateurs qui ne connaissent que les schémas logiques des tables ; ce qui nécessite un prétraitement de leurs requêtes. Les problèmes rencontrés lors de ce partitionnement sont alors [Richard 89] :
- le choix d'une bonne partition (table à n attributs : nn/2 partitions possibles) ;
- les coûts de certaines transactions utilisant des attributs répartis dans des paquets différents peuvent se révéler supérieurs à ce qu'ils seraient si les attributs n'étaient pas répartis.
Le partitionnement horizontal consiste à subdiviser les tuples d'une table en sous-tables de même schéma. On retrouve la table initiale par simple union algébrique des sous-tables. On regroupera ensemble les tuples ayant une forte probabilité d'être accessibles ensemble. Chaque sous-relation pourra avoir une organisation propre, optimisant l'accès. Les intérêts de ce partitionnement sont [Richard 89] :
- il peut apporter des solutions au problème de protection de données sensibles ;
- il peut se révéler efficace pour limiter la désorganisation des tables ayant un sous-ensemble de tuples soit de longueurs variables, soit pouvant avoir une valeur nulle, soit dont la valeur est plus souvent modifiée. La sous-table contenant ces tuples sera alors réorganisée aussi souvent que nécessaire, sans que les autres sous-tables le soient.
Le partitionnement horizontal doit cependant être adopté avec prudence, car s'il favorise les requêtes les plus fréquentes ou celles mettant en jeu les plus gros volumes d'informations, il peut au contraire pénaliser fortement d'autres requêtes.
III-D-2-h. Le regroupement de tables ou « clustérisation »▲
Certains SGBD relationnels permettent l'usage de « clusters ». Le rôle de ces clusters est de regrouper physiquement, sur une même page (une entrée/sortie), des données provenant d'une ou plusieurs relations et vérifiant des prédicats de sélection précisés. L'utilisation des clusters est totalement transparente à l'utilisateur.
En général, le regroupement concerne deux tables, afin d'optimiser les jointures sur ces tables, c'est le principal intérêt de la clustérisation. Il est aussi possible de définir des clusters sur une seule table, ce qui permet d'implanter les deux variantes de partitionnement précédemment évoquées [Richard 89].
La clustérisation peut être, dans ses finalités, comparée à des optimisations plus structurelles dénormalisantes, mais elle présente le grand avantage de ne pas modifier la structure logique en se plaçant uniquement au niveau de l'implantation physique des données.
Dans le SGBD Oracle, il faut créer tout d'abord les clusters, puis y placer une ou plusieurs tables. Si plusieurs tables sont regroupées dans un cluster, elles doivent avoir au moins un attribut en commun. Le regroupement des tables dans un cluster a pour conséquences que :
- chaque valeur de cet attribut commun est stockée une fois dans la base ;
- les tuples d'une table ayant la même valeur pour cet attribut sont stockés dans une même zone du disque (page) ;
- SQL*plus crée un index, appelé cluster index, sur les attributs regroupés.
Toujours dans Oracle, il est possible soit de créer une table et de placer sa définition dans un cluster, soit de créer la table et la placer dans un cluster existant. La première façon convient pour créer une table, la seconde pour ajouter une table existante dans le cluster [J.P. Perry et J.G. Lateer]. La syntaxe de la création d'un cluster dans Oracle est la suivante :
CREATE CLUSTER nom_cluster
(attribut_cluster1 type_données, attribut_cluster2 type_données…)
[SIZE taille_logique]
[SPACE nom_zone]
[COMPRESS \ NOCOMPRESS];Il est aussi possible de supprimer des clusters, il faut alors d'abord en extraire les tables.
III-D-3. Optimisation logique ou dénormalisation▲
Rappelons que l'optimisation logique ou dénormalisation consiste à effectuer différentes adaptations du modèle logique de données relationnel dérivé du MCD/MOD, modèle qui est normalisé. Ces adaptations reviennent à dénormaliser ce modèle.
Cette dénormalisation devra être conduite avec une extrême prudence. Nous précisons ici un ensemble de règles générales d'optimisation structurelles du modèle logique relationnel. Ces optimisations structurelles entraînent des dénormalisations dont les conséquences doivent être estimées.
L'utilisation de ces règles garantit le respect des spécifications initiales ; tout autre type de modification, sous couvert d'optimisation, peut entraîner une altération de la sémantique du modèle conceptuel de données. Certes, l'efficacité de ces différentes optimisations dépend du SGBD utilisé ; certaines même ne seront pas toujours possibles sur tel ou tel système.
Pour chacune des règles d'optimisation, nous indiquons les conditions incitant à la pratiquer, les gains espérés et les pertes générées, ainsi que les conséquences secondaires. Le concepteur optimise son modèle par modifications successives de la structure. À chaque pas, il doit évaluer le bien-fondé de son choix.
III-D-3-a. Regroupement de tables relationnelles▲
Ce type d'optimisation a, en partie, déjà été suggéré lors de la dérivation du MLD relationnel à partir du MCD/MOD. Deux tables relationnelles reliées par un lien relationnel un vers un peuvent être regroupées en une même table, afin de réduire des accès, mises à jour ou jointures sur ces deux tables. Cette opération d'optimisation peut dans certains cas conduire à une dénormalisation dont les conséquences devront être estimées. D'une façon générale, deux tables ayant la même clé primaire peuvent être regroupées. La figure 14.5 présente un exemple de regroupement de tables.
 |
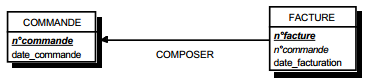 |
 |
D'une façon générale, le regroupement de tables est justifié par de nombreux accès à des tables reliées par des liens relationnels un vers un. La contrepartie est une augmentation du volume à mémoriser pour la table A = ∑ taille des attributs migrés de la table B x Nombre de tuples de la table A accueillant la migration. Une conséquence induite est que si la taille des attributs de B migrant dans A est importante, il peut y avoir augmentation du coût de certaines opérations sur A. Il faut aussi prévoir la gestion des valeurs nulles sur les attributs migrants. La figure 14.6 présente deux exemples de regroupement de tables.
|
Exemple 1 : |
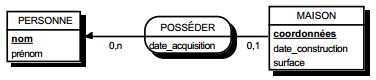 |
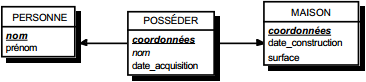 |
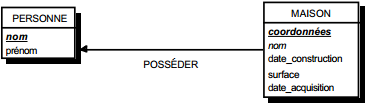 |
|
Exemple 2 : |
 |
 |
 |
III-D-3-b. Création de redondances d'attributs non-clé▲
Lorsque la consultation d'un ou plusieurs attributs d'une table relationnelle A à partir d'une autre table B est importante et génère de nombreux accès ou jointures, il peut être intéressant de dupliquer, sous certaines conditions, ces attributs sollicités dans B. Cela revient à une dénormalisation.
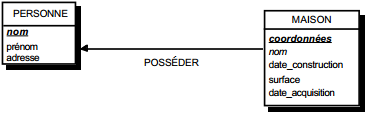 |
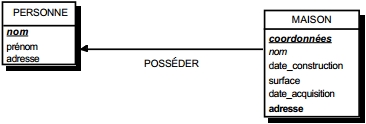 |
Dans l'exemple de la figure 14.7, l'optimisation sera justifiée pour une consultation importante de l'attribut « adresse » à partir de la table Maison. Le prix de la duplication de cet attribut est une augmentation du volume à mémoriser pour la table accueillant la redondance d'attributs = ∑ taille des attributs migrés x nombre de tuples de la table accueillant la duplication. De plus, si la taille des attributs dupliqués est importante, il peut y avoir augmentation du coût de certaines opérations sur la table accueillant la redondance. Il faut aussi prévoir la gestion des valeurs nulles sur les attributs dupliqués et d'une façon générale les conséquences de cette dénormalisation.
III-D-3-c. Ajout de clé étrangère redondante▲
Cette optimisation ne concerne que les liens relationnels un vers un. Lorsque la consultation d'une table relationnelle A à partir d'une autre table B dans laquelle la clé de A est clé étrangère, on peut rajouter dans la table A la clé de B devenant ainsi clé étrangère. Cette opération d'optimisation revient à une dénormalisation dont les conséquences devront être estimées. La contrepartie est une augmentation du volume à mémoriser pour la table accueillant la nouvelle clé étrangère = ∑ taille des attributs de cette clé x nombre de tuples de la table accueillant la migration. Si la taille de la nouvelle clé étrangère est importante, il peut y avoir augmentation du coût de certaines opérations sur la table l'accueillant ; selon les cas, il faudra prévoir la gestion des valeurs nulles sur les attributs dupliqués et d'une façon générale les conséquences de cette dénormalisation. La figure 14.8 présente des exemples d'ajouts de clé étrangère.
 |
 |
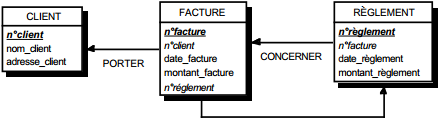 |
III-D-3-d. Création de transitivité▲
Cette optimisation concerne les liens relationnels un vers un comme les liens un vers plusieurs. Considérons la consultation d'une table C à partir d'une autre table A se fait via une table B, sachant qu'un tuple de C n'est en relation qu'avec un tuple de A. On peut alors rajouter dans la table C la clé de A devenant ainsi clé étrangère. Cette opération d'optimisation revient à créer une nouvelle dépendance transitive, donc à une dénormalisation dont les conséquences devront être estimées. La contrepartie est une augmentation du volume à mémoriser pour la table C accueillant la nouvelle clé étrangère = ∑ taille des attributs de cette clé x nombre de tuples de C. De plus, si la taille de la nouvelle clé étrangère est importante, il peut y avoir augmentation du coût de certaines opérations sur la table C ; selon les cas, il faudra prévoir dans C la gestion des valeurs nulles sur les attributs de la clé étrangère et d'une façon générale les conséquences de cette dénormalisation. La figure 14.9 donne un exemple de cette optimisation.
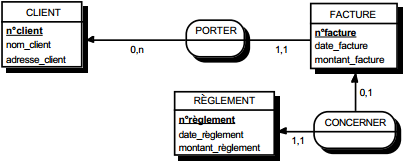 |
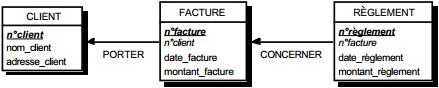 |
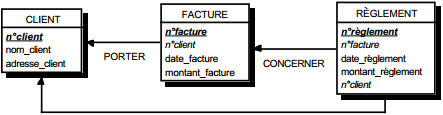 |
III-D-3-e. Création de tables de jointures▲
Cette optimisation a pour objectif d'optimiser le temps de réponse de la base de données par rapport à sa charge de travail. Le principe est simple, il s'agit de réduire le temps d'exécution de requêtes en stockant physiquement les relations résultantes des jointures les plus fréquemment mises en œuvre par ces requêtes.
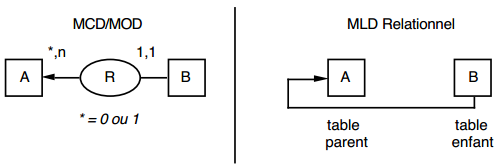
Soient deux tables A et B, A étant la table parent et B la table enfant. Dans le remplacement de la jointure AXB par une table de jointure, on considérera deux cas selon la cardinalité minimale caractérisant le lien entre A et B (notée * dans la figure 14.10).
- cardinalité mini * = 1 (ou >1)
On élimine la table parent A et la table enfant B ; on crée la table de jointure AXB ; les contraintes référentielles entre A et B sont transformées en contraintes de dépendance fonctionnelles sur les attributs de la table de jointure AXB.
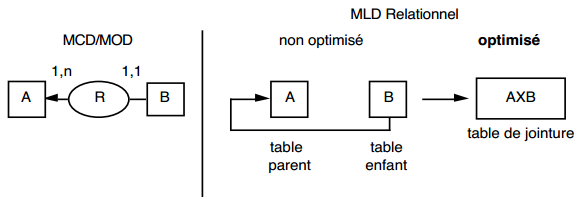
La contrepartie de la réduction du coût des jointures AXB est une augmentation du volume à mémoriser pour la table AXB (plus de redondance) ; table plus grosse, plus lourde à exploiter. Si la taille des attributs dupliqués est importante, il peut y avoir augmentation du coût de certaines opérations sur la table de jointure ; selon les cas, il faudra prévoir d'une façon générale les conséquences de cette dénormalisation (mises à jour sur les attributs de A). L'exemple de la figure 14.12 illustre une telle optimisation :
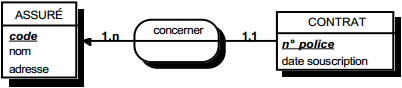 |
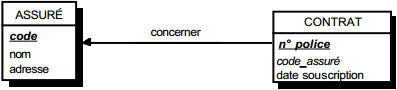 |
 |
Ce cas est très fréquent, surtout lorsque la table parent ne contient qu'une clé primaire.
- cardinalité mini * = 0
La table parent A doit être conservée et la table enfant B éliminée. On crée la table de jointure AXB en éliminant, éventuellement, les attributs non utilisés par les requêtes utilisant cette jointure. On transfère les contraintes référentielles entre A et B dans la table de jointure AXB et on introduit les contraintes sur les dépendances fonctionnelles.
Sur l'exemple de la figure 14.13, la réduction du coût des jointures AXB a pour contrepartie une augmentation du volume à mémoriser pour la table AXB (plus de redondance). De plus, si la taille des attributs dupliqués est importante, il peut y avoir augmentation du coût de certaines opérations sur la table de jointure ; selon les cas, il faudra prévoir d'une façon générale les conséquences de cette dénormalisation (mises à jour sur les attributs de A qui se retrouvent dans A et AXB). On notera qu'il y a disparition de la contrainte référentielle.
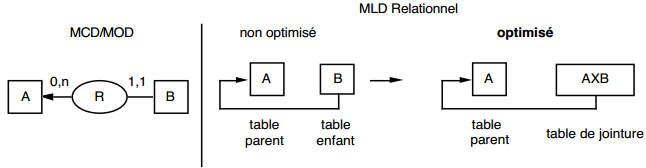
L'exemple de la figure 14.14, semblable à l'exemple précédent, mais avec une cardinalité (0,n), illustre une telle optimisation :
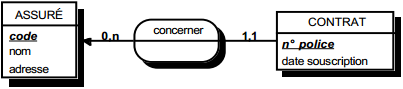 |
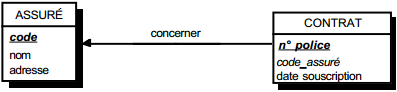 |
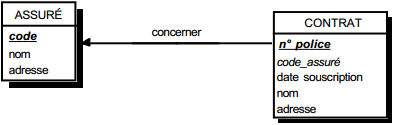 |
III-D-4. Assistance à l'optimiseur de requêtes▲
L'optimisation des requêtes dans le relationnel est un point extrêmement sensible. Cela pour deux raisons principales : la forte indépendance logique/physique et la nature assertionnelle des langages de manipulation de données.
La forte indépendance logique/physique fait que l'utilisateur voit et manipule des tuples et des relations (description logique des informations) sans savoir comment se fait le stockage sur mémoire secondaire (physique).
La nature assertionnelle des langages de manipulation de données permet dans l'expression d'une requête de définir le quoi pas le comment. Cela conduit à un ordre des spécifications indifférent et à de nombreuses formulations possibles pour une même requête.
Il est alors nécessaire à tout SGBD relationnel d'assurer le passage d'une représentation relationnelle à des structures de stockage, de transformer la requête assertionnelle en une séquence d'opérations à effectuer sur les données et enfin de choisir la séquence d'opérations optimale (plan d'exécution optimal). Pour réaliser cela, la plupart des SGBD relationnels possèdent des optimiseurs de requêtes qui ont pour rôle :
- de minimiser les entrées/sorties disques ;
- de minimiser le temps CPU ;
- d'exploiter au maximum les index secondaires (requêtes monotable) ;
- d'établir une stratégie lors de requêtes multitables : choisir un ordre d'un ordre des joints ; choisir comment faire des jointures ; utiliser de façon judicieuse les index secondaires.
Pour cela, les optimiseurs de requêtes utilisent des statistiques sur l'état des tables. Ces informations statistiques sur l'état des tables, les valeurs d'attributs… sont rangées dans une métabase qui sera consultée par l'optimiseur avant optimisation. Le rafraîchissement de ces informations est coûteux et doit parfois être étudié très sérieusement afin d'être pris en compte comme une consigne d'exploitation à part entière. Dans certains SGBD, ce rafraîchissement peut être programmé dans l'applicatif (pouvant être développé en langage de troisième ou de quatrième génération) par le programmeur.